Redis(一) 基础与api
Redis(二) 小功能
Redis(三) 阻塞与内存
Redis(四) 缓存设计
Redis(五) 客户端调用
Redis(六) 持久化与复制
Redis(七) 哨兵
Redis(八) 集群
缓存设计
缓存的收益和成本
在缓存层 + 存储层结构中,加入缓存后带来的收益和成本:
收益:
1、加速读写:因为缓存是内存的,比存储层读写性能好,所以可以加速读写,优化用户体验
2、降低后端负载:帮助后端减少访问量和复杂计算(例如复杂SQL语句),在很大程度降低了后端的负载
成本:
1、数据不一致性:缓存层和存储层的数据存在一定时间窗口的不一致性,时间窗口和更新策略有关
2、代码维护成本:加入缓存层后,需要同时处理缓存层和存储层的逻辑
3、运维成本:以Redis Cluster为例,加入后增加运维成本
缓存使用场景:
1、开销大的复杂计算:MYSQL对一些复杂操作或计算(大量联表操作,一些分组计算等),如果不加缓存,不但无法满足高并发量,同时也会给MYSQL带来巨大负担
2、加速请求响应:即使查询单条后端数据够快,也可以使用redis优化整个IO链的响应时间
缓存更新策略
LRU/LFU/FIFO算法剔除
使用场景:剔除算法通常用于缓存使用量超过预设的最大值的时候,如何对现有数据进行剔除。例如使用maxmemory-policy这个配置作为剔除策略
一致性:要清理哪些数据由算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的
维护成本:不需要实现,但需要知道每种算法的含义选择合适的算法
超时剔除
使用场景:通过给缓存数据设置过期时间,让其过期后自动删除,例如使用expire命令。如果缓存层数据和存储层数据可以忍受一定时间内不同,可以设置过期时间,数据过期后再从真实数据源获取数据,并重新设置过期时间
一致性:一定时间窗口(过期时间)内,存在数据一致性问题
维护成本:只需要维护expire过期时间就可以了
主动更新
使用场景:应用对数据一致性要求很高,需要真实数据更新后,立即更新缓存数据。例如可以利用消息系统或其他方式通知缓存更新
一致性:一致性最高,但如果主动更新发生了问题,那么这条数据可能很长时间不会更新,所以结合超时剔除效果更好
维护成本:比较高,需要自己完成更新并保证更新操作的正确性
Cache Aside Pattern
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中
命中:应用程序从cache中取数据,取到后返回
更新:先把数据存到数据库中,成功后,再让缓存失效
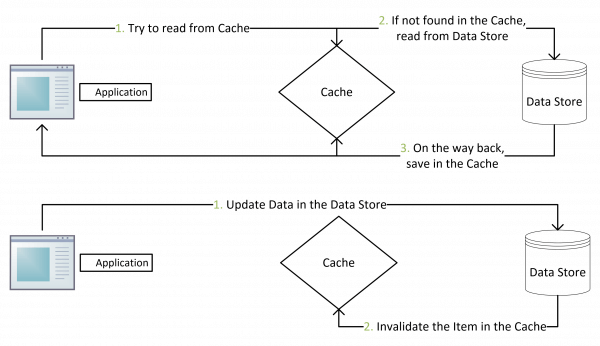
为什么不是写完数据库后更新缓存?主要是怕两个并发的写操作导致脏数据
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个读操作没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以也会造成脏数据。
不过实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大
所以要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率。而Facebook使用了这个降低概率的方案,因为2PC太慢,而Paxos太复杂
Read/Write Through Pattern
在上面的Cache Aside方案中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through方案是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache
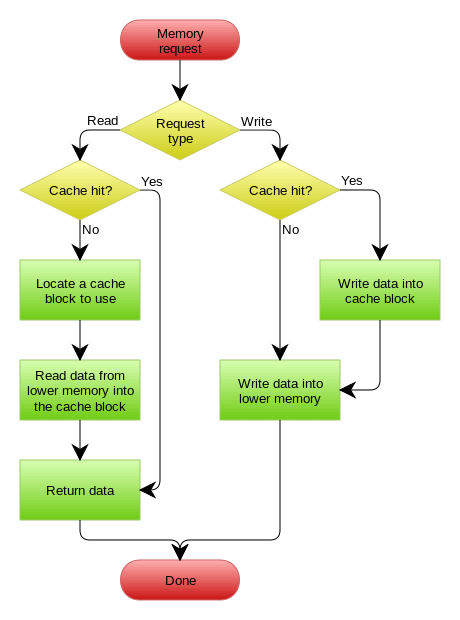
Read Through
Read Through 就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的
Write Through
Write Through 和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
下图自来Wikipedia的Cache词条。其中的Memory可以理解为就是数据库
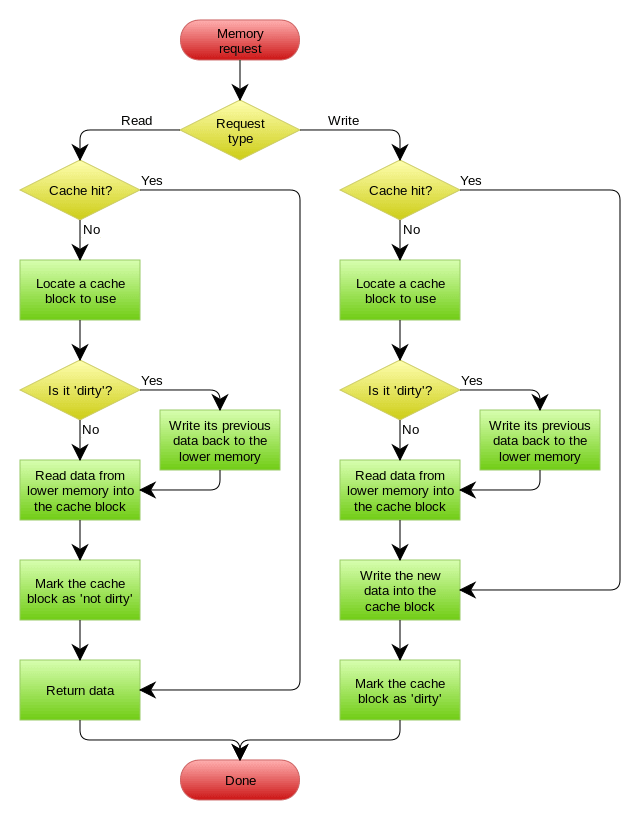
Write Behind Caching Pattern
Write Behind 又叫 Write Back。一些了解Linux操作系统内核的对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,基础这玩意全都是相通的
Write Back一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write back还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write
缓存的粒度控制
通用性:缓存全部数据比部分数据更加通用,但从实际经验看,很长时间内应用只需要几个重要的属性
空间占用:缓存全部数据比部分数据占用更多的空间,可能存在下面问题。1全部数据会造成资源浪费;2全部数据可能每次传输产生的网络流量比较大,耗时比较长,在极端情况下会阻塞网络;3全部数据的序列化和反序列化的CPU开销更大
代码维护:全部数据优势更为明显,而部分数据一旦要加新字段需要修改业务代码,修改后还通常需要刷新缓存数据
穿透优化
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常处于容错考虑,如果从存储层查不到数据则不写入缓存层。缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义
缓存穿透问题可能使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕机。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就出现了缓存穿透问题
造成缓存穿透一般原因有两个。第一,自身业务代码或数据出现问题。第二,一些恶意攻击、爬虫造成大量空命中
缓存空对象
在存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据就会从缓存中获取
但是缓存空对象会有两个问题。第一,空值做了缓存,就会存在更多键和更多内存空间,比较有效的方法是对这类数据设一个较短的过期时间。第二,缓存层和存储层数据会有一段时间窗口的不一致,可能对业务造成影响,此时可通过消息或其他方式清除缓存中的空对象
布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截
这种方法适用于数据命中不高,数据相对固定,实时性低(通常是数据集较大)的应用场景,代码维护较复杂,但是缓存空占用少
无底洞优化
键值数据库由于通常采用哈希函数将key映射到各个节点上,造成key分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上,所以无论是memcache还是redis的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间
更多的节点不代表更高的性能:
1、客户端一次批量操作会涉及多次网络操作,意味着批量操作随着节点的增多,耗时会不断增大
2、网络连接数变多,对节点的性能也有一定影响
常见IO优化思路:
1、命令本身的优化,例如优化SQL语句等
2、减少网络通信次数
3、降低接入成本,例如客户端使用长连/连接池、NIO等
假设命令与客户端连接已为最优,那么需要对网络通信进行优化:
1、串行命令:逐次进行n个get命令,这种操作复杂度最高,但是实现起来比较简单
2、串行IO:利用slot和节点的关系,可以将属于同一个节点的key进行归档,得到每个节点的key子列表,之后对每个节点执行mget或者pipline操作,明显比串行命令要好,但是如果节点数太多,还是有一定性能问题
3、并行IO:将串行IO最后的查询改为多线程执行,网络次数虽然还是节点个数,但使用多线程使网络时间变为O(1)
4、hash_tag实现:hash_tag功能可以将多个key强制分配到一个节点上
雪崩优化
由于缓存层承载大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有请求都会到达存储层,存储层的调用量会暴增,造成存储层也宕机的情况
预防和解决方法:
1、保证缓存服务的高可用性。Redis Sentinel和Redis Cluster都实现了高可用
2、依赖隔离组件为后端限流并降级。降级,且对重要资源(redis,mysql,hbase,外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现问题也不影响其他服务。Hystrix是解决依赖隔离的利器
3、提前演练。演练缓存宕掉后,应用及后端的负载情况以及可能出现的问题,做一些预案
热点key重建优化
“缓存 + 过期时间”策略既可以加速数据读写,又保证数据的定期更新,能满足绝大多数需求。但有两个问题如果同时出现,会对应用造成致命伤害:
1、当前key是一个热点key,并发量非常大
2、重建缓存不能在短时间完成,可能使一个复杂运算,例如复杂SQL,多次IO,多个依赖等
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载过大,甚至可能让整个应用崩溃
所以需要制定如下目标:
1、减少重建缓存的次数
2、数据尽可能一致
3、较少的潜在危险
互斥锁
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。但是如果构建缓存过程出现问题或者时间过长,可能会存在死锁和线程阻塞的风险,但能有效减低后端存储负载,并在一致性上做得比较好
永不过期
包含两层意思:
1、从缓存层面上看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是”物理”不过期
2、从功能层面上看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去重建缓存
此方法有效杜绝了热点key产生的问题,但唯一不足之处就是重建缓存期间,会出现数据不一致的情况
参考:
缓存更新的套路