Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
配置
先看下$SOLR_INSTALL下的文件
\bin 包括一些能够让solr用起来更容易的重要的脚本,和普通的bin目录的作用是一样的
\contrib 包含一些solr的一些插件或扩展
\dist 包含主要的Solr .jar文件
\docs 包含一个指向Solr在线Javadocs的链接
\example 包含一些展示solr功能的例子
\licenses 包含所有的solr所用到的第三方库的许可证
\server solr应用程序的核心:包含了运行Solr实例和安装好的Jetty servlet容器
- \contexts 包含了solr Web应用程序的Jetty Web应用的部署的配置文件
- \etc 一些Jetty的配置文件和示例SSL密钥库
- \lib Jetty和其他第三方的jar包
- \logs 日志文件
- \modules jetty的启动模式
- \resources Jetty-logging和log4j的属性配置文件
- \scripts cloud-scripts
- \solr 新建的core或Collection的默认保存目录,里面必须要包含solr.xml文件
- \solr-webapp 包含solr服务器使用的文件;不要在此目录中编辑文件(solr不是JavaWeb应用程序)
- \tmp 临时文件
solrconfig基本
查看$SOLR_INSTALL\example\techproducts文件夹下,可以看到这样的文件结构
\logs
\solr
- \techproducts
- \conf
- solrconfig.xml
- ...
- \data
- \index
- ...
- core.properties
- solr.xml
- zoo.cfg
先看下core.properties配置文件,里面只有一行代码name=techproducts,定义了内核的名称,Solr通过这行代码就能自动发现名为techproducts的Solr内核
同时在core.properties中还可以配置一些参数对内核的定义做适当的调整。比如config指定配置文件名称(默认solrconfig.xml),dataDir为包含索引文件与更新日志(tlog)的目录指定路径,ulogDir为更新日志指定路径,schema为模式文档命名(默认schema.xml),shard设置该内核的分片ID,collection为该内核属于的SolrCloud集合名称,loadOnStartup设定在Solr初始化时加载该内核并为该内核开启一个新的搜索器…
solrconfig.xml文件由大量复杂的XML代码块组成。在配置所做的修改需要重新加载内核后才会生效,Solr并不会自动识别配置文件的更改。最简单的方法就是在管理控制台中内核管理(Core Admin)页面的Reload按钮
Lucene版本
<luceneMatchVersion>7.5.0</luceneMatchVersion>
载入相关的jar包,指定了一个路径名与一个用于匹配jar包的正则表达式
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
...
启用JMX,用于激活Solr的MBeans,允许使用一些类似Nagios的常用系统监控工具监控和管理核心Solr组件
<jmx />
搜索处理器
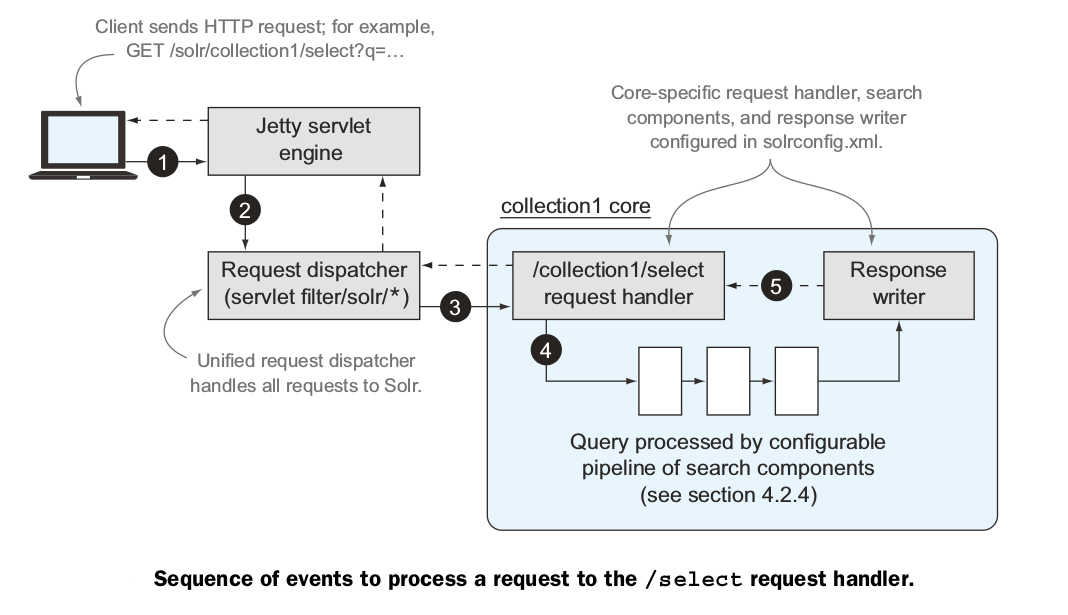 处理流程如下:
处理流程如下:
1、客户端程序提交HTTP GET请求给solr
2、Jetty接收请求,并转发给请求分配器。使用了servlet过滤器:org.apache.solr.servlet.SolrDispatchFilter
3、分配器通过url找到collection对应的内核名称,找到在solrconfig中定义的/select处理器
4、/select处理器使用搜索组件管道处理请求
5、处理完毕后格式化,由response writer返回结果
在solrconfig.xml中对/select请求处理器定义
<!-- 用于处理查询的请求处理器类型,配置文件中利用solr.前缀简写Solr类名称,运行时再解析至对应内置Solr类 -->
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 默认参数列表 -->
<lst name="defaults">
<str name="echoParams">explicit</str>
<!-- 默认页面大小为10 -->
<int name="rows">10</int>
<bool name="preferLocalShards">false</bool>
</lst>
</requestHandler>
搜索处理器结构
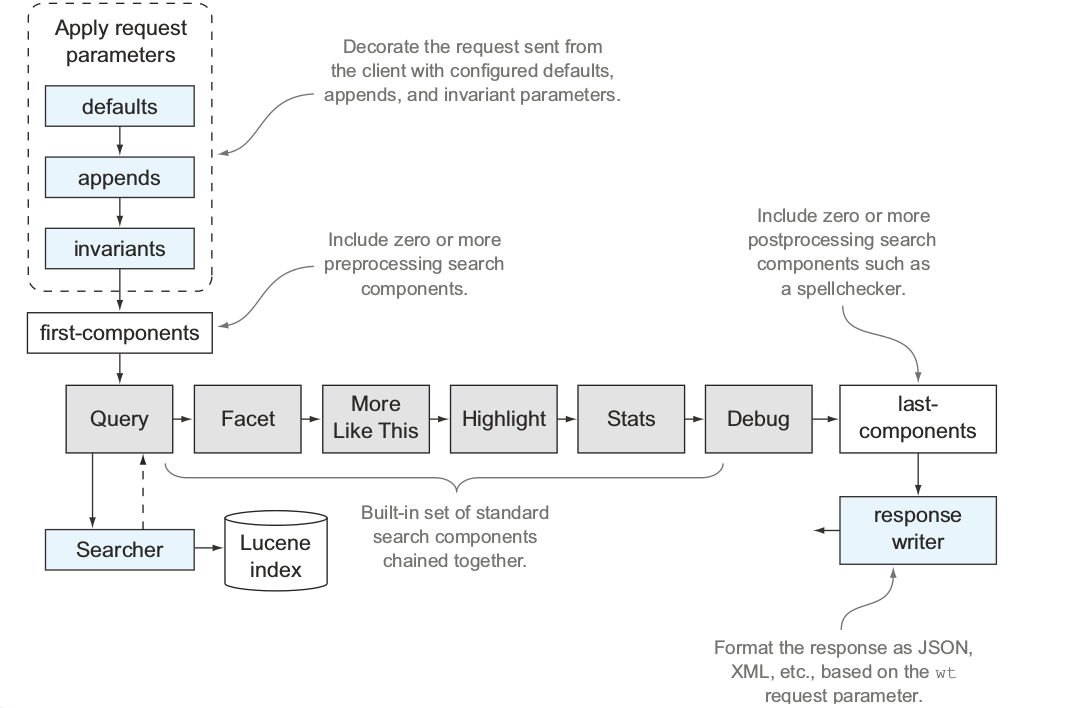 这种设计方式使得应用程序很容易根据实际情况调整solr的查询处理过程。一个搜索处理器由以下组件组成,其中每个组件都定义在solrconfig.xml文件中:
这种设计方式使得应用程序很容易根据实际情况调整solr的查询处理过程。一个搜索处理器由以下组件组成,其中每个组件都定义在solrconfig.xml文件中:
1、请求参数修饰组件:
—— a、 默认值修饰(defaults):为客户端未指定值的参数添加默认值
—— b、 常量修饰(invariants):将客户端的参数值覆写为固定值
—— c、 后缀修饰(appends):在客户端请求的末尾添加额外参数
2、预处理组件(first-components):一组优先执行的可选搜索组件,执行预处理任务
3、主搜索组件(components):一组链式组合的搜索组件,至少包含查询组件
4、后处理组件(last-components):一组可选的链式组合的搜索组件,执行后处理任务
<requestHandler name="/browse" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<!-- VelocityResponseWriter settings -->
<str name="wt">velocity</str>
<str name="v.template">browse</str>
<str name="v.layout">layout</str>
<str name="title">Solritas</str>
<!-- Query settings -->
<str name="defType">edismax</str>
<str name="qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1 cat^1.4
title^10.0 description^5.0 keywords^5.0 author^2.0 resourcename^1.0
</str>
...
<!-- 分页组件 Faceting defaults -->
<str name="facet">on</str>
<str name="facet.missing">true</str>
...
<!-- 高亮组件 Highlighting defaults -->
<str name="hl">on</str>
...
<!-- 拼写检查 Spell checking defaults -->
<str name="spellcheck">on</str>
...
</lst>
<!-- append spellchecking to our list of components -->
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
/browse请求处理器展示了solr中很多强大的特性,可以通过http://localhost:8983/solr/techproducts/browse来使用
搜索组件扩展
查询组件:是solr查询处理过程的核心,查询组件利用处于活跃状态的搜索器对查询语句进行解析与执行。查询语句的解析策略由defType参数指定。查询组件在索引中找出所有符合条件的文档,形成结果文档集。结果文档集可以为随后的查询处理链中的其他组件使用,查询处理器默认启用,其他组件需要指定开启
分面组件:对于给定的结果文档集,如果分面组件被启用了,它将根据字段分面进行结果统计与过滤
更多类似结果组件:启用后,它将识别出与搜索结果集中文档相似的其他文档
高亮组件:如果被启用,它将对结果文档中与查询语句高度相关的文档内容进行高亮表示
统计组件:可以为结果文档中的数值字段计算最小值、最大值、总和、平均值和标准差等简单的统计指标
调试组件:会返回执行过的查询语句解析后的结果,以及结果文档集中每个文档相关度分数计算的详细信息
拼写检查作为后处理组件:在last-components中添加
搜索器管理
query标签包含一些查询性能优化的配置,例如缓存、字段延迟加载和新搜索器预热等技术
solr的所有查询语句都由搜索器的组件searcher完成,在solr中,任何时间只能存在一个处于活跃状态的搜索器。所有搜索请求处理器中的查询组件都向这个处于活跃状态的搜索器发起查询请求。处于活跃状态的搜索器拥有底层Lucene索引快照的只读视图。这意味着如果现将一份文档添加到solr中,它在当前搜索器的搜索结果中是不可见的,只有关闭当前搜索器,打开一个新的搜索器或重新打开,才使新的索引可见,这个过程又称为文档的commit过程。如果用post更新索引,可以在solr管理页面观察到searcher名称的变化,因为post命令在添加文档后执行commit
基于索引开启新搜索器是一个非常耗费系统资源的操作,可能对用户体验造成影响。因此solr允许应用在短时间内提供过期数据,但不允许查询性能有大幅下降。也就是在新搜索器预热完成准备好处理查询前,solr不会关闭当前活跃的搜索器。一般而言,solr有两种预热机制:一种是利用旧缓存自动预热新缓存autowarming;另一种是执行缓存预热查询executing cache-warming queries,缓存预热查询会向搜索器提交一段预先在solrconfig中配置好的查询语句,让搜索器将需要缓存的查询结果载入它的缓存
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<!--
<lst><str name="q">solr</str><str name="sort">price asc</str></lst>
<lst><str name="q">rocks</str><str name="sort">weight asc</str></lst>
-->
</arr>
</listener>
一旦solr中有commit等newSearcher事件发生,这些查询语句就会被执行。需要注意的是:
1、只有识别出能够提高查询性能的查询语句时,搜索器的预热才能真正发挥作用
2、应使用尽量少的warming queries,避免warming过慢,耗费cpu和内存资源
3、first searcher:solr初始化或重新加载完第一个内核后,warming第一个搜索器,是否为第一个搜索器配置预热查询语句完全由开发者决定。大多数solr应用的new和first使用相同的queries查询语句
4、useColdSearch:适用于一个搜索请求已经被提交,而目前solr中没有定义搜索器的情况。默认为false,表示solr将一直处于阻塞状态直到正在预热的搜索器执行完所有的预热查询,true表示立即使用一个正在预热的搜索器进入活跃状态,忽视预热程度
5、maxWarmingSearchers:如果频繁commit且warm时间过长,则会出现当前的新搜索器预热完成之前,另一个搜索器的预热又开始了。这样会有多个searcher同时warming的情况。可以通过maxWarmingSearchers配置最大并发预热数目,一旦打到阈值新的提交请求将会失败,这是一种保障机制,默认为2
缓存管理
solr缓存原理主要涉及:
1、缓存大小及缓存置换法
2、缓存命中率与缓存回收
3、缓存对象失效
4、自动预热新缓存
一般来说,合理的缓存管理方式不是设置完后便抛弃一旁,而是要时刻关注缓存使用情况,基于实际使用情况进行调整
缓存大小CACHE SIZING:
1、不希望缓存设置过大。Solr把缓存放在内存中,需要设置一个缓存上限,否则会消耗JVM中所有内存。solr要求为每个缓存都设置一个缓存对象的数量上限
2、到上限后solr采用最久未使用LRU置换法或最近最少使用LFU置换法回收一部分缓存空间
3、LRU基于对象最后使用的时间进行回收,将置换缓存中最老的对象,即最久未被请求过的对象,是Solr的默认配置
4、LFU基于对象使用的频率,这种置换法给予缓存中使用频率高的对象更高的优先级,而不是最近被请求的对象
5、Cache是对应于searcher的,commit之后cache就失效了,所以即使内存足够大,也不希望cache太大,因为失效后JVM需要做大量的垃圾回收工作
缓存命中率与缓存回收HIT RATIO AND EVICTIONS:命中率是指应用程序的缓存命中的用户占所有用户请求数量的比例。表明了缓存对应用程序性能优化起到的作用。缓存回收数表明有多少缓存对象根据缓存置换法被回收了,如果过大则意味cache的存储上限过小,命中率和回收数是相关的
缓存对象失效CACHED-OBJECT INVALIDATION:Cache中的对象同searcher的生命周期相同,因为所有缓存中的对象都会链接到对应的搜索器实例,并且在搜索器关闭后立即失效
自动预热新缓存AUTOWARMING NEW CACHES:利用即将被关闭的旧搜索器中的部分缓存内容构建新搜索器的缓存
过滤器缓存:过滤器将搜索结果限制在符合过滤条件的文档集中,不影响文档的评分。如果一个过滤条件相同但查询内容不同的查询请求,能利用到之前的查询结果,那么查询效率将大幅提高。过滤器缓存让过滤器在不同查询语句之间可以被复用
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
如果对过滤器缓存管理不当,比如索引了大量文档或过滤条件非常复杂,那么创建和存储过滤器将耗费大量的系统资源。而如果一个简单的过滤查询能被复用与多条查询语句,那这个过滤查询的缓存是有意义的。建议为过滤器缓存启用自动预热功能,因为索引变了,对象不容易从旧的缓存移动到新的缓存,例如filter缓存。缓存中每个对象都有一个key。filter缓存的key就是filter的query语句。自动预热filter缓存实际上就是重新执行filter query。所以自动热身是一个耗费时间和资源的操作。如果对太多的filter自动热身,会耗费大量的时间,因此应该给autowarmCount设置一个较小值为初始值,并使用LFU策略更加合理
查询结果缓存:将查询结果集保存在缓存中,对于消耗大量计算资源的查询来说,直接在缓存中查询而不是重新在Lucene索引执行查询,是一个高效的解决方案
<queryResultCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
原理是将查询语句作为key,内部Lucene文档ID作为value,存储在查询结果缓存中。内部Lucene文档ID会随着搜索器的改变而改变,与searcher生命周期相同,所以在预热查询结果缓存时,缓存的内部Lucene文档ID需要重新计算。因此与过滤器缓存一样,建议将autowarmCount设为一个较小的值
查询结果窗口大小:分页对提高查询性能很重要,queryResultWindowSize允许在执行查询请求时定义单次返回查询结果的页数,默认为20
查询结果缓存的最大文档数:queryResultMaxDocsCached允许对查询结果缓存中每个缓存对象包含的文档数目做出限制,默认为200
启用字段延迟加载:enableLazyFieldLoading为true可以避免载入不用的field
文档缓存:搜索结果缓存只保存文档id,需要读取磁盘来生成结果。文档缓存用来保存文档以供搜索结果缓存使用。如果index更新频繁,solr将不会从这个特性收益。如果index相对稳定,则可以优化性能
字段值缓存:lucene用的缓存,提供了通过内部文档ID快速访问存储的字段值的途径,主要在排序和从匹配文档中生成相应内容时使用,不在solr中配置
总结
solr的查询处理管道,该管道由一个统一请求分配器和一个可灵活配置的请求处理器组成。搜索处理器分为四个组件,每个组件都可以自定义。其中/browse请求处理器是一个使用默认配置参数与自定义组件的典型示例
搜索器基于Lucene索引视图,任何时刻solr中只有一个处于活跃状态的搜索器,并且对Lucene索引的任何更新都需要在重新开启搜索器后才能应用。但是无论关闭还是打开搜索器都需要消耗大量资源,因此使用预热
solr提供了一系列重要的缓存,可以根据应用实际需求做适当的配置
solr还有许多其他特性的专家配置可以使用
扩展:
Solr系列三:solr索引详解(Schema介绍、字段定义详解、Schema API 介绍)