Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
创建索引
solr使用倒排索引查找文档,倒排索引最简单的形式是由词项字典与出现每个词项的文档列表两部分组成。solr使用倒排索引将用户查询中的词项与文档中出现的词项进行匹配
搜索实例
首先需要确定搜索实例core,比如搜索微博,指代那些较短的、非正式的消息与社交网络分享的内容,比如Twitter的推文、Facebook的帖子、Foursquare的签到信息等:
1、先在$SOLR_INSTALL\example\techproducts\solr\创建my_weibo文件夹
2、将$SOLR_INSTALL\server\solr\configsets_default下的conf文件夹复制到my_weibo文件夹下
3、在http://localhost:8983/solr/的Core Admin界面下add一个新的core,取名为weibo,文件路径为my_weibo,这样就创建了一个新的core
假设微博信息有这些字段:id、screen_name、type、timestamp、lang、user_id、favorites_count、text、link等。solr索引中的每个文档由字段组成,每个字段拥有具体类型,字段类型决定了文档如何被存储、搜索与分析。对于开发一个支持百万级别文档与高查询量的大规模系统,索引只用包含用户会搜索的那些字段即可,想象用户会如何使用这些字段来构造索引
从宏观层面上看,solr的索引构建可以分解为3个主要任务:
1、将文档从原始格式转换为solr支持的格式,例如xml或json
2、从良好定义的接口方法中选择一种,通常使用http post,将文档添加到solr
3、在索引中,通过配置solr,对文档的文本进行转换
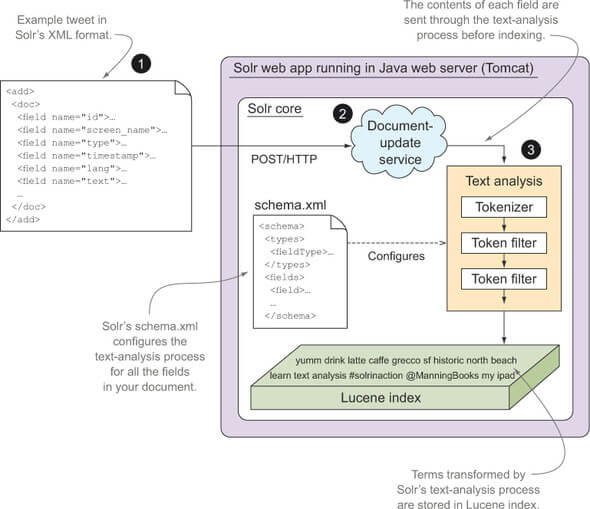
设计schema
文档粒度;索引中的文档需要充分考虑文档粒度对用户搜索体验造成的影响。文档粒度过细会导致用户面对过多的搜索结果
唯一键:一旦确定了待索引的文档构成,接下来就需要确定如何在索引中唯一识别每个文档。solr不要求每个文档都有一个唯一标示符,但是如果提供,solr会将其用于去除索引中的重复文档,solr会用最新的文档覆盖已有的文档
索引字段:接下来需要确定文档中的索引字段(index fields)。索引字段选择的最佳方法是,询问典型用户是否能使用该字段构造有意义的查询表达式。另一种方法是如果搜索表单没有提供该字段的查询,但用户都会提及它,那么这个字段就应该被索引。为了启用搜索,需要对索引字段进行标记,还需要对字段值进行排序、分面、分组、查询建议及执行函数查询等,当启用了特定高级设置时,标记索引字段会有效地提升搜索结果高亮处理效率。从本质上讲,如果搜索结果中不止返回原始的字段值,还需要对字段值进行运算的话,那么大多数情况下都需要索引这个字段
存储字段:一般情况下,文档都包含了一些对搜索本身无用,但是在搜索结果中仍然有用的,这些字段被称为存储字段。索引中每一个存储字段都需要占用磁盘空间,请求CPU和I/O资源来读取存储值,将其返回在搜索结果中。应该谨慎的选择存储字段,尤其对于大规模应用而言。而且设计搜索应用时还需认真思考所需的字段类型
schema
schema文件是在SolrConfig中的架构工厂定义,由于Solr5以后增加了一个新的功能,提供schema API修改分词字段类型,通过schemaFactory来配置选择方式,有两种定义模式:
1、托管模式:默认,也就是当在solrconfig.xml文件中没有显式声明<schemaFactory/>时,Solr隐式地使用ManagedIndexSchemaFactory,它是默认的”mutable”并将模式信息保存在一个managed-schema文件中。当然,也可以显式的声明schema文件,但是当显式的声明schema文件的时候,文件的名字不能是managed-schema也不能是schema.xml。同时schema文件的名字也要与solrconfig.xml中声明的schema文件名一样
2、经典schema.xml:这种模式的配置方式是在solrconfig.xml文件中显式配置一个ClassicIndexSchemaFactory。ClassicIndexSchemaFactory 需要使用schema.xml配置文件,并且不允许在运行时对架构进行任何编程式更改。该schema.xml文件必须手动编辑,仅在加载集合时才加载
注意:
1、两种模式下,schema文件的格式形式不同,默认的托管模式下的schema文件名字必须是managed-schema;而经典的schema.xml模式下schema文件名字必须是schema.xml
2、两种模式下,solrconfig.xml文件中
3、从经典的schema.xml模式切换到默认托管模式,只需要将solrconfig.xml文件中显示配置的
4、从默认的托管模式切换到经典的schema.xml模式,需要先将managed-schema文件重命名为schema.xml,然后在solrconfig.xml中显示的配置
官方文档:Schema Factory Definition in SolrConfig
managed-schema或schema.xml由三个主要部分组成:
1、field和dynamicField元素,用来定义文档的基本结构
2、其他元素,如uniqueKey和copyField,位于fields元素之后
3、fieldType元素下的字段类型包括solr能够处理的日期、数字和文本字段等
<schema> 根节点
<field/> 定义一个document中的各个fields
<dynamicField/> 定义动态字段,为满足前辍或后辍的一些字段提供统一的定义
<uniqueKey/> 指定一个field为唯一索引
<fieldType> 定义field的类型
<analyzer> 自定义fieldType查询时怎么处理
<tokenizer/> 对输入流进行分词
<filter/> 对tokenizer输出的每一个分词,进行处理
</analyzer>
</fieldType/>
<copyField/> 把一个field的内容复制到另外一个field中。一般用来把几个不同的field copy到同一个field中,以方便仅仅对一个field进行搜索
</schema>
field标签:
1、必备字段属性:name名称、type类型属性
2、可索引:indexed=”true”
3、可存储:stored=”true”
4、solr不允许嵌套字段,所有字段都是同级的,也就是一个平面文档结构
<field name="id" type="string" indexed="true" stored="true" required="true" />
<field name="name" type="string" indexed="true" stored="true" />
...
<field name="text" type="text_microblog" indexed="true" stored="true" />
<field name="link" type="string" indexed="true" stored="true" multiValued="true" />
dynamicField标签:
1、可以对文档中一些字段赋予相同的定义,其名称匹配采用前缀或后缀模式,例如s_或_s
2、动态字段有助于解决多字段的文档建模、支持多来源的文档、添加新的文档来源
<dynamicField name="**_ss" type="string" indexed="true" stored="true" multiValued="true" />
copyField标签:
1、复制字段允许将一个或多个字段值填充到一个字段
2、支持两种情况:将多个字段内容填充到一个字段;对同一个字段内容进行不同的文本分析,创建一个新的可搜索字段
<field name="catch_all" type="text_en" indexed="true" stored="false" multiValued="true" />
<copyField source="screen_name" dest="catch_all" />
<copyField source="text" dest="catch_all" />
<copyField source="link" dest="catch_all" />
<field name="text" type="stemmed_text" indexed="true" stored="true" />
<field name="auto_suggest" type="unstemmed_text" indexed="true" stored="false" multiValued="true" />
将text字段的原始文本内容复制到auto_suggest字段,使用unstemmed_text字段类型进行分析
<copyField source="text" dest="auto_suggest" />
uniqueKey标签:
1、如果每个文档都赋予唯一标示符字段,solr将在索引创建时避免产生重复索引,唯一键应使用字符串类型或其他基本字段类型
2、如果计划将solr的索引分发到多台服务器上,那就必须为文档提供唯一标示符
<uniqueKey>id</uniqueKey>
fieldType标签:
1、定义了一些字段类型,其name属性值用于field的type属性的值,class属性中solr是org.apache.solr.schema这个包名的缩写
2、有些时候需要自定义fieldType,使用analyzer表示怎么处理
<fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true" />
<fieldType name="tdate" class="solr.TrieDateField" omitNorms="true" positionIncrementGap="0" />
<fieldType name="int" class="solr.TrieIntField" positionIncrementGap="0" />
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
同样也可以使用Schema API,它是一套REST风格的API,官网的例子为:
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field":{
"name":"sell_by",
"type":"pdate",
"stored":true }
}' http://localhost:8983/solr/gettingstarted/schema
最后,还可以在solr管理页面中的Schema页面中进行操作
发送文档
使用XML或JSON进行文档索引:可以使用post.jar工具将文档发送给solr
使用SolrJ客户端库添加文档索引:
String solrUrl = "http://localhost:8983/solr/techproducts";
HttpSolrClient solrServer = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "012345");
document.addField("cat", "book");
document.addField("name", "test solrJ");
document.addField("price", 12.5);
solrServer.add(document);
solrServer.commit();
打印
SolrQuery query = new SolrQuery("*:*");
// query.set("q", "id:012345");
query.setRows(5);
QueryResponse response = solrServer.query(query);
SolrDocumentList hits = response.getResults();
System.out.println("查询结果总数:" + hits.getNumFound());
for (SolrDocument doc : hits) {
for (String field : doc.getFieldNames()) {
System.out.println(String.format("%s: %s", field, doc.getFieldValue(field)));
}
System.out.println();
}
使用DataImportHandler: 从数据库导入到solr,apache提供了DataImportHandler,一种可配置的方式向solr导入数据,可以全量导入也可以增量导入,还可以声明式提供可配置的任务调度,让数据定时的从数据库更新到solr服务器
1、修改<索引库名>\conf\solrconfig.xml文件,添加DataImportHandler
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
2、在<索引库名>\conf\下创建data-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/test"
user="root"
password="<your password>"/>
<document>
<entity name="weibo" query="SELECT * FROM weibo">
<field column="id" name="id"/>
<field column="screen_name" name="screen_name"/>
<field column="type" name="type"/>
<field column="text" name="wb_text"/>
</entity>
</document>
</dataConfig>
3、在<索引库名>\conf\managed-schema添加新的field内容
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="screen_name" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="type" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="wb_text" type="string" indexed="true" stored="true" multiValued="false"/>
4、将$SOLR_INSTALL/dist下的solr-dataimporthandler-7.5.0.jar,solr-dataimporthandler-extras-7.5.0.jar与相应数据库的jar包我的是mysql-connector-java-5.1.41.jar复制到$SOLR_INSTALL\server\solr-webapp\webapp\WEB-INF\lib下
5、在控制台的Dataimport页面下,点击Execute进行导入
注意:增量导入还需要在data-cofig中配置pk、deltaQuery、deltaImportQuery
ExtractingRequestHandler(Solr Cell):可以抽取二进制文件中的文本(pdf、Office等)内容进行索引
Nutch:基于Java的开源网络爬虫,与solr无缝集成,通过Nutch采集网页,然后solr实现采集到的网页可被搜索
更新处理器
通常情况下,更新处理器负责索引的所有更新请求,包括提交与优化请求。更新处理器常见请求有:add、delete、commit、optimize。在solrconfig中已经配置了updateHandler,更新处理器最重要的任务是文档提交到索引的请求,并让这些文档可以被搜索
正常提交:正常提交(硬提交)是将所有未提交的文档写入磁盘,并刷新一个内部搜索器组件,让新提交的文档能够被搜索。搜索器实际上可以看做索引中所有已提交文档的只读视图。硬提交是花销比较大的操作,由于硬提交需要开启一个新搜索器,会影响到查询性能
软提交:支持近实时搜索。软提交作为文档近乎实时可被搜索的机制,跳过了硬提交的高消耗,列入刷新到持久存储器就是花销较大的操作。软提交相对花销较低,可以每一秒都执行一次软提交,使新近被索引的文档在添加到solr之后很快被搜索到。但是在某一时刻,仍然需要执行硬提交操作,以确保文档最终写入到持久存储器上
自动提交:不论是正常提交还是软提交,都可以采取三种方式来自动提交文档:1、在指定时间内提交文档;2、一旦打到用户指定的未提交文档阈值就提交;3、每隔特定时间间隔提交所有文档。可以在solrconfig中通过配置autoCommit来实现
事务日志:solr使用事务日志来确保提交到索引并已接受的更新保存在持久存储器。事务日志主要由三个作用:1、支持近实时获取和原子更新;2、解除提交过程中写入的持久性;3、通过SolrCloud的分片代表支持副本的同步。每次更新请求都会被记录到事务日志,直到发起提交,事务日志会持续增长
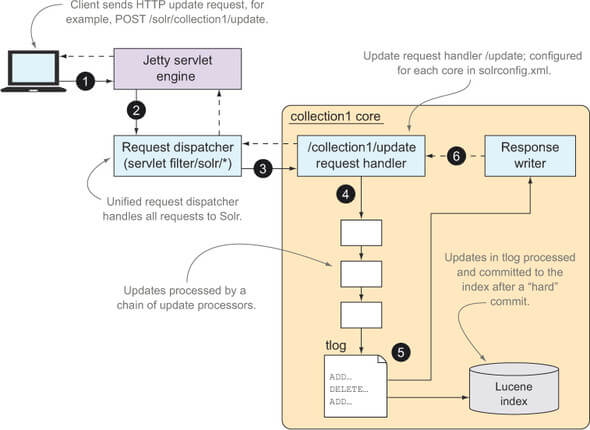 1、客户端应用程序使用HTTP POST发送一个更新请求
1、客户端应用程序使用HTTP POST发送一个更新请求
2、Jetty将此请求发送给Solr的Web应用程序
3、Solr的请求调度器通过请求路径中的”collection”来确定solr内核名,然后调度到/update请求处理器
4、更新请求处理器对该请求进行处理。当添加或更新文档时,处理器根据schema一次处理请求中每个文档的每个字段,同时调用一个课配置的更新处理链
5、ADD请求写入到事务日志中
6、一旦更新请求被安全保存到持久存储器,就会通过响应读写器回应客户端应用
原子更新:通过发送文档的新版本可以实现对已有文档的更新,solr会更新整个文档,因为solr会先删除文档然后创建一个新的文档。而原子更新是solr的一项新功能,通过它尅实现仅对需要修改的字段进行更新,让solr更符合数据库的更新操作。具体是在doc的对应field加上update属性,这时候只要传id和需要修改的字段,虽然还是删除已有文档重新创建,但是其他字段会从原文档中读取出来
并发控制:solr通过版本跟踪字段_version_来支持积极的并发控制,在schema中有
索引管理
当文档提交到索引后,directory目录组件将它们写入到持久存储器。在solrconfig中可以使用dataDir元素定位data目录<dataDir>${solr.data.dir:}</dataDir>,solr.data.dir属性是内核默认数据目录,可以在solr.xml中修改
一旦解决了存储方面,还需要考虑存储方案的最佳目录方案。solrconfig使用<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/>配置,NRTCachingDirectoryFactory用来添加对近实时搜索的支持,运行时根据操作系统与JVM类型来选择一个具体的目录方案
索引片段:是Lucene完整索引的子集,具有自包含与只读特点。索引片段写入持久存储器后,它就无法再更改。向索引添加新文档时,它们被写入一个索引片段中,因此索引里可能存在许多活动的索引片段。每个查询必须读取了全部索引片段的数据,才能得到完整的搜索结果集。因此过多的小片段会对查询性能造成负片影响
将多个小索引片段合并成大索引片段的做法成为索引片段合并。默认情况下,有关索引片段合并的设置在solrconfig中被注释掉了,因为默认设置适用于大多数情况。虽然专家级设置被注释掉了,但仍然能在后台进行索引片段合并操作,因此除非有足够的理由修改这些设置,否则不对此做优化
当索引片段写入持久存储器后就不能更改了,所以删除并不是从已有的索引片段中删除文档。删除的文档不会从索引中消失,除非包含删除的索引片段被合并。Lucene将删除操作记录在一个单独的数据结构中,合并时执行这些删除操作
文本分析
文本分析消除了索引词项与用户搜索词项之间的语言差异,如果配置恰当,文本分析就能允许用户使用自然语言进行搜索,而无需考虑搜索词项的所有可能形式。文本分析不仅用于消除词项之间的表面差异,还用来解决更为复杂的问题,比如特定语种解析,部分词项标注与词形还原等。Solr包含了一个文本分析可扩展框架,提供了强大的功能和灵活的扩展性。solr在示例schema文件中预置了许多字段类型,确保在接触开箱即用的solr时,可以容易地开始使用文本分析
文本分析的基本元素,包括分析器、分词器与分词过滤链
基础文本分析
如果所有字段都是结构化数据,那么关系型数据库更加适合对结构化数据进行索引与搜索。非结构化文本才是solr擅长的,示例schema中预定义了很多有用文本分析字段类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
分析器
在fieldType标签中至少定义一个analyzer,以确定如何分析文本。常见的做法是定义两个单独的analyzer元素,一个用于分析索引index时的文本,一个用于分析用户搜索query时输入的文本。text_general字段类型就用了这种方式,对索引文档与查询处理进行文本分析,通常后者需要进行更多的分析,例如查询的文本分析中通常会添加同义词等
虽然可以定义两个单独的分析器,但是查询词项的分析器必须兼容索引时的文本分析方式
分词器
在solr中每个analyzer将文本的分析过程划分为两个阶段:语词切分(解析)和语词过滤,严格说还有语词切分前的预处理阶段,这个阶段可以使用字符过滤器
在语词切分阶段,文本以各种解析形式被拆分为词元流。WhitespaceTokenizer是最基础的分词器,仅适用空格拆分文本,StandardTokenizer则更为常见,它使用空格和标点符号拆分出词项,而且可用于处理网址、电子邮箱和缩写词。分词器的定义需要指定java实现的工厂类,因为大部分分词器需要提供参数构造器,所以必须指定为工厂类,而不是底层的分词器实现类
分词过滤器
分词过滤器对词元执行以下三种操作中的一种:
1、词元转换:改变词元的形式,例如所有字母小写或词干提取
2、词元注入:向词元流中添加一个词元,例如同义词过滤器的做法
3、词元移除:删除不需要的词元,例如停用词过滤器的做法
过滤器可以链接在一起,对词元进行一系列的转换处理,过滤器的顺序很重要
StandardTokenizer
这个分词器是许多solr与lucene项目的首选解决方案,使用空格和标点符号来拆分文本,这点做的很好,还能轻松地处理首字母缩写词和缩略词
具体说,StandardTokenizer提供一下功能:
1、通过空格、标准的标点符号拆分文本
2、保留互联网域名与电子邮件地址,分别作为单个词元
3、连字符词项拆分成两个词元,例如i-Pad会被拆分为i和Pad
4、支持可配置的最大词元长度属性,默认255
5、从主体标签和提及符号中去除#号和@号和@号
然后看下solr提供的用于基础文本分析的几种常见分词过滤器
StopFilterFactory:用于移除词元中的停用词,这些停用词对用户查找相关文档几乎没有价值,还能有效减小索引大小,提高搜索性能。可以指定停用词列表,在各个core内核conf/的子目录/lang有solr提供的多语言停用词列表
LowerCaseFilterFactory:将词元的所有字母转换为小写。大多数情况下需要使用小写转换过滤器,但在过滤链的哪个环节使用需要认真考虑
文本分析测试:在solr控制台,选择Analysis页面,可以在输入文本并选择字段类型后,单击Analyse Values来查看分析结果
其他
可以使用自定义的fieldType,为analyzer配置对应的tokenizer和filter
PatternReplaceCharFilterFactory:使用正则表达式进行字符替换,要配置这个java工厂,需要定义pattern和replacement两个属性
HTMLStripCharFilterFactory:从文本中去除HTML标记
WorldDelimiterFilterFactory:对WhitespaceTokenizer简单根据空格对文本拆分,做了有效补充,解决了空格拆分导致的大多数问题。该过滤器在更高层面上使用各种解析规则,将分词单元变为子语(subwords),与StandardTokenizer不同,它提供了一种简单的方法,使用一个”类型”映射文件来指定哪些字符可以作为文本分隔符
KStemFilterFactory:词干提取根据特定语言规则,将词转换为基础词形。solr提供了许多词干提起过滤器,各有优缺点。KStemFilterFactory比其他PorterStemmer等流行词干提取器相比不是那么激进
SynonymFilterFactory:为重要词项加入同义词,这个过滤器只对查询阶段有效,这样做可以有助于减少索引的大小,同义词列表的变更维护也会容易些
高级字段属性
field标签可以设置一些高级属性
忽略字段规范化:规范是基于文档长度规范、文档权重和字段权重三者的浮点值。底层的Lucene将这个浮点值变为为单字节。比如文档长度规范用来提升短文档,因为同样一个词出现在短文档和长文档,词项在短文档中权重更高,所以Lucene认为短文档比长文档更相关一点。如果文档长度相似且没有在索引阶段使用字段提升和文档提升,可以设置omitNorms="true",以节省内存
词向量:solr使用词向量计算文档与查询之间的相似度,还提供文档之间的相似度计算功能,通常称为更多类似结果,可以在索引中查找与指定文档非常相似的文档。任何文档的词向量可以在查询阶段使用索引中存储的信息进行计算,为了更好的性能,词向量可以在索引时预先计算和存储下来。所以如果打算使用更多类似结果的功能,可以设置termVectors="true"让每个词向量在索引时存储
各语种文本分析
实际上之前列出的大多数文本分析方案都适用于英语,而不一定适用于中文。每种语言都有各自的分词规则、停用词列表和词干提取规则。一般来说,需要为索引分析中的每种语言设计一个专门的fieldType字段
假如要索引所有文档,不考虑索引中不同语种情况,一种简单的做法就是为每个语种使用一个唯一的字段,比如<field name="text_cn" type="text_microblog_cn" indexed="true" stored="true">,然后为text_microblog_cn配置一个fieldType
在$SOLR_INSTALL\contrib\analysis-extras\lucene-libs\下可以找到lucene-analyzers-smartcn-7.5.0.jarsmartcn中文分词器JAR包,将其放到solr服务器WEB-INF\lib\下,然后在${collection}\conf\managed-schema中配置fieldType
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
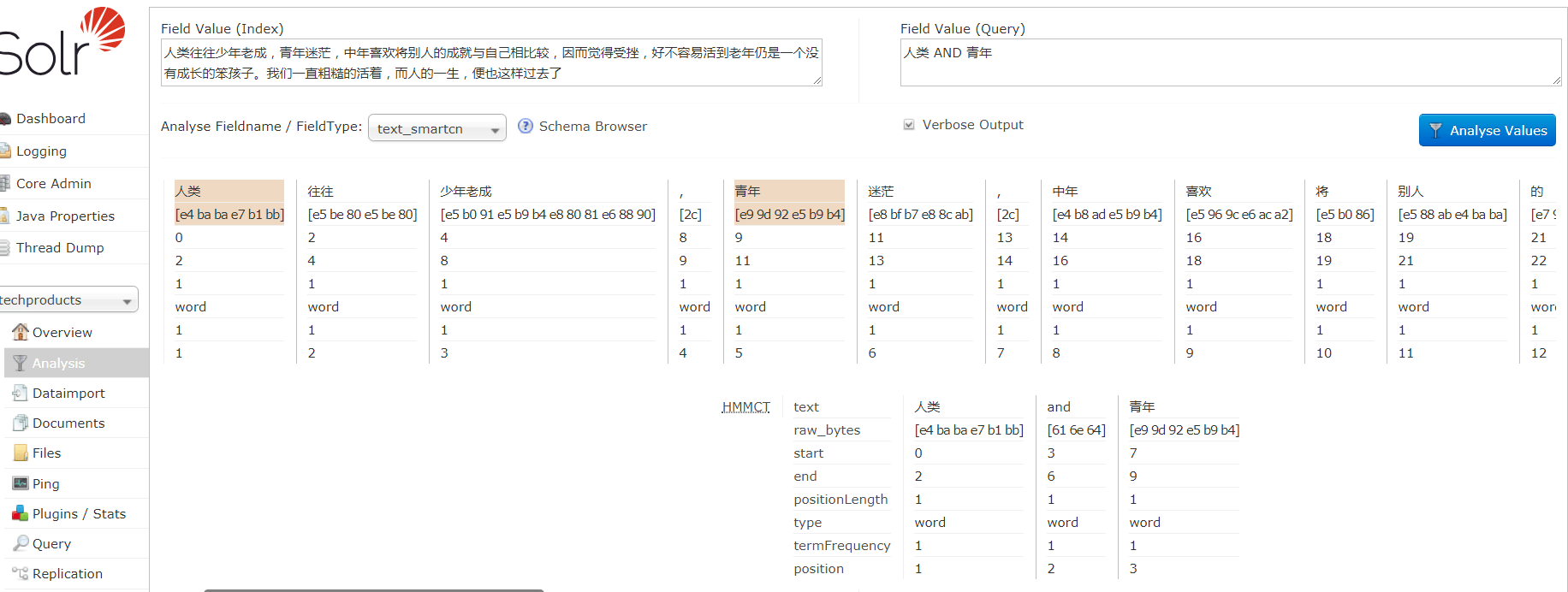 可以发现这个分词器比较一般,其他还有比如IK Analyzer中文分词器、IK拼音分词器
可以发现这个分词器比较一般,其他还有比如IK Analyzer中文分词器、IK拼音分词器
如果solr的内置工具无法解决文本分析问题,solr的插件框架可以用于构建应用专属的文本分析组件。之前提到,solr文本分析包含以下组件:分析器Analyzer、字符过滤器CharFilter、分词器Tokenizer与分词过滤器TokenFilter。分析器Analyzer将分词器Tokenizer和分词过滤器链TokenFilter组合成一个组件。大多数时候我们不需要替换掉整个Analyzer,而是希望利用已有的分词器和过滤器链。除非有必要,否则不要重新定义分词器
自定义TokenFilter类:
1、自定义过滤器继承自TokenFilter
2、实现调用方法,在分词流中处理每个词元
3、编写一个工厂类,实现TokenFilter的实例化,继承自TokenFilterFactory
4、在schema中定义filter,class为对应工厂类
5、将包含插件类的所有JAR文件放在solr初始化时能找到的位置。比如放在新建文件夹/plugins中,将该地址添加到solrconfig中。这样启动solr服务器时,plugins中的所有JAR文件都可以通过solr的ClassLoader加载
扩展:
Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)