Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
介绍
Solr搜索引擎擅长处理的数据表现为几大特征:
1、以文本为中心
2、读主导
3、面向文档
4、灵活的模式
5、大数据
Solr使用Lucene来实现索引文档的核心数据结构,并执行文档搜索。在后台,lucene是一个Java类库,用于倒排索引的构建和管理,倒排索引是专门用于匹配查询词项与文本文档的数据结构
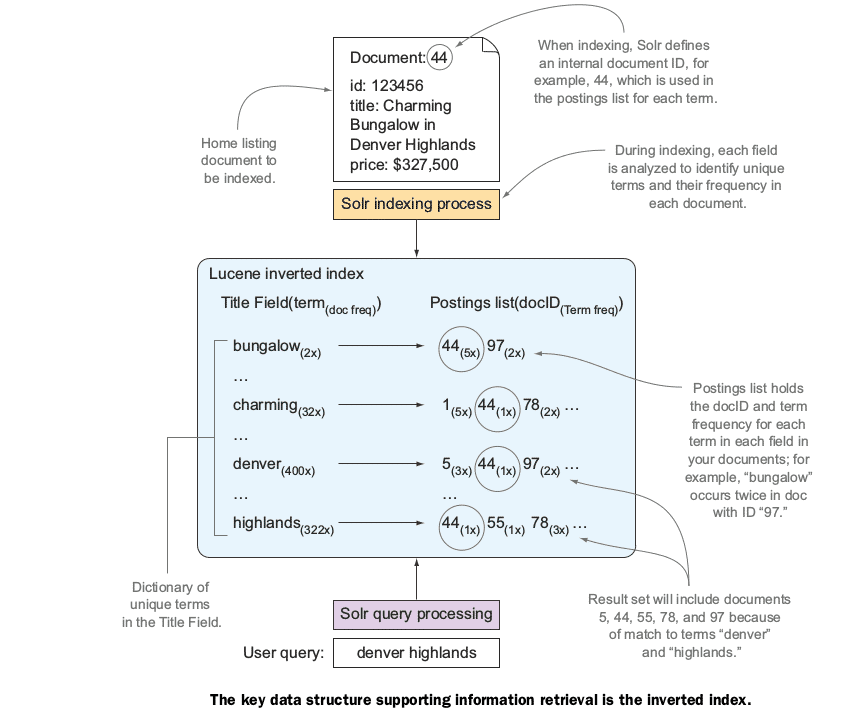
Lucene提供搜索的核心基础构架,Solr在Lucene基础上做了增强:灵活的模式管理、Java Web应用、一台服务器上的多个索引、可扩展性(插件)、可伸缩性、容错性
Solr的内核由配置文件、Lucene索引文件和Solr事务日志组成
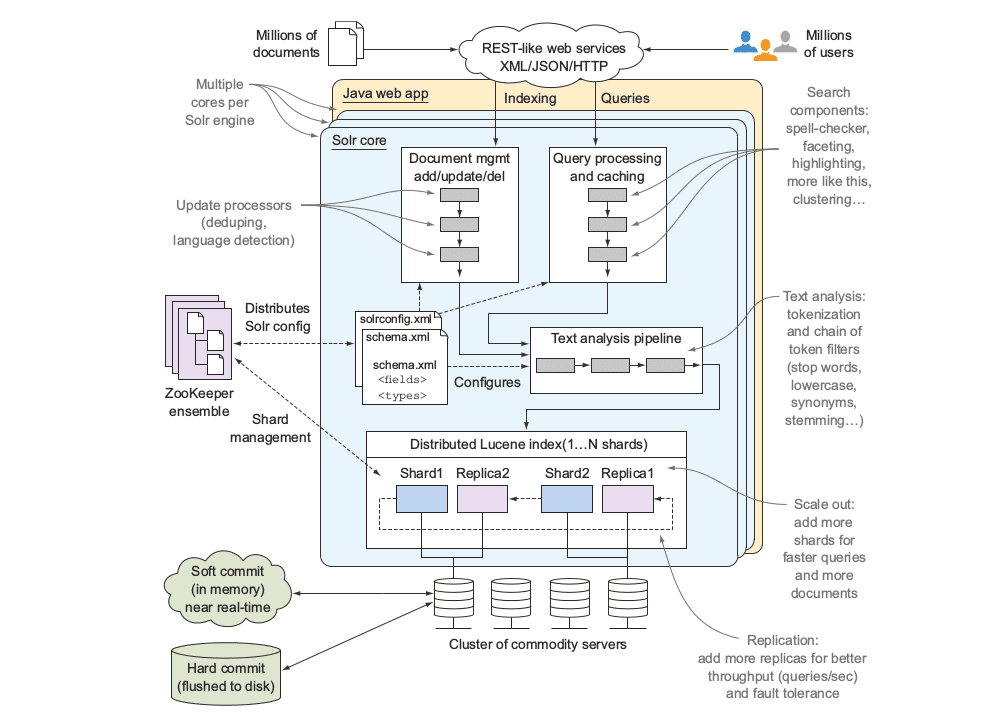
下载Solr完后解压缩,在根目录下执行bin\solr -e techproducts(example文件夹下README)命令,可以启动示例服务器,然后通过http://localhost:8983/solr地址访问
根目录下执行‘java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs*’命令可以通过HTTP POST方式把XML文档发送到Solr
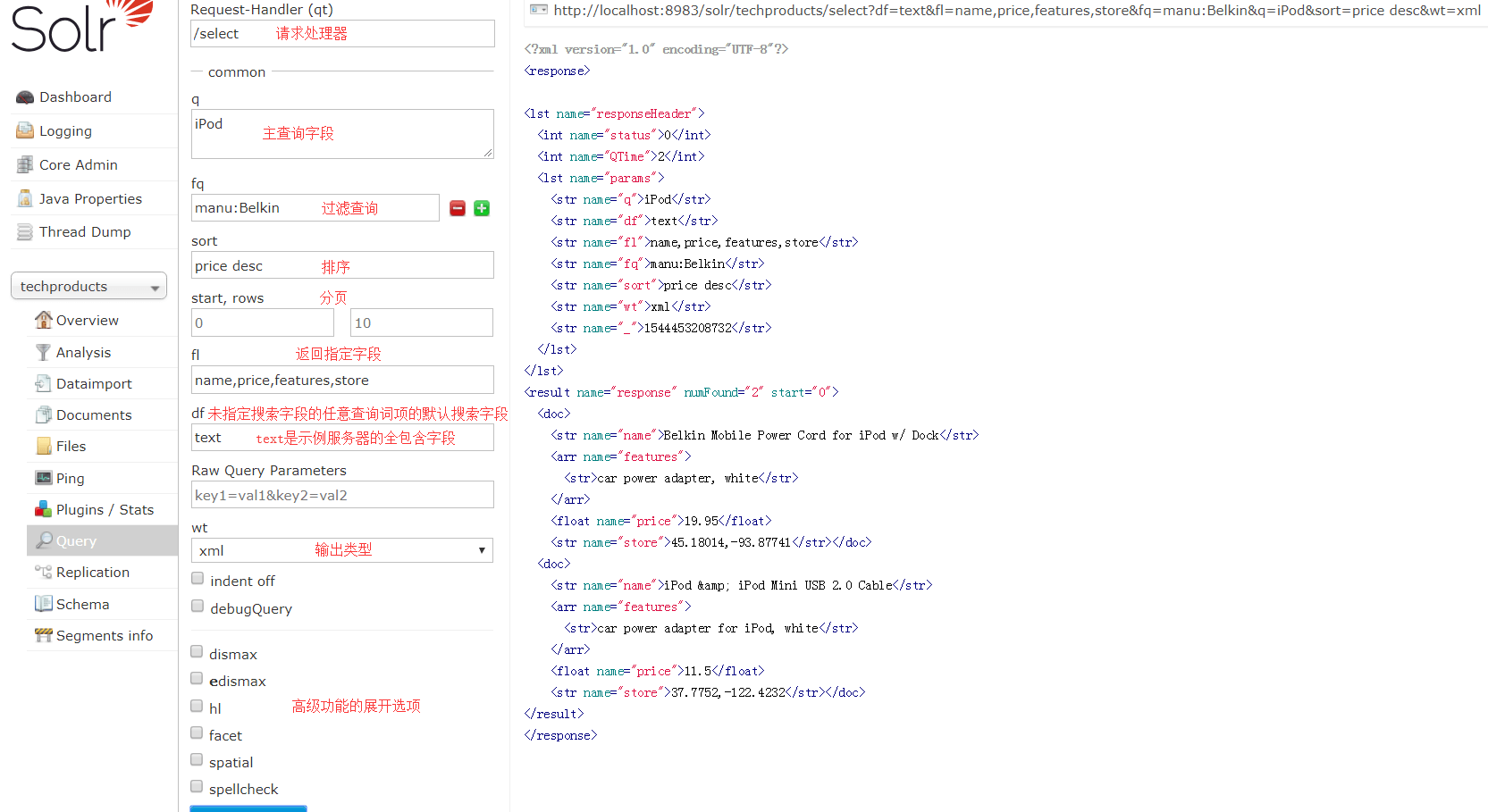 可以看到查询表单的URL地址:
可以看到查询表单的URL地址:http://localhost:8983/solr/techproducts/select?df=text&fl=name,price,features,store&fq=manu:Belkin&q=iPod&sort=price%20desc&wt=xml&rows=10&start=0
删除集合solr delete -c techproducts
停止启动bin\solr stop -all
基础理论
一个文档通过定义schema,映射为特定字段类型的字段集合,文档的每个字段根据其字段类型进行内容分析,分析的结果保存到索引中,这样在发起查询时就能检索到相关结果。Solr查询返回的主要搜索结果是由一个或多个字段组成的文档集
倒排索引
Solr使用Lucene倒排索引来驱动快速搜索功能,并且在查询时提供了许多其他附加功能
1、倒排索引中的所有词项对应一个或多个文档
2、倒排索引中的词项根据字典顺序升序排列
词项、短语与布尔逻辑
必备词项:+my +bike 或者 my AND bike
可选词项:my bike 或者 my OR bike
排除词项:my bike -red 或者 my bike NOT red
solr不仅支持单个词项搜索,还支持短语搜索,确保多个词项按特定的顺序出现:”new home” OR “new house”
组合表达式:New AND (house OR (home NOT improvement NOT depot NOT grown)) 或者像 (+(buying purchasing -renting) + (home house residence -(+property -bedroom)))
模糊匹配
通配符搜索(只适用于单个查询词不适用于短语):offi, offr, off?r
区间搜索:created:[2018-12-01T00:00.0Z TO 2018-12-31T00:00.0Z], price:[12.5 TO 35.6], title:[boat TO boulder]
模糊/编辑距离搜索:Solr使用~符号表示模糊编辑距离搜索,灵活处理拼写错误,甚至对正确拼写做出细微修正。administrator~,这个查询匹配到原始词项(administrator)及与之相距两个编辑距离的其他词项。编辑距离被定义为字符的一次插入、删除、替换或位置互换。administrator~N可以匹配N个以内的编辑距离
临近搜索:”chief officer”~1表示chief与officer之间最多相隔一个词,例如chief executive officer
相关度
Solr的相关度得分是基于Similarity类的,在schema.xml中被定义为一个预设字段
默认下使用Lucene相应的DefaultSimilarity类。这个类使用两段式检索模型来计算相似度。首先使用布尔模型过滤出不符合用户查询的所有文档。然后使用向量空间模型通过计算和绘制将查询和文档转换为向量,在此基础上计算相似度得分。每个文档的相似度得分基于查询向量与文档向量的夹角余弦值
在向量空间评分模型中,每个文档的词项向量经过计算后会与给定查询对应的词项向量进行比较。两者的相似度通过夹角的余弦值来表示,余弦值为1表示完美匹配,余弦值为0表示无相似性。也就是两个向量夹角越小,余弦值越大,匹配度越高
词项频次:一般来说,若主题在文档中出现多次,则被认为该文档与主题更相关
反向文档频次:查询词项罕见程度的度量,根据文档词频计算它的逆
词项频次与反向文档频次在相关度计算中起到了相互平衡的作用
词项权重:title:(solr)^2.5 name:(jack)表示title字段的查询短语权重设置为2.5,name保留默认权重1。如果权重小于1,也可用于惩罚特定词项,不过仍然是正向权重,只是让其比默认权重的词项弱一点。查询阶段词项可以应用在查询表达式的任何部分。索引阶段也可以为文档字段设置权重,这些权重会被分解到字段规范中
规范化因子
字段规范:字段规范因子是以每个文档为基础的特定字段重要性的因子组合。字段规范在索引创建时进行计算,其表示为Solr索引中每个字段的一个附加字节。该字节包含许多信息:文档被索引时的权重集、字段被索引时的权重集、惩罚长文档的同时提升短文档的长度归一化因子
查询规范
协调因子:Solr默认相关度计算的最后一个规范化因子。作用是衡量每个文档匹配的查询数量
查全率与查准率
查准率:返回的文档是不是需要寻找的文档的比率,即每个返回的搜索结果是否正确
查全率:衡量搜索结果的全面性
虽然查准率与查全率之间存在明显的互逆关系,但他们并不是互相排斥的。最大限度提升查准率与查全率是绝大多数搜索相关度优化的最终目标。Solr采用的许多技术能够提高查准率与查全率,其中大多数倾向提高返回完整文档集的查全率。Solr中平衡查准率与查全率的一种常见方式是:在整个结果集上计算查全率,仅在搜索结果第一页(或少数页)上计算查准率
Solr的局限
Solr在文档处理上不以任何方式构成关系型。它不适用于在不同文档的不同字段上连接大量数据,也无法在多台服务器上执行join操作。而且Solr文档的非规范化属性,导致数据是冗余的,每个文档中相同字段的数据会重复出现。当多个文档共享的某一个字段数据发生变化时,会带来麻烦的更新问题
Solr的另一个局限在于,它目前主要用作文档存储方案,也就是可以插入、删除与更新文档,但不能对字段轻松地做这些操作
Solr不适用于处理非常长的查询(包含上千个搜索词的查询)或给用户返回大量搜索结果集
Solr最后一个值得一提的局限在于它的可扩展性(自动添加和删除服务器,处理负载而重新分发内容的能力)不够灵活
扩展:
Solr系列一:Solr(Solr介绍、Solr应用架构、Solr安装使用)
W3Cschool Apache Solr参考指南