RabbitMQ(一) 基础概念
RabbitMQ(二) 持久化与消息确认
概念
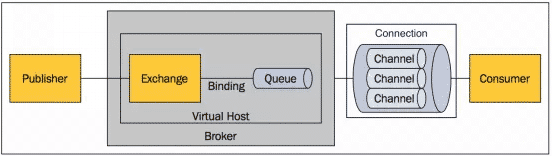
Broker:表示消息队列服务器实体
Virtual Host:虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制。vhost是AMQP概念的基础,必须在连接时指定,RabbitMQ默认的vhost是/
Connection:RabbitMQ的socket连接,它封装了socket协议相关部分逻辑
Channel:信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是定义Queue、定义Exchange、绑定Queue与Exchange、发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接
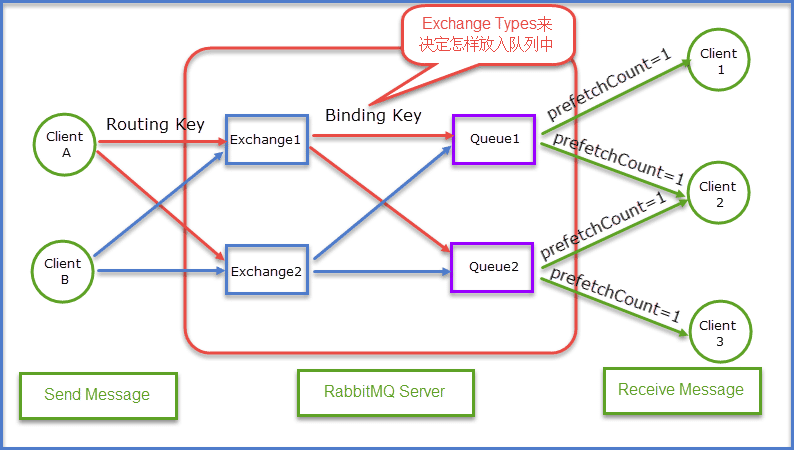
Exchange:生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中(或者丢弃)
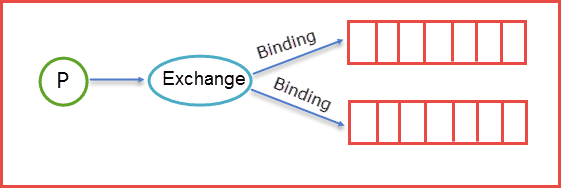
Exchange Types:
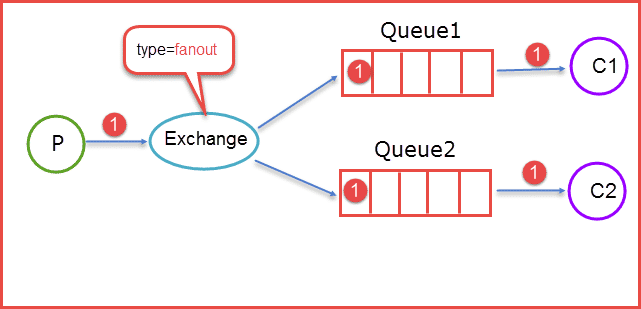
1、fanout:它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中
2、direct:它会把消息路由到那些Binding key与Routing key完全匹配的Queue中
3、topic:在匹配规则上进行了扩展,它与direct类型的Exchage相似,也是将消息路由到Binding key与Routing key相匹配的Queue中,但这里的匹配规则以”.”分隔,并且可以使用”*“与”#”用于做模糊匹配
4、headers:不依赖于Routing key与Binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配
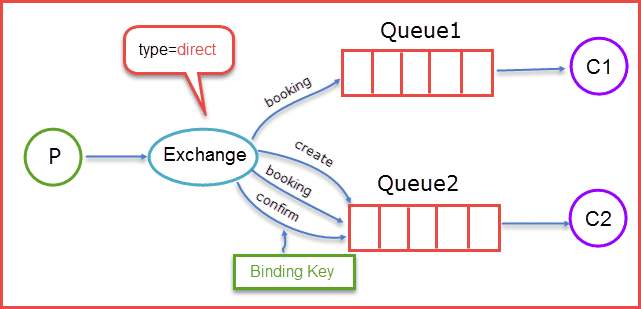
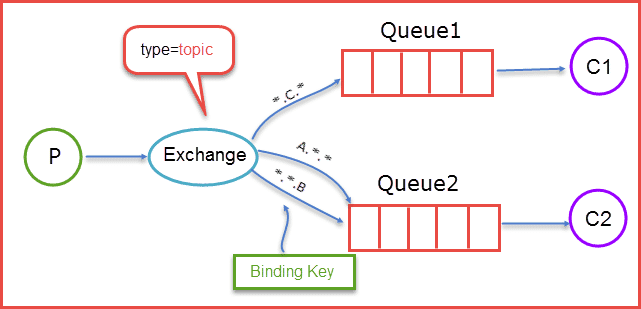
Binding key:在绑定(Binding)Exchange与Queue的同时,一般会指定一个Binding key;消费者将消息发送给Exchange时,一般会指定一个Routing key。当Binding key与Routing key相匹配时,消息将会被路由到对应的Queue中。Binding key的最大长度255字节
Routing key:生产者在将消息发送给Exchange的时候,一般会指定一个Routing key,来指定这个消息的路由规则,而这个Routing key需要与Exchange Type及Binding key联合使用才能最终生效。Routing key的最大长度255字节
Queue:是RabbitMQ的内部对象,用于存储消息,RabbitMQ中的消息都只能存储在Queue中
Message:消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等
Message acknowledgment:在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开
Message durability:希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务
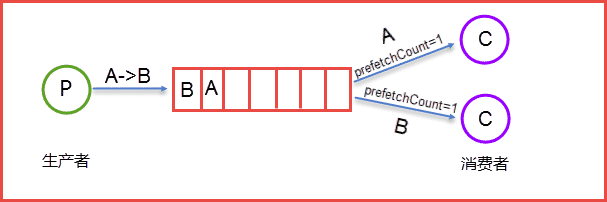
Prefetch count:如果有多个消费者同时订阅同一个Queue中的消息,Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数
特殊设置
设置TTL
设置Time-To-Live过期时间的两种方法:
// 设置队列属性
Map<String, Object> argss = new HashMap<String, Object>();
// ...
argss.put("x-message-ttl",6000);
channel.queueDeclare(queueName, durable, exclusive, autoDelete, argss);
// 设置消息属性,针对每条消息
AMQP.BasicProperties properties = new AMQP.BasicProperties();
properties.setExpiration("60000");
channel.basicPublish(exchangeName,routingKey,mandatory,properties,"test".getBytes());
对于第一种设置队列TTL属性的方法,一旦消息过期,就会从队列中抹去,而第二种方法里,即使消息过期,也不会马上从队列中抹去,因为每条消息是否过期时在即将投递到消费者之前判定的。因为第一种方法里,队列中已过期的消息肯定在队列头部,RabbitMQ只要定期从队头开始扫描是否有过期消息即可,而第二种方法里,每条消息的过期时间不同,如果要删除所有过期消息,势必要扫描整个队列,所以不如等到此消息即将被消费时再判定是否过期,如果过期,再进行删除
死信队列
当消息在一个队列中变成死信(dead message)之后,它能被重新publish到另一个Exchange,这个Exchange就是DLX
消息变成死信一向有一下几种情况:
1、消息被拒绝(basic.reject/ basic.nack)并且requeue=false
2、消息TTL过期
3、队列达到最大长度
DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性,当这个队列中有死信时,RabbitMQ就会自动的将这个消息重新发布到设置的Exchange上去,进而被路由到另一个队列,可以监听这个队列中消息做相应的处理,这个特性可以弥补RabbitMQ 3.0以前支持的immediate参数
channel.exchangeDeclare("some.exchange.name", "direct");
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "some.exchange.name");
// args.put("x-dead-letter-routing-key", "some-routing-key");
channel.queueDeclare("myqueue", durable, exclusive, autoDelete, args);
队列优先级
具有更高优先级的队列具有较高的优先权,优先级高的消息具备优先被消费的特权
// 一个队列queue的最大优先级
Map<String,Object> args = new HashMap<String,Object>();
args.put("x-max-priority", 10);
channel.queueDeclare("queue_priority", true, false, false, args);
// 消息本身的优先级
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.priority(5);
AMQP.BasicProperties properties = builder.build();
channel.basicPublish("exchange_priority","rk_priority",properties,("messages").getBytes());
延迟队列
AMQP协议,以及RabbitMQ本身没有直接支持延迟队列的功能,但是可以通过TTL和DLX模拟出延迟队列的功能
// 创建exchange与queue
channel.exchangeDeclare("exchange_delay_begin", "direct", true);
channel.exchangeDeclare("exchange_delay_done", "direct", true);
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "exchange_delay_done");
channel.queueDeclare("queue_delay_begin", true, false, false, args);
channel.queueDeclare("queue_delay_done", true, false, false, null);
channel.queueBind("queue_delay_begin", "exchange_delay_begin", "delay");
channel.queueBind("queue_delay_done", "exchange_delay_done", "delay");
// 生产者
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.expiration("60000"); //设置消息TTL
builder.deliveryMode(2); //设置消息持久化
AMQP.BasicProperties properties = builder.build();
channel.basicPublish("exchange_delay_begin","delay",properties,message.getBytes());
// 消费者监听queue_delay_done队列
channel.basicConsume("queue_delay_done", false, consumer);
惰性队列
默认情况下,当生产者将消息发送到RabbitMQ的时候,队列中的消息会尽可能的存储在内存之中,这样可以更加快速的将消息发送给消费者。即使是持久化的消息,在被写入磁盘的同时也会在内存中驻留一份备份。当RabbitMQ需要释放内存的时候,会将内存中的消息换页至磁盘中,这个操作会耗费较长的时间,也会阻塞队列的操作,进而无法接收新的消息
惰性队列会尽可能的将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中,它的一个重要的设计目标是能够支持更长的队列,即支持更多的消息存储。惰性队列会将接收到的消息直接存入文件系统中,而不管是持久化的或者是非持久化的,这样可以减少了内存的消耗,但是会增加I/O的使用,如果消息是持久化的,那么这样的I/O操作不可避免,惰性队列和持久化消息可谓是“最佳拍档”。注意如果惰性队列中存储的是非持久化的消息,内存的使用率会一直很稳定,但是重启之后消息一样会丢失
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("myqueue", false, false, false, args);
本文参考:
消息中间件(Kafka/RabbitMQ)收录集
推荐阅读:
官方start