Java基础SE(一) 数据类型与关键字
Java基础SE(二) 集合
Java基础SE(三) 线程与并发
Java基础SE(三) 线程与并发-补充
Java基础SE(四) IO
类型
String
首先看String类的定义
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
可以了解到,String类是final的,即不可被继承。其实现了序列化接口、排序接口和字符序列
CharSequence与String都能用于定义字符串,但CharSequence的值是可读可写序列,而String的值是只读序列
然后看存储结构
private final char value[];
private int hash;
因此做一些length、isEmpty、charAt等操作时,只需要对数组进行操作就行,非常方便。而像equals、compareTo、indexOf、lastIndexOf等都是对数组的每一个字符进行一一比较的。由于String是不可变的(final数组),所以像substring、concat等操作,是直接创建一个新的String对象返回,同时这样使得字符串池得以实现,节省了很多堆空间,并且没有安全性问题(final)
String的hash使用31素数作为系数:h = 31 * h + val[i]
JDK 6的substring方法虽然创建了一个新的String对象,但是其value属性依然指向堆内存中原来的那个数组,区别只是它们的count和offset不同了,因此可能会有性能问题。而在JDK 7以后,substring方法真正的在堆内存创建了另外一个数组,
this.value = Arrays.copyOfRange(value, offset, offset+count);
replaceFirst可以使用正则匹配或字符串去替换第一个符合的内容。replace和replaceAll也都是使用Pattern.matcher的方式,但是replaceAll和replaceFirst一样可以使用正则也可以使用普通字符串,而replace是仅将字符串理解为字面意义上的字符串,不能使用正则语法匹配,所以这2个方法的区别在这里,而不是看起来字面意义上的替换单个和替换全部,它们都是替换全部的,这个需要注意,换个方式也就是如果不使用正则表达式,replace和replaceAll的结果是完全一致的
在Java语言中,操作符重载是不被允许的,虽然提高了灵活性,但会提高复杂性和可读性,而且与Java设计思想相悖。但是对于String对象而言,它可以将2个String用”+”相加,看起来像是对”+”的重载,事实上从class文件可以看出,这是Java提供的语法糖,它在拼接的时候会使用StringBuilder.append()方法而不是”+”,因此如果在循环中使用会造成创建多个StringBuilder对象的资源浪费
String中有许多方法会创建新的数组,其中就会使用Arrays.copyOf方法和System.arraycopy方法,而Arrays.copyOf方法底层也是用了System.arraycopy方法。需要注意的是,对于二维数组,新copy出的数组被复制的是引用,所以原数组和新数组都指向相同的一些数组,因此修改会影响到原数组。对于数组的复制,由于System.arraycopy使用native方法,因此贴近底层,使用了内存复制,省去了大量的数组寻址访问等时间,效率很高
String被设计为不可变的原因:
1、字符串常量池的需要
2、允许String对象缓存HashCode
3、安全性
4、线程安全
StringBuffer与StringBuilder共同父类AbstractStringBuilder,前者是线程安全的,后者是非线程安全的
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
// 内部使用了Arrays.copyOf
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
Integer与Long
Integer同样也是final class,并且值也是final的
public final class Integer extends Number implements Comparable<Integer> {
@Native public static final int MIN_VALUE = 0x80000000;
@Native public static final int MAX_VALUE = 0x7fffffff;
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
private final int value;
@Native public static final int SIZE = 32;
public static final int BYTES = SIZE / Byte.SIZE; // 32/8 = 4
从JDK 5以后加入的autoboxing功能,自动拆箱和装箱依靠JDK的编译器在编译期的预处理工作,可以实现基本数据类型int与引用数据对象Integer的封装转换。自动拆箱很典型的用法就是在进行运算的时候:因为对象不能直接进行运算,需要转化为基本数据类型后才能进行加减乘除
Java对autoboxing使用了享元模式(flyweight),对常用的简单数字进行了重复利用,缓存了-128到127之间的数字。最小值-128是固定的,而缓存大小与缓存最大值可以通过JVM参数设置,默认为127
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
因此在这个范围内,除非使用new创建Integer对象,否则通过autoboxing封装的Integer对象间使用==都会返回true,而使用new则创建了新的对象,其地址不同,返回false。自动装箱拆箱不仅在基本数据类型中有应用,在String类中也有应用(即用new和不用new使用字符串池)
Integer的toString方法有2种,一种可以实现将数字i转变成radix进制数,另一种单纯打印数字,它们都将数字转换为char数组,然后创建String返回,而且使用了大量优化(位移代替除法、使用初始化好的char数组取值)
Integer里有许多方法使用了位移操作和位操作,其中有几个特殊意义的十六进制数
十六进制 二进制
0x55555555 01010101010101010101010101010101
0x33333333 00110011001100110011001100110011
0x0f0f0f0f 00001111000011110000111100001111
0xff00 1111111100000000
0x3f 111111
Integer在很多方法中使用负数,很容易避免数据操作的溢出。正数的原码、反码和补码是一样的,而负数的反码是其在原码的基础上除了符号位不变,其他位取反;且负数的补码是其在反码的基础上某位加1
与Integer基本类似,Long内部也有一个LongCache用来缓存固定的-128到127的Long对象
Float与Double
float和double是java的基本类型,用于浮点数表示,Float和Double就是它们的包装类。不过它们都有精度问题,浮点数采用“尾数+阶码”的编码方式,类似于科学计数法的“有效数字+指数”的表示方式,二进制无法精确表示大部分的十进制小数,所以浮点数间的运算不准确,应该避免浮点数的比较。因此Float和Double只能用来做科学计算和工程计算。商业运算中我们要使用BigDecimal
内部的与String相互转换的方法(parseXXX与toString)使用了FloatingDecimal
数据类型长度
| 基本类型 | 包装类 | 长度 | 取值范围 |
|---|---|---|---|
| byte | java.lang.Byte(Number) | 1字节/8位 有符号 | -128(-2^7) ~ 127(2^7-1) |
| boolean | java.lang.Boolean | 1位 | true / false |
| short | java.lang.Short(Number) | 2字节/16位 有符号 | -32768(-2^15) ~ 32767(2^15-1) |
| char | java.lang.Character | 2字节/16位 Unicode字符 | 0(\u0000) ~ 65535(\uFFFF) |
| int | java.lang.Integer(Number) | 4字节/32位 有符号 | -2^31 ~ 2^31-1 |
| long | java.lang.Long(Number) | 8字节/64位 有符号 | -2^63 ~ 2^63-1 |
| float | java.lang.Float(Number) | 4字节/32位(1,8,23) 单精度 | (+/-) 2^-149 ~ (2-2^-23)*2^127 |
| double | java.lang.Double(Number) | 8字节/64位(1,11,52) 双精度 | (+/-) 2^-1074 ~ (2-2^-52)·2^1023 |
另外一个英文字符或符号占用1个字节;而一个中文字符或符号可能是2个、3个、4个字节,不同的编码格式占字节数是不同的,UTF-8编码下的一个中文所占字节也是不确定的(汉字少数是3字节(52156个),多数是4字节(64029个))
BigDecimal
在使用BigDecimal解决精度问题的时候,只有使用BigDecimal(String)构造器创建对象,或者BigDecimal.valueOf去创建对象才有意义,否则使用double入参还是会发生精度丢失的问题
BigDecimal由一个整数非标度值(private final transient long intCompact或private final BigInteger intVal)和一个小数点标度(private final int scale)和一个总标度(private transient int precision)组成,此外有一个stringCache存储对应的字符串,其创建主要就是将字符串拆为字符数组后进行循环判断,生成这几个变量值
例子:
scale = 7 // 小数点标度
precision = 8 // 总标度
stringCache = "3.1415926" // 对应的字符串
intCompact = 31415926 // 整数非标度值
scale = 1
precision = 4
stringCache = "-100.0"
intCompact = -1000
// 定义了intVal,或者传的字符串长度大于等于18时才使用BigInteger表示数字
BigDecimal bg = new BigDecimal(new BigInteger("12345"), 2);
// The unscaled value of this BigDecimal
intVal = {BigInteger@506} "12345"
scale = 2
precision = 0
stringCache = "123.45"
intCompact = 12345
此外BigDecimal缓存了0~10的数和标度在0~15的0,在一些地方可以直接使用。BigDecimal的计算主要就是加减乘除,即add、subtract、multiply、divide
十进制转二进制方法: 整数部分:除以2,取出余数,商继续除以2,直到得到0为止,将取出的余数逆序 小数部分:乘以2,然后取出整数部分,将剩下的小数部分继续乘以2,然后再取整数部分,一直取到小数部分为零为止。如果永远不为零,则按要求保留足够位数的小数,最后一位做0舍1入。将取出的整数顺序排列
Enum
枚举类型是Java5中新增特性的一部分,它是一种特殊的数据类型,并为基础基元类型的值提供备用名称,之所以特殊是因为它既是一种类(class)类型却又比类类型多了些特殊的约束,但是这些约束的存在也造就了枚举类型的简洁性、安全性以及便捷性
在使用关键字enum创建枚举类型并编译后,编译器会为我们生成一个相关的类,这个类继承了JavaAPI中的java.lang.Enum类,事实上也是一个类类型
它用于声明一组命名的常数,当一个变量有几种可能的取值时,可以将它定义为枚举类型,比如月份、季节等。可以在枚举中添加新方法,覆盖枚举方法,自带方法:name()、ordinal()
目前最安全的实现单例的方法是通过内部静态Enum的方式来实现,因为JVM会保证Enum不会被反射,且构造器方法只执行一次
关键字与操作
Serializable
Serializable是序列化接口,实现了Serializable的接口拥有了序列化功能,可以设置一个serialVersionUID,用于标识这个类的序列化版本,如果序列化与反序列化(deserialization)的同一个类的版本不同,会抛出异常
Serializable接口只是个标识接口,其实是给JVM看的,让JVM帮我们序列化。实现了Serializable接口的类可以被ObjectOutputStream转换为字节流,同时也可以通过ObjectInputStream再将其解析为对象。无论什么编程语言,其底层涉及IO操作的部分还是由操作系统帮其完成的,而底层IO操作都是以字节流的方式进行的,所以写操作都涉及将编程语言数据类型转换为字节流,而读操作则又涉及将字节流转化为编程语言类型的特定数据类型
// ObjectOutputStream
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}
// ObjectInputStream
public final Object readObject()
throws IOException, ClassNotFoundException {
if (enableOverride) {
return readObjectOverride();
}
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}
通过Serializable接口对对象序列化的支持是内建于核心API的,但是java.io.Externalizable的所有实现者必须提供读取和写出的实现。Java已经具有了对序列化的内建支持,也就是说只要制作自己的类java.io.Serializable,Java就会试图存储和重组你的对象。如果使用外部化,就可以选择完全由自己完成读取和写出的工作。需要额外注意的是,如果一个类是可外部化的(Externalizable),那么Externalizable方法将被用于序列化类的实例,即使这个类型提供了Serializable方法
Externalizable继承自Serializable,需重写writeExternal与readExternal方法,且必须提供一个public无参构造方法
序列化只能保存对象的非静态成员交量,不能保存任何的成员方法和静态的成员变量,而且序列化保存的只是变量的值,对于变量的任何修饰符都不能保存。因为序列化保存的是对象的状态,静态变量属于类的状态
当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口。而一个子类实现了Serializable接口,它的父类没有实现,如果要想将父类对象也序列化,就需要让父类也实现Serializable接口。而且如果父类不实现Serializable接口,就需要有默认的无参构造函数。这是因为一个Java对象的构造必须先有父对象,才有子对象,反序列化也不例外
writeReplace与readResolve是更彻底的序列化机制,甚至可序列化目标对象为其他对象。与writeObject,readObject不同的是,两者不必须一起使用,且尽量分开使用。若一起使用,只有writeReplace方法会生效
反射可以破坏单例,序列化和反序列化同样破坏单例。因此在单例中定义readResolve方法,并在该方法中指定要返回的对象生成策略(return singleton),就可以防止破坏
序列化会通过反射调用无参构造方法创建一个新的对象
如果JAVA应用对用户输入、不可信数据做了反序列化处理,那攻击者可以通过构造恶意输入,让反序列化产生非预期对象,非预期对象在产生过程中就可能带来任意代码执行。根源是类ObjectInputStream在反序列化时,没有对生成对象的类型做限制,如果没有对应的安全校验,如白名单校验,且输入可控的话就可能存在安全问题:
1、重写resolveClass方法可以实现反序列化校验:Hook resolveClass黑名单
2、使用ValidatingObjectInputStream的accept方法实现反序列化黑名单控制
3、JDK9中使用ObjectInputFilter来校验(过滤器来实现黑白名单)
transient
transient是服务于序列化的,被transient修饰的变量将不被序列化,即阻止实例中那些用此关键字声明的变量持久化;同样,当对象被反序列化时这些实例变量值不会被恢复。因此当某些变量不想被序列化,同是又不适合使用static关键字声明,那么此时就需要用transient关键字来声明该变量
对于某些类型的属性,其状态是瞬时的,这样的属性是无法保存其状态的。例如一个线程属性或需要访问IO、本地资源、网络资源等的属性,对于这些字段,我们必须用transient关键字标明,否则编译器将报措
final
- 变量
- final变量表示常量,只能被赋值一次,赋值后值不再改变
- 方法
- 表示不能被子类重写,但可以被继承,如果认为一个方法的功能足够完善,子类不需要改变的话,就声明为final。final方法比非final方法要快,因为在编译的时候已经静态绑定了,不需要在运行时再动态绑定
- 类
- final类功能通常是完整的,它们不能被继承,没有子类,例如String
总结:
1、final关键字提高了性能。JVM和Java应用都会缓存final变量
2、final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销
3、使用final关键字,JVM会对方法、变量及类进行优化
4、对于不可变类,它的对象是只读的,可以在多线程环境下安全的共享,不用额外的同步开销
5、final变量必须声明时初始化/构造器初始化
6、匿名类中都必须是final变量(复制)
7、final在编译阶段绑定,成为静态绑定
static
- 变量
- 局部变量:定义在方法中,不可以被访问控制符及static修饰,可定义成final,需要自己初始化
- 成员变量:定义在类中,Java会帮你初始化
- 实例变量(对象变量):不能static修饰
- 类变量(静态变量):可用static修饰,被类的实例公用
- 方法
- 静态方法:被一个类的所有实例公用
- static方法内部不能访问非静态成员方法和非静态成员变量
- static方法不能被子类重写为非static方法,同样父类的非static方法不能被子类重写为static方法
- 就是没有this的方法,内部不能调用非static方法(构造器不是静态方法,首先不是方法,其次实例构造器中有一个隐式参数this,构造器无法被隐藏和覆写,不参与多态,因而可以做动态绑定)
- static代码块:在类被第一次(只在第一次)装载时执行初始化,先于静态方法和其他方法的执行
- 静态方法:被一个类的所有实例公用
- 类
- 静态内部类:没有外部类对象时,也能够访问静态内部类。静态内部类仅能访问外部类的静态成员和方法
顺序:父类static块 -》子类static块 -》父类成员变量 -》父类构造器 -》子类成员变量 -》子类构造器
volatile
类型修饰符:
- 可见性:保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。volatile使用Lock前缀的指令禁止线程本地内存缓存,保证不同线程之间的内存可见性。volatile的写-读与锁的释放-获取有相同的内存效果
- 当写一个volatile变量时,JMM会把该线程对应的本地中的共享变量值刷新到主内存
- 当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量
- 有序性:禁止进行指令重排序,内存屏障禁止重排序
- 在每个volatile写操作的前面插入一个StoreStore屏障。在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的后面插入一个LoadLoad屏障。在每个volatile读操作的后面插入一个LoadStore屏障
- volatile只能保证对单个读/写的原子性,像i++这种复合操作不能保证原子性
synchronized保证可用性,是”如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值” 与 “对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store和write操作)” 这两条规则获得的
注意:基于 CPU 缓存一致性协议,JVM 实现了 volatile 的可见性,但由于总线嗅探机制,会不断的监听总线,如果大量使用 volatile 会引起总线风暴。所以,volatile 的使用要适合具体场景
java内存模型
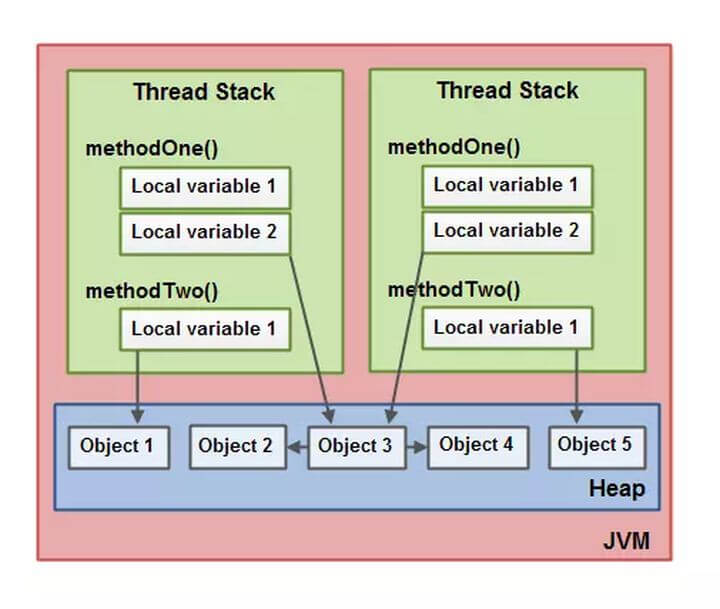
Java内存模型:调用栈和本地变量存放在线程栈上,对象存放在堆上
- 原始类型的局部变量,它始终存在线程栈上
- 对象引用的局部变量,这个引用存放在线程栈上,对象本身存放在堆上
- 该对象的方法里,如果包含局部变量,这些本地变量会存放在线程栈上
- 该对象的成员变量、类变量(静态)会随着这个对象自身存放在堆上
- 存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量
- 如果两个线程同时调用同一个对象上的同一个方法,并且它们都会访问这个对象的成员变量,那么每一个线程都将拥有这个成员变量的私有拷贝
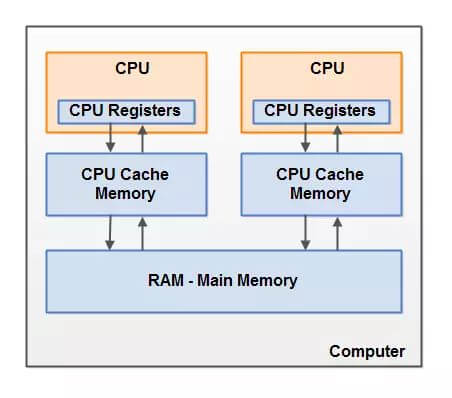
现代计算机硬件架构下,每个CPU都包含一系列的寄存器,还有高速缓存cache来作为内存与处理器之间的缓冲,最后每个计算机有一个主存。当一个CPU需要读取主存时,它会将主存的部分读到CPU缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。当CPU需要将结果写回到主存中去时,它会将内部寄存器的值刷新到缓存中,然后在某个时间点将值刷新回主存
该硬件架构带来的问题:
- 缓存一致性问题
- 在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存。基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也引入了新的问题:缓存一致性。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致的情况,如果真的发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI、MOSI、Synapse、Firefly及DragonProtocol等等
- 指令重排序问题
- 为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与代码中的顺序一致。与处理器的乱序执行优化类似,Java虚拟机的即时编译器中也有类似的指令重排序优化
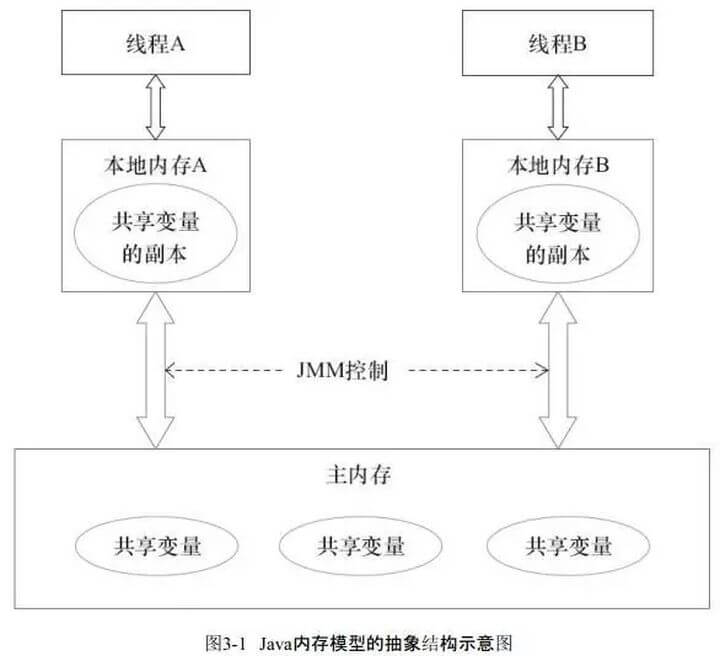
JMM定义了线程和主内存之间的抽象关系
- 线程之间的共享变量存储在主内存(硬件的内存)中
- 每个线程都有一个私有的工作内存
- 工作内存是JMM的一个抽象概念,并不真实存在,它是cpu的寄存器和高速缓存的抽象描述
- 本地内存中存储了该线程以读/写共享变量的拷贝副本
- 线程对变量的所有的操作(读,取)都必须在工作内存中完成,而不能直接读写主内存中的变量
- 不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存中转来完成
关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存,又如何从工作内存同步到主内存之间的实现细节,Java内存模型定义了以下八种操作来完成:
- lock(锁定)
- 作用于主内存的变量,把一个变量标识为一条线程独占状态
- unlock(解锁)
- 作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read(读取)
- 作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- write(写入)
- 作用于主内存的变量,把store操作从工作内存中一个变量的值传送到主内存的变量中
- load(载入)
- 作用于工作内存的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中
- store(存储)
- 作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
- use(使用)
- 作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作
- assign(赋值)
- 作用于工作内存的变量,把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
Java内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
- 如果要把一个变量从主内存中复制到工作内存,就需要按顺寻地执行read和load操作, 如果把变量从工作内存中同步回主内存中,就要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行
- 不允许read和load、store和write操作之一单独出现
- 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中
- 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作
- 一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。即lock和unlock必须成对出现
- 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
- 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量
- 对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)
重排序
- 编译器优化的重排序
- 编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
- 指令级并行的重排序
- 现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
- 编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序
- 内存系统的重排序
- 由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行
- 每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写-读操作进行重排序
happens before:在JMM中,如果一个操作执行的结果需要对另一个操作可见(两个操作既可以是在一个线程之内,也可以是在不同线程之间),那么这两个操作之间必须要存在happens-before关系:
- 程序顺序规则
- 一个线程中的每个操作,happens-before于该线程中的任意后续操作
- 监视器锁规则
- 对一个锁的解锁,happens-before于随后对这个锁的加锁
- volatile变量规则
- 对一个volatile域的写,happens-before于任意后续对这个volatile域的读
- 传递性
- 如果A happens-before B,且B happens-before C,那么A happens-before C
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序
instanceof
如果object是class的一个实例,则instanceof运算符返回true。如果object不是指定类的一个实例,或者object是null,则返回false。instanceof运算符只能用作对象的判断,即obj必须为引用类型,不能是基本类型(null是可以成为任意引用类型的特殊符号)
// 伪代码
boolean result;
if (obj == null) {
result = false;
} else {
try {
T temp = (T) obj; // checkcast
result = true;
} catch (ClassCastException e) {
result = false;
}
}
- obj如果为null,则返回false;否则假设S为obj的类型对象
- 如果S == T,则返回true
3、剩下的问题就是检查S是否为T的子类型,因为instanceof要做的是”子类型检查”,而Java语言的类型系统里数组类型、接口类型与普通类类型三者的子类型规定都不一样,必须分开来讨论
- S是数组类型:如果T是一个类类型,那么T必须是Object;如果T是接口类型,那么T必须是由数组实现的接口之一
- 接口类型:instanceof就直接遍历S里记录的它所实现的接口,看有没有跟T一致的
- 类类型:instanceof则遍历S的super链(继承链)一直到Object,看有没有跟T一致的。遍历类的super链意味着这个算法的性能会受类的继承深度的影响
位运算
原码:原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值
反码:正数的反码是其本身;负数的反码是在其原码的基础上,符号位不变,其余各个位取反
补码:正数的补码就是其本身;负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1(也即在反码的基础上+1)
按位与运算符:&
0&0=0 0&1=0 1&0=0 1&1=1
例:3&5
0000 0011
& 0000 0101
--------------
0000 0001 即3&5=1
* 负数按补码形式参加按位与运算
与运算的用途:
1)清零
将一个单元清零,只要与一个各位都为零的数值相与,结果为零
2)取一个数的指定位
比如取数:X=1010 1110 的低4位,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位与运算(X&Y=0000 1110)即可得到X的指定位
3)判断奇偶
只要根据最未位是0还是1来决定,为0就是偶数,为1就是奇数。因此可以用if((a & 1) == 0)代替if (a % 2 == 0)来判断a是不是偶数
按位或运算符:|
0|0=0 0|1=1 1|0=1 1|1=1
例:3|5
0000 0011
| 0000 0101
--------------
0000 0111 即3|5=7
* 负数按补码形式参加按位或运算
异或运算符:^
0^0=0 0^1=1 1^0=1 1^1=0
1、交换律
2、结合律 (a^b)^c == a^(b^c)
3、对于任何数x,都有 x^x=0,x^0=x
4、自反性: a^b^b=a^0=a;
异或运算的用途:
1)翻转指定位
2)交换两个数,if (a != b){ a ^= b; b ^= a; a ^= b; }
取反运算符:~
~1=0 ~0=1
其他
泛型
Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉
Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的
原始类型 就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型,无论何时定义一个泛型,相应的原始类型都会被自动提供,类型变量擦除,并使用其限定类型(无限定的变量用Object)替换
擦除规则:
1、若泛型类型没有指定具体类型,用Object作为原始类型;
2、若有限定类型< T exnteds XClass >,使用XClass作为原始类型;
3、若有多个限定< T exnteds XClass1 & XClass2 >,使用第一个边界类型XClass1作为原始类型
Java编译器是通过先检查代码中泛型的类型,然后在进行类型擦除,再进行编译。类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象
*JDK1.8泛型推导升级
泛型类:class Box<T>
泛型方法:<K,V> boolean compare(Pair<K,V> p1, Pair<K,V> p2)
边界符:<T extends Cpmporable<T>> int bigThan(T[]array, Telem)
通配符:T readCovariant(List<? extends T>list)
命名约定:K:键;V:值;E:异常类;T:泛型
PECS原则:
- 如果要从集合中读取类型T的数据,并且不写入,可以使用
? extends通配符;(Producer Extends) - 如果要从集合中写入类型T的数据,并且不需要读取,可以使用
? super通配符;(Consumer Super) - 如果既要存又要取,那么就不要使用任何通配符
JAVA不允许创建泛型数组,因为运行时泛型擦除,都变Object,JVM不能区分
泛型继承:父类为泛型类,编译器为了实现多态会帮子类实现一个Bridge method桥方法,内部父类强转调用子类具体方法
父类:setXX(Object) 子类:setXX(String) -》 setXX(Ojbect){setXX((String)Object)}
但是对于getXX这种方法,会出现返回值不同的2个方法,方法签名一致
1、方法签名确实只有方法名+参数
2、我们不能编写签名一样的2个方法
3、JVM会用参数类型和返回类型来确定一个方法,只有编译器能做到2个签名一样的方法
总结:
1、JVM中没有泛型,只有普通类和方法
2、在编译阶段,所有泛型类的类型参数都会被Object或它们限定边界来替换
3、在继承泛型类型时,桥方法的合成是为了避免泛型擦除带来的多态灾难
注解
内置的注解:
@Override 重写方法
@Deprecated 标记过时方法
@SuppressWarnings 指示编译器忽略警告
@SafeVarargs 忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告
@Retention 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问
@Documented 标记这些注解是否包含在用户文档中
@Target 标记这个注解应该是哪种Java成员
@Inherited 标记这个注解是继承于哪个注解类(默认 注解并没有继承于任何子类)
@FunctionalInterface 标识一个匿名函数或函数式接口
@Repeatable 标识某注解可以在同一个声明上使用多次
结构:
1、1个Annotation和1个RetentionPolicy关联(Enum枚举类型,指定Annotation的策略,即作用域)
2、1个Annotation和1~n个ElementType关联(Enum枚举类型,指定Annotation的类型)
a) 若Annotation的类型为SOURCE,则意味着:Annotation仅存在于编译器处理期间,编译器处理完之后,该Annotation就没用了 例如:@Override。在编译期间会进行语法检查,编译器处理完后就没有任何作用了
b) 若Annotation的类型为CLASS,则意味着:编译器将Annotation存储于类对应的.class文件中,它是Annotation的默认行为
c) 若Annotation的类型为RUNTIME,则意味着:编译器将Annotation存储于class文件中,并且可由JVM读入
常用自定义注解
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {
}
Java使用动态代理对象对我们定义的注解接口生成了一个代理类,而对注解属性赋值其实是对代理类的变量赋值,所以能用反射获取注解的各种属性
clone
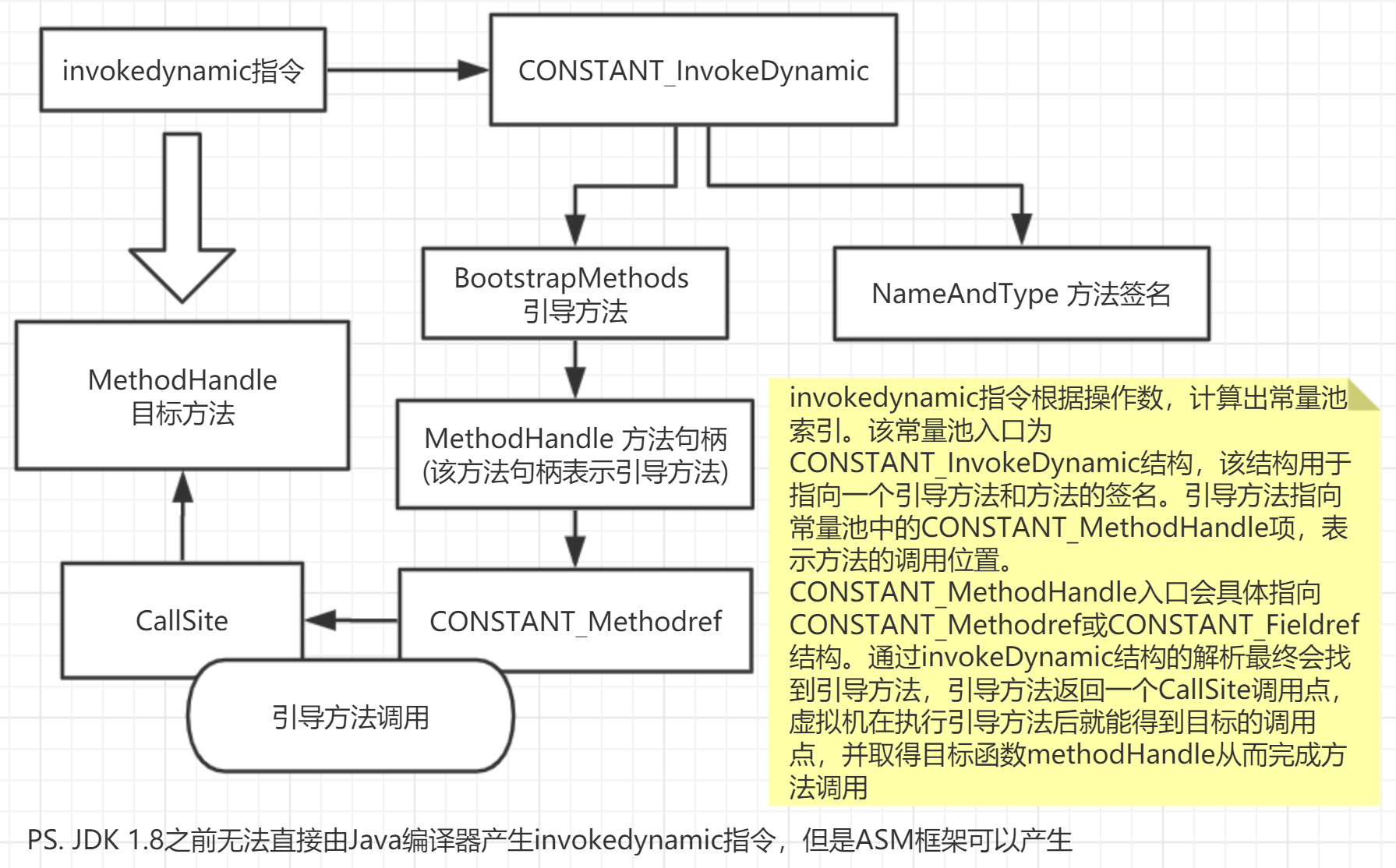
invokedynamic