交易型系统设计的一些原则
高并发原则
- 无状态
- 拆分
- 系统维度:根据系统功能/业务进行拆分
- 功能维度:对一个系统进行功能再拆分
- 读写维度:根据读写比例进行拆分
- AOP维度:根据访问特征
- 模块维度:比如按照基础或代码维护特征进行拆分
- 服务化: 进程内服务 -> 单机远程服务 -> 集群手动注册服务 -> 自动注册和发现服务 -> 服务的分组/隔离/路由 -> 服务治理(限流/黑白名单等)
- 消息队列:服务解耦、异步处理、流量削峰/缓冲等
- 消息队列进行多个镜像复制
- 重试功能、防重、(幂等性)
- 失败处理、日志、报警
- 大流量缓冲:一般是牺牲强一致性,而保证最终一致性
- 数据校对:数据校对与修正来保证数据的一致性和完整性
- 数据异构:形成数据闭环,任何依赖系统出问题了,还是能正常工作,只是更新会有积压,但不影响前端展示
- 数据异构: 通过如MQ接受数据变更,然后原子化存储到合适的存储引擎,如Redis等。目的是把数据从多个数据源拿过来
- 数据聚合: 可选的,目的是把这些数据做聚合,前端可以一个调用拿到全部数据,该步骤一般存储在KV存储中
- 前端展示: 前端通过一次或少量调用拿到所需要的数据
- 缓存银弹
- 客户端:
- 使用浏览器缓存: 设置请求过期时间,对应相应头Expires, Cache-control进行控制,适合于实时性不敏感数据
- 客户端应用缓存: 提前将内容发到客户端进行缓存
- 客户端网络: 代理服务器开启缓存
- 广域网:
- 使用代理服务器(含CDN): 一般有两种机制:推送机制(当内容变更后主动推送到CDN边缘节点),拉取机制(先访问边缘节点,当没有内容时,回源到源服务器拿到内容并存储到节点上)。使用CDN需要考虑URL的设计,比如不能有随机数,否则每次都穿透CDN回源到源服务器;对于爬虫,可以返回过期数据而不选择回源
- 使用镜像服务器,使用P2P技术
- 源站及源站网络:
- 使用接入层提供的缓存机制: 对于没CDN缓存的应用来说,可以考虑使用如Nginx搭建一层接入层,可以考虑以下机制:
- URL重写:将URL按照指定的顺序或格式重写,去除随机数
- 一致性哈希: 按照指定的参数做一致性哈希,从而保证相同数据落到一台服务器上
- proxy_cache:使用内存级/SSD级代理缓存来缓存内容
- proxy_cache_lock: 使用Lock机制,将多个回源合并为一个,以减少回源量,并设置相应的Lock超时时间
- shared_dict: 如果架构使用nginx+lux实现,,可考虑使用Lua shared_dict进行cache,最大好处是reload缓存不会丢失
- 对于托底(或兜底,指降级后显示的)数据或异常数据,不应该让其缓存,否则用户会很长一段时间内看到这些数据
- 使用应用层提供的缓存机制: 使用Tomcat时可以使用堆内缓存/堆外缓存;local redis cache在应用所在服务器上部署一组redis,应用直接读取本机Redis数据,多机之间使用主从机制同步数据
- 使用分布式缓存: 数据量太大,使用分片机制将流量分散到多台,或直接使用分布式缓存实现。常见分片机制是一致性哈希
- 静态化/伪静态化,使用服务器操作系统提供的缓存机制
- 使用接入层提供的缓存机制: 对于没CDN缓存的应用来说,可以考虑使用如Nginx搭建一层接入层,可以考虑以下机制:
- 客户端:
- 并发化
- 方式
- 应用级缓存: 缓存回收策略(空间/容量/时间),缓存回收算法(FIFO/LRU/LFU),java堆/java堆外/磁盘缓存,Guava/Ehcache/MapDB,缓存使用模式(Cache-Asize/Cache-As-SoR/Copy Pattern)
- HTTP缓存: 浏览器缓存,HttpClient客户端缓存,nginx代理层缓存
- 多级缓存: 分布式缓存,热点数据与更新缓存,更新缓存与原子性,缓存崩溃与快速修复
- 池化: 数据库连接池,FttpClient连接池,线程池
- 异步并发: 同步阻塞调用,异步Future,异步CallBack,异步编排CompletableFuture,请求缓存,请求合并
- 扩容: 单体应用垂直扩容,单体应用水平扩容,应用拆分,数据库拆分(水平/垂直),使用sharding-jdbc分库分表/读写分离,数据异构,任务系统扩容(Elastic-Job)
- 队列: 异步处理/系统解耦/数据同步/流量削峰,缓冲队列/任务队列/消息队列/请求队列/数据总线队列,Disruptor+Redis队列,基于Canal实现数据异构
高可用原则
- 负载均衡: 负载均衡算法、失败重试机制、健康检查机制、动态负载均衡
- 降级
- 开关集中化管理: 通过推送机制把开关推送到各个应用
- 可降级的多级读服务: 比如服务调用降级为只读本地缓存、只读分布式缓存、只读默认降级数据
- 开关前置化: 如架构师nginx+tomcat,将开关前置到nginx接入层,请求流量不回源后端tomcat或只小部分流量回源
- 业务降级
- 降级预案、自动降级/开关降级、读服务/写服务降级、多级降级、配置中心、使用Hystrix降级、使用Hystrix熔断
- 限流:
- 恶意请求流量只访问到cache
- 对于穿透到后端的流量可以考虑使用nginx的limit模块处理
- 对于恶意IP可以使用nginx deny进行屏蔽
- 限流算法、应用级限流、分布式限流、接入层限流
- 隔离: 进程线程隔离、集群/机房隔离、读写隔离、动静隔离、爬虫/热点隔离、使用Hystrix隔离、基于Servlet3的请求隔离
- 超时与重试: 代理层超时与重试、Web容器超时、中间件客户端超时与重试、数据库客户端超时、NOSQL客户端超时、业务超时、前端AJAX超时
- 切流量:
- DNS: 切换机房入口
- HttpDNS: 主要APP场景下,在客户端分配好流量入口,绕过运营商LocalDNS并实现更精准流量调度
- LVS/HaProxy: 切换故障的nginx接入层
- Nginx: 切换故障的应用层
- 可回滚: 版本化的目的是实现可审计可追溯,并且可回滚。如果程序或数据出错时,如果有版本化机制,那就可以通过回滚恢复到最近一个正确的版本,比如事务回滚、代码库回滚、部署版本回滚、数据版本回滚、静态资源版本回滚等。
- 压测与预案: 系统压测、系统优化与容灾、应急预案、
- 监控报警: 服务器/系统/JVM/接口监控、监控时间段、报警阀值、通知方式
业务设计原则
- 防重设计: 防重key、防重表
- 幂等设计
- 流程可定义: 关联、可复用流程,个性化流程
- 状态与状态机
- 比如订单交易,会有正向状态(待付款/待发货/已发货/完成)与逆向状态(取消/退款),正向状态与逆向状态根据系统特征决定要不要分离存储。状态设计时应有状态轨迹,方便跟踪订单轨迹并记录相关日志,万一出问题时可回溯问题。
- 比如订单状态的变迁(待支付->待发货->已发货->完成)。要考虑要不要使用状态机来驱动状态的变更和后续流程节点操作,尤其当状态很多的时候使用状态机能更好地控制状态迁移
- 考虑并发状态修改问题: 一个订单同时只能有一个修改、状态变更的有序性、时间差
- 后台系统操作可反馈
- 后台系统审计化
- 文档和注释
- 备份
负载均衡与反向代理
四层负载均衡: 首先DNS解析到LVS/F5,然后LVS/F5转发给Nginx,再由Nginx转发给后端Real Server
两层负载均衡是通过改写报文的目标MAC地址为上游服务器MAC地址,源IP和目标IP地址是没有改变的,负载均衡服务器和真实服务器共享同一个VIP,如LVS DR工作模式。
四层负载均衡是根据端口将报文转发到上游服务器(不同的IP地址+端口),如LVS NAT模式、HaProxy。
七层负载均衡是根据端口号和应用层协议如HTTP协议的主机名、URL,转发报文到上游服务器(不同的IP地址+端口),如HaProxy、Nginx
- 上游服务器配置: 使用upstream server配置上游服务器
- IP地址和端口
- 权重
- 负载均衡算法:
- round-robin轮循
- ip_hash
- hash key [consistent]: 对某一key进行哈希或使用一致性哈希算法
- 哈希算法: 根据请求uri进行负载均衡,可以使用nginx变量
- least_conn
- 失败重试机制: 配置当超时或上游服务器不存活时,是否需要重试其他上游服务器
- 服务器心跳检查
- TCP心跳检查
- HTTP心跳检查
隔离
- 线程隔离: 主要是指线程池隔离,实际使用时,会把请求分类,然后交给不同的线程池处理。当一种业务的请求处理发生问题时,不会将故障扩散到其他线程池,从而保证其他服务可用。
- 进程隔离: 过渡方案,较好的解决方案是将系统拆分为多个子系统来实现物理隔离
- 集群隔离
- 机房隔离
- 读写隔离: 通过主从模式将读和写集群分离
- 动静隔离: 动态内容和静态内容隔离,一般应将静态资源放在CDN上
- 爬虫隔离: 一种方法通过限流解决;另一种方法是在负载均衡层面将爬虫路由到单独集群,从而保证正常流量可用,爬虫流量尽量可用
- 热点隔离: 秒杀、抢购。读热点可用多级缓存,写热点可用缓存+队列模式削峰
- 资源隔离
- 其他:
- 环境隔离: 测试环境、预发布环境/灰度环境、正式环境
- 压测隔离: 真实数据、压测数据
- AB测试: 不同用户提供不同版本的服务
- 查询隔离: 简单、批量、复杂条件查询分别路由到不同的集群
Hystrix
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
servlet3异步化模型:
- 请求解析和业务处理线程池分离
- 业务线程池隔离
- 业务线程池监控/运维/降级
限流
- 限流算法: 令牌桶算法、漏桶算法
- 应用级限流:
- 限流总并发/连接/请求数
- 限制总资源数
- 限流某个接口的总并发/请求数
- 限流某个接口的时间窗请求数: Guava
- 平滑限流某个接口的请求数: Guava RateLimiter
- 分布式限流: redis+lua、 nginx+lua
- 接入层线路: 该层通常指请求流量的入口,主要目的为负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等
- 节流: throttleFirst、throttleLast、throttleWithTimeout
降级
超时与重试机制
回滚机制
事务回滚: 事务表、消息队列、补偿机制(执行/回滚)、TCC模式(预占/确认/取消)、Sagas模式(拆分事务+补偿机制)实现最终一致性
压测与预案
应用级缓存
缓存回收策略:
- 基于空间: 到达存储上限后按策略移除数据
- 基于容量: 设置最大大小,当缓存条数超过时,按策略移除
- 基于时间: TTL存活期、TTI空闲期
- 基于Java对象引用: 软引用(适合做缓存,从而当JVM堆内存不足时也可以回收这些对象)、弱引用(相当于软引用,更短的生命周期)
- 回收算法: FIFO先进先出、LRU最少使用、LFU最不常用
堆缓存(Gauva Cache, Ehcache 3.x)、堆外缓存(Ehcache 3.x, MapDB 3.X)、磁盘缓存(Ehcache 3.x, MapDB 3.X)、分布式缓存(Redis, Ehcache 3.x + Terracotta server)、多级缓存
缓存使用模板
- 三个名词:
- SoR: 记录系统,或者叫数据源
- Cache: 缓存,是SoR的快照数据
- 回源: 即回到数据源头获取数据
- Cache-Aside: 即业务代码围绕Cache写,是由业务代码直接维护缓存。适合用AOP模式去实现。
- Cache-As-SoR: 即把Cache看做SoR, 所有操作都是对Cache进行,然后Cache再委托给SoR进行真实的读/写。即代码中只能看到Cache的操作,看不到关于SoR相关的代码。 - Read-Through: 业务代码首先调用Cache,如果Cache不命中,由Cache回源到SoR,而不是业务代码。使用Read-Through模式,需要配置一个CacheLoader组件用来回源到SoR加载数据 - Write-Through: 被称为穿透写/直写模式 ———— 业务代码首先调用Cache写数据,然后由Cache负责写缓存和写SoR,而不是业务代码。需要配置一个CacheLoaderWriter - Write-Behind: 称之为回写模式,不同于Write-Through是同步写SoR与Cache,Write-Behind是异步写。异步之后可以实现批量写、合并写、延时和限流
- Copy Pattern
- Copy-On-Read在读时复制
- Copy-On-Write在写时复制
HTTP缓存
HTTP缓存:
- 服务器端响应Last-Modified会在下次请求时,将If-Modified-Since请求头带到服务器端进行文档是否修改的验证,如果没有修改则返回304,浏览器可以直接使用缓存内容
- Cache-Control:max-age和Expires用于决定浏览器端内容缓存多久,即多久过期。过期后则删除缓存重新从服务器端获取最新的。另外可以用于from cache 场景
- HTTP/1.1规范定义的Cache-Control优先级高于HTTP/1.0定义的Expires
- HTTP/1.1规范定义ETag为“被请求变量的实体值”,可简单理解为文档内容摘要,ETag可用来判断页面内容是否已经被修改过了
HttpClient客户端缓存:
- maxCacheEntries
- maxObjectSize
- asynchronousWorkersCore/asynchronousWorkersMax/revalidationQueueSize
Nginx HTTP缓存设置:
- expires
- if-modified-since
- nginx proxy_pass
- Nginx代理层缓存:
- HTTP模块配置
- proxy_cache配置
多级缓存
应用Nginx本地缓存、分布式缓存、Tomcat堆缓存
如何缓存数据:
- 过期与不过期:
- 不过期缓存场景一般思路Cache-Aside模式,1.开启事务 2.执行SQL 3.提交事务 4.写缓存
- 过期缓存机制,如懒加载,一般用于缓存其他系统的数据、缓存空间有限、低频热点缓存等场景
- 维度化缓存与增量缓存: 只更新变的部分
- 大Value缓存: 多线程实现缓存、对Value压缩、拆分Value为多个小Value
- 热点缓存: 挂更多的从缓存,通过负载均衡机制读取;客户端所在应用/代理层本地存储一份
- 单机全量缓存+主从
- 分布式缓存+应用本地缓存
更新缓存与原子性:
- 更新数据时使用更新时间戳或版本对比,如果使用Redis,则可以使用其单线程机制进行原子化更新
- 使用如canal订阅数据库binlog
- 将更新请求按照相应的规则分散到多个队列,然后每个队列进行单线程更新,更新时拉取最新的数据保存
- 用分布式锁,在更新之前获取相关的锁
连接池/线程池
- 数据库连接池: C3P0、DBCP、Druid等
- HttpClient连接池
- 线程池:
- 提供ExecutorService三种实现:
- ThreadPoolExecutor: 标准线程池
- ScheduledThreadPoolExecutor: 支持延迟任务的线程池
- ForkJoinPool: 类似于ThreadPoolExecutor,但使用work-stealing模式,会为线程池中每个线程创建一个队列,从而用work-stealing(任务窃取)算法使得线程可以从其他线程队列里窃取任务来执行。
- Executors创建简单线程池
- 根据任务列型是IO密集型还是CPU密集型、CPU核数,来设置合理的线程池大小、队列大小、拒绝策略,并进行压测和不断调优来决定适合自己场景的参数
- 提供ExecutorService三种实现:
- Tomcat线程池
异步并发
异步Web服务实现:
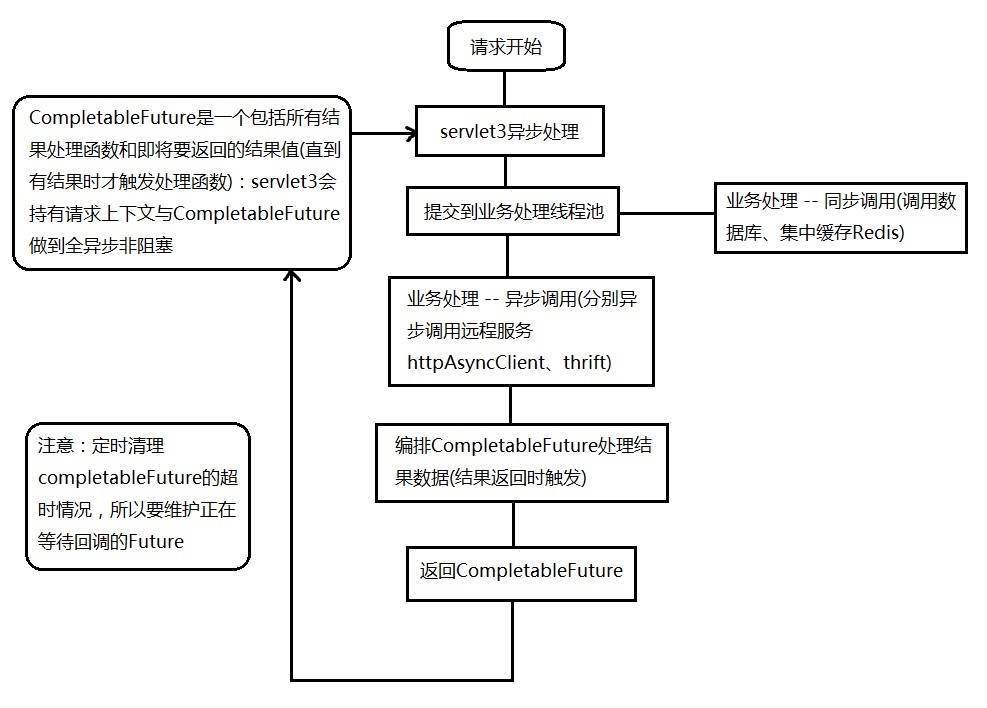
如何扩容
队列
案例
OpenResty