全文检索
全文检索简单讲就是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程
数据总体分为两种:
1、结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等
1.1、结构化数据一般可以通过存放在数据库实现搜索,使用sql语句进行查询
2、非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
2.1、可以使用顺序扫描法,从头到尾扫描全部数据直到结束,查看是否有要找的内容,速度会相当慢
2.2、将非结构化数据中的信息提取出来,重新组织使其变得有一定结构,然后对此进行搜索,就像使用字典的拼音表和部首表一样查找非结构化的每一个字。像这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)
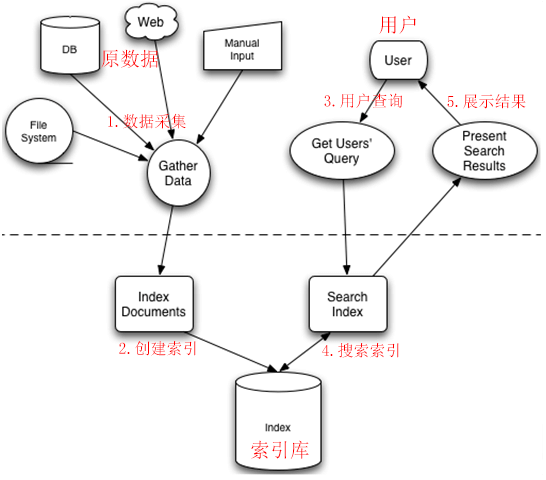 全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search),于是全文检索就存在三个重要问题:
全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search),于是全文检索就存在三个重要问题:
1、索引里面究竟存些什么?(Index)
2、如何创建索引?(Indexing)
3、如何对索引进行搜索?(Search)
索引存些什么?
为什么顺序扫描的速度慢?是由于要搜索的信息和非结构化数据中所存储的信息不一致造成的。已知文件搜索需要的数据相对容易,也就是文件到字符串的映射,而我们搜索的信息是哪些文件包含的,从字符串到文件的映射就困难很多
反向索引:如果索引能够保存从字符串到文件的映射,那就大大提高了搜索速度。由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引
反向索引保存的信息(词典-倒排表)
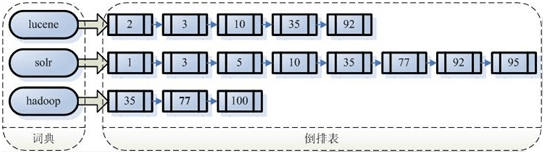 反向索引的优缺点:
反向索引的优缺点:
1、优点:顺序扫描是每次都要扫描,而全文索引可一次索引,多次使用,检索速度快
2、缺点:加上新建索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程
如何创建索引?
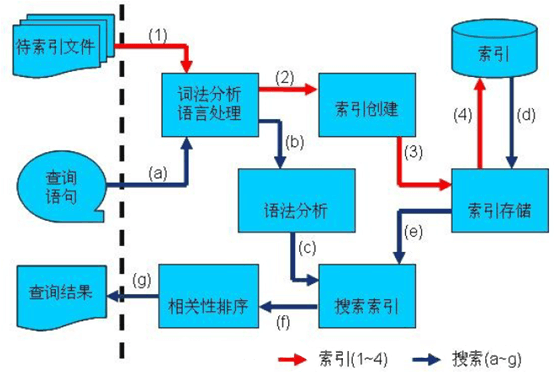
全文检索的索引创建过程一般有以下几步:
1、将原文档(Document)传给分词组件(Tokenizer),分词组件进行Tokenize:将文档拆分成一个个单独的单词,去除标点符号,去除停用词。经过分词后得到的结果称为词次(Token)
2、将词次(Token)传给语言处理组件(Linguistic Processor),语言处理组件主要是对得到的词次做一些同语言相关的处理,比如大写变小写,不同形式的变为词根。经过语言处理后得到的结果称为词元(Term)
3、将词元(Term)传给索引组件(Indexer),将得到的词元创建一个词典(Term-DocumentID),对字典按字母顺序进行排序,合并相同的词元成为文档倒排链表(Posting Lists)。该表中含有文档频次(Document Frequency):表示总共有多少文件包含此词元;词频率(Frequency):表示此文件中包含了几个此词元
4、通过索引存储将索引写入硬盘文件
如何对索引进行搜索?
通过倒排链表,可以找到包含各个查询字符串的文档,合并链表后根据相关性排序,最后返回结果
 1、用户输入查询语句(包含语法:AND/OR/NOT),对查询语句进行词法分析、语法分析(根据查询到的单词与关键词形成语法树)及语言处理(将不同形式的单词转换为词根)
1、用户输入查询语句(包含语法:AND/OR/NOT),对查询语句进行词法分析、语法分析(根据查询到的单词与关键词形成语法树)及语言处理(将不同形式的单词转换为词根)
2、通过索引存储将索引读入到内存,利用查询树搜索索引,从而得到每个词元(Term)的文档链表,对文档链表进行交、差、并得到结果文档
3、对符合条件的文档,根据相关性进行排序
3.1、计算相关性:对相关性进行打分,分数越高越靠前。这里需要找到哪些词对文档的关系最重要(关键词),再判断两个文档间关键词的相似度。找到词对于文档的重要性就是计算词的权重。词的权重表示词再文档中的重要程度,权重越大的单词在计算文档的相关性中作用越大
3.2、根据词的权重来进行结果排序:运用向量空间模型算法(VSM)通过词之间的关系得到文档相关性
4、将查询结果返回给用户
Lucene
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎,是一套用于全文检索和搜寻的成熟的免费开源工具
Lucene作为一个全文检索引擎,其具有如下突出的优点:
1、索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件
2、在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的
3、优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能
4、设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口
5、已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等
Apache Lucene 7.7.0 Documentation
Demo
1、首先引入maven:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.7.0</version>
</dependency>
<!--<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.7.0</version>
</dependency>-->
2、创建索引
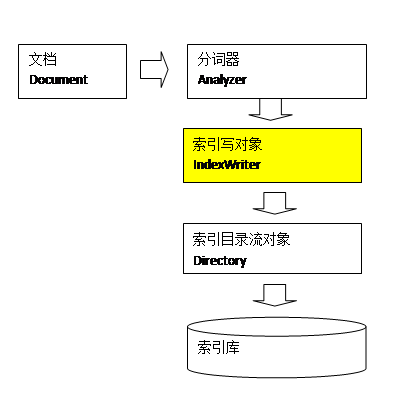 IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作:
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作:
public void createIndex() throws IOException {
// 获取原文档数据,比如File、mysql等
List<MyData> myDataList = getData();
// 1.将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
for (MyData data : myDataList) {
// 创建document对象
Document document = new Document();
// Field类型,不同子类存储类型不同,且:是否分词、索引、存储
Field id = new StringField("id", data.getId().toString(), Field.Store.YES);
Field title = new TextField("title", data.getTitle(), Field.Store.YES);
Field author = new TextField("author", data.getAuthor(), Field.Store.YES);
Field price = new StoredField("price", data.getPrice().toString());
Field num = new StoredField("num", data.getNum().toString());
Field imagePath = new StoredField("imagePath", data.getImagePath());
Field status = new StoredField("status", data.getStatus().toString());
// 将field域设置到Document对象中
document.add(id);
document.add(title);
document.add(author);
document.add(price);
document.add(num);
document.add(imagePath);
document.add(status);
docList.add(document);
}
// 2.指定一个标准分析器,主要有分词和过滤两个步骤:
// 将field域中的内容一个个的分词;将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原、停用词过滤
Analyzer analyzer = new StandardAnalyzer();
// 3.创建IndexWriterConfig对象
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 4.指定索引库的存放位置Directory对象
Path path = Paths.get("indexDB"); // 项目相对路径
Directory directory = FSDirectory.open(path);
// 5.创建IndexWriter对象(核心)
IndexWriter indexWriter = new IndexWriter(directory, config);
// 可以使用IndexWriter来更新和删除索引
// 修改时如果根据查询条件可以查出结果,则将其删掉覆盖新的doc;否则直接新增一个doc
// indexWriter.updateDocument(new Term("author", "jack"), newDocument);
// Term是索引域中最小的单位。根据条件删除时,建议根据唯一键来进行删除。在solr中就是根据ID来进行删除和修改操作的
// indexWriter.deleteDocuments(new Term("id", "23333"));
// 通过IndexWriter对象将Document写入到索引库中,此过程进行索引创建,并将索引和document对象写入索引库
for (Document document : docList) {
indexWriter.addDocument(document);
}
// 关闭indexWriter
indexWriter.close();
}
3、构造查询对象进行搜索:
public void searchIndex() throws Exception {
// 1.创建QueryParser对象,默认搜索title,需要指定分词器,搜索时的分词器要和索引时的分词器一致
QueryParser parser = new QueryParser("title", new StandardAnalyzer());
// 2.创建Query对象,输入的lucene的查询语句(关键字要大写)
Query query = parser.parse("lucene AND solr");
// 3.指定索引库的存放位置Directory对象
Path indexPath = Paths.get("indexDB");
Directory directory = FSDirectory.open(indexPath);
// 4.创建IndexReader对象
IndexReader reader = DirectoryReader.open(directory);
// 5.创建IndexSearcher对象(核心)
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 6.通过IndexSearcher的searcher方法来搜索索引库,返回顶部10条结果集
TopDocs topDocs = indexSearcher.search(query, 10);
// 顶部匹配记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc;
// 7.通过ID获取文档
Document doc = indexSearcher.doc(docId);
System.out.println(doc.get("id"));
System.out.println(doc.get("title"));
System.out.println(doc.get("price"));
System.out.println(doc.get("num"));
System.out.println(scoreDoc.score);
System.out.println("=================");
}
// 关闭资源
reader.close();
}
总结步骤:
1、创建文档对象:在索引前需要将原始内容创建成文档(Document),文档中包括一个个的域(Field),域中存储内容。其中每个文档都有一个唯一的编号,即文档id,Document可以有多个Field,不同Document可以有不同的Field,同一个Document也可以有相同的Field
2、分析文档:将文档中域的内容进行分析,分析的过程经过分词、过滤处理(转小写、去标点、去停用词等)等过程生成最终的词元(Term)。其中不同的域中拆分出来的相同的单词是不同的Term,同一个域中拆分出来的相同的单词是同一个Term。Term中包含两部分内容,文档的域名和单词的内容
3、创建索引:对所有文档分析得出的词元进行索引,生成词典和倒排表并存储,实现可以通过词元找到Document
4、创建查询:将查询关键字构建成一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法。比如”title:lucene AND solr”
5、根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。索引域是用于搜索的,搜索程序将从索引域中搜索一个个词,然后根据词找到对应的文档,然后根据相关性评分排序
6、从结果集中获取文档,返回结果
Field域
Field类:
public class Field implements IndexableField {
// Field's type 类型
protected final IndexableFieldType type;
// Field's name 名称
protected final String name;
// Field's value 值
protected Object fieldsData;
// Pre-analyzed tokenStream for indexed fields 定义fieldsData怎么分词
protected TokenStream tokenStream;
}
那么先看一下创建的TextField:
public final class TextField extends Field {
/** Indexed, tokenized, not stored. */
public static final FieldType TYPE_NOT_STORED = new FieldType();
/** Indexed, tokenized, stored. */
public static final FieldType TYPE_STORED = new FieldType();
static {
TYPE_NOT_STORED.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
TYPE_NOT_STORED.setTokenized(true);
TYPE_NOT_STORED.freeze(); // 冻结
TYPE_STORED.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS);
TYPE_STORED.setTokenized(true);
TYPE_STORED.setStored(true); // 存储
TYPE_STORED.freeze(); // 冻结
}
public TextField(String name, String value, Store store) {
super(name, value, store == Store.YES ? TYPE_STORED : TYPE_NOT_STORED);
}
}
会发现Field的类型需要:
1、indexOptions:是否索引,将分好的词进行索引,索引的目的就是为了搜索,如果不索引,那就不对该field域进行搜索
2、tokenized:是否分词,决定是否对该field存储的内容进行分词,如果不分词不代表不索引,只是对整个内容进行索引
3、stored:是否存储,将Field域中的内容存储到文档域中,只是为了搜索页面显示取值用的,如果不需要取值展示,可以只进行分词、索引
像之前的Demo中对图片路径用了StoredField,因为只需要展示不需要被搜索,下面看下常用的几种类型:
1、TextField:分词、索引、可以设置是否存储
2、StoredField:不分词、不索引,只是用来存储
3、StringField:不分词、索引、可以设置是否存储
4、IntPoint/DoublePoint/LongPoint:不存储,不排序,不支持加权,如果存储需要用StoredField写相同的字段,排序使用NumericDocValuesField写相同的排序
Query
Query是一个抽象类,lucene提供了许多子类,常用的有:TermQuery、TermRangeQuery、BooleanQuery等,这种方式不能输入lucene的查询语法,所以不需要指定分词器:
1、TermQuery:精确的词项查询:new TermQuery(new Term("id", "23333"));
2、TermRangeQuery:范围查询:new TermRangeQuery("id", new BytesRef("12222"), new BytesRef("23333"), true, true);
3、BooleanQuery:组合查询:
Query query1 = new TermQuery(new Term("title", "lucene"));
Query query2 = new TermQuery(new Term("author", "jack"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
// MUST和MUST表示“与”;MUST和MUST_NOT前包后不包;SHOULD与MUST表示MUST,SHOUlD与MUST_NOT相当于MUST与MUST_NOT,SHOULD与SHOULD表示“或”
builder.add(query1, BooleanClause.Occur.MUST);
builder.add(query2, BooleanClause.Occur.SHOULD);
BooleanQuery query = builder.build();
Query子类还有非常多,还有比如PointRangeQuery、MatchAllDocsQuery、PrefixQuery、FuzzyQuery、WildcardQuery等。另外可以通过QueryParser来创建查询对象,比如QueryParser、MultiFieldQueryParser等,可以输入lucene的查询语法、可以指定分词器
查询结果按相关度排序,Lucene会根据词计算词的权重,然后根据词的权重进行打分。词的权重意味着对一个文档的重要性,影响权重的方式有两种:
1、Tf(词元Term在同一个文档中出现的频率) —— Tf越高,说明词的权重越高
2、Df(词元Term在多个文档中出现的频率) —— Df越高,说明词的权重越低
上面是自然打分规则,Lucene可以通过设置Boost值来进行手动调整。在创建索引时加权值在6.6版本后就已经废除了,不顾可以在查询时设置加权值
Query query1 = new TermQuery(new Term("title", "lucene"));
Query query2 = new TermQuery(new Term("author", "jack"));
// 利用BoostQuery包装Query
BoostQuery highQuery1 = new BoostQuery(query1, 100f);
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(highQuery1, BooleanClause.Occur.MUST);
builder.add(query2, BooleanClause.Occur.MUST);
BooleanQuery query = builder.build();
String[] fields = {"title", "auther"};
Map<String, Float> boosts = new HashMap<>();
boosts.put("title", 100f);
// 利用MultiFieldQueryParser构造函数传参
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer(), boosts);
Query query = parser.parse("java");
另外还可以对结果进行查询排序:
Sort sort = new Sort();
// true表示降序
SortField f1 = new SortField("author", SortField.Type.STRING, true);
SortField f2 = new SortField("num", SortField.Type.INT, false);
sort.setSort(new SortField[]{f1, f2});
TopDocs topDocs = indexSearcher.search(query, 10, sort);
还可以进行高亮,需要再引入highlighter包
分词器
1、org.apache.lucene.analysis.Analyzer:
分析器,分词器组件的核心API,它是一个抽象类,使用装饰器模式方便扩展,它通过tokenStream()方法构建真正对文本进行分词处理的TokenStream(分词处理器)
public final TokenStream tokenStream(final String fieldName, final Reader reader) {
// 分词处理的组件,封装有供外部使用的TokenStream分词处理器。提供了对source(源)和sink(供外部使用分词处理器)两个属性的访问方法
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
final Reader r = initReader(fieldName, reader);
if (components == null) {
// Analizer中唯一的抽象方法,扩展点,通过提供该方法的实现可以实现自己的Analyzer
// fieldName:如果我们需要为不同的字段创建不同的分词处理器组件,则可根据这个参数来判断,否则就用不到这个参数
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
// 最终给了Tokenizer(sink)的inputPending (source.setReader(reader))
components.setReader(r);
// 返回sink
return components.getTokenStream();
}
// Tokenizer extends TokenStream
public TokenStreamComponents(final Tokenizer source, final TokenStream result) {
this.source = source;
this.sink = result;
}
2、org.apache.lucene.analysis.TokenStream:
分词处理器,负责对输入文本完成分词、处理)。它是一个抽象类,继承了AttributeSource(负责存放Attribute对象),只有一个抽象方法incrementToken()
(Token:分项,从字符流中分出一个一个的项;
Token Attribute:分项属性(分项的信息),比如包含的词、位置等,这些属性通过不同的Tokenizer/TokenFilter处理统计得出。不同的Tokenizer/TokenFilter组合,就会有不同的分项信息,它是会动态变化的)
2.1、子类Tokenizer:分词器,输入是Reader字符流的TokenStream,完成从流中分出分项
2.2、子类TokenFilter:分项过滤器,它的输入是另一个TokenStream,完成对从上一个TokenStream中流出的token的特殊处理
要实现自己的Tokenizer、TokenFilter只要继承它们,然后覆写incrementToken()方法
创建自己的分词器需要实现:Analyzer分析器、分词器Tokenizer、分项过滤器TokenFilter、(可选的Attribute(AttributeImpl))
除了lucene自带的分词器,还有许多第三方提供的分词器,比如中文分词器等,像之前使用到的StandardAnalyzer进行中文分词,就只是将所有中文一个个字拆开来而已:
String text = "春眠不觉晓,处处闻啼鸟";
Analyzer analyzer = new StandardAnalyzer();
testAnalyzer(analyzer, text);
public void testAnalyzer(Analyzer analyzer, String text) throws IOException {
System.out.println("当前使用的分词器:" + analyzer.getClass().getSimpleName());
// 获取真正的分词处理器,负责对输入文本完成分词、处理:域的名称,要分析的文本
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
// 存储分项属性,可以是关键词的引用,偏移量等等,重复调用add方法添加它返回已存储的实例对象
// 加入的每一个Attribute实现类在AttributeSource中只会有一个实例,分词过程中,分项是重复使用这一实例来存放分项的属性信息
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 进行重置,因为tokenStream是重复利用的
tokenStream.reset();
// 循环调用incrementToken方法,一个一个分词,直到它返回false
while (tokenStream.incrementToken()) {
// 要获取分项的某属性信息,则需持有某属性的实例对象,通过addAttribute方法或getAttribure方法获得Attribute对象,再调用实例的方法来获取、设置值
System.out.println(new String(charTermAttribute.toString()));
}
// 执行任务需要的结束处理
tokenStream.end();
// 释放占有的资源
tokenStream.close();
}
第三方分词器,其中比较有名的是IK-analyzer,主要还是其扩展词词典和停用词词典的强大,使用很简单
扩展:
Lucene03-分词器简介及IK分词器的使用
开放源代码的全文检索引擎 Lucene