Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
分面搜索
与传统数据库与其他NOSQL数据存储相比,分面是solr最强大的功能之一,分面搜索也称为分面导航或分面浏览,它允许用户在执行搜索时,根据文档的一个或多个方面(即分面)对搜索结果进行细分。用户通过选择不同过滤器来探索搜索结果。比如搜索新闻时,希望搜索结果按时间选项(前1小时、过去24小时、上一周),或者类别(政治、体育、娱乐、商业)进行过滤。搜索求职网站时希望搜索结果按城市、工作类别、行业甚至公司名等选项进行筛选。solr的分面功能将动态元数据随着搜索结果集一起返回。分面最基本的形式是展示字段中的每个唯一值,这个字段来自于许多文档共享的属性,例如类目列表
分面搜索一般分为两个步骤:分面的计算与显示,即分面返回;用户选择一个或多个分面值,对搜索结果进行过滤,即分面选择或分面过滤。分面可以看成是描述搜索结果的一个信息切片,分面会对每个搜索结果集(或从重复搜索的缓存中取回的结果)进行实时计算。每个分面返回一个分面值列表,同时统计出分面值包含的文档数。由于一个分面值可能在同一个文档中多次出现,所以统计数字不是该分面在所有文档中出现的次数,而是匹配到的文档数。实际上,所有分面值是根据搜索结果集进行计算的,这意味着,每当有新搜索,每个分面返回的值和计数都不同。用户执行搜索,查看搜索结果返回的分面,通过感兴趣的分面值对搜索集进行过滤,从而执行另一个搜索
分面会大量使用solr缓存,因此需要对solr内置缓存的使用方式进行优化,以期最大限度发挥分面请求的性能。除此之外还有一种高级分面,透视分面,提供了高纬度的分面功能
现示例一个展示城市餐馆的文档,有字段id、name、city、state、tags、price
分面方式
字段分面
执行搜索时,根据查询请求返回特定字段中找到的唯一值以及找到的文档数,例如展示餐厅名(name)分面、餐馆类型(type)分面、标签(tags)分面。那么可以执行/select?q=*:*&facet=true&fact.field=name或者/select?q=*:*&facet=true&fact.field=tags。需要注意的是,分面时,字段分面的返回值是基于该字段的索引值,因此字段会被作为文本字段进行分词
分面参数:facet对当前搜索开启或关闭所有分面。fact.field确定对哪个字段进行分面计算,可以多次指定以返回多个分面。facet.limit确定每个分面返回多少个唯一的分面值。facet.mincount在分面值返回前设置必须出现的最小文档数。facet.prefix指定字符串开头的词项来限制分面值等。如果指定多个facet.field参数,可以在一些分面参数应在字段级别上,语法为f.<fieldName>.<FacetParameter>=<value>
比如对20个城市进行分面,至少有一家餐馆,并且要显示餐厅名(即使餐厅名与查询并不匹配)以及匹配到的前5个标签,则可以执行/select?q=*:*&factet=on&factet.field=city&f.city.factet.limit=20&f.city.facet.sort=index&factet.field=name&f.name.factet.mincount=1&factet.field=tags&f.tags.factet.limit=5
查询分面
多个子查询通过查询分面可以组成一个solr请求,例如基于价格的分面:/select?q=*:*&rows=0&facet=true&facet.query=price:[* TO 5}&facet.query=price:[5 TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *],基于任意查询的分面具有非常大的灵活性,但它们也可能对solr请求造成负担,因为分面计数的生成说依赖的单一值都必须明确指定
区间分面
区间分面将数值和日期字段值分成一些区间段,一遍solr返回各个区间以及它们包含的文档数。创建多个不同的查询分面来表示多个区间值的做法,可以用区间分面很好地代替。例如/select?q=*:*&facet=true&facet.range=price&facet.range.start=0&facet.range.end=50&facet.range.gap=5,区间分面返回了在start与end间每个分段的统计数,gap设置了区间间隔。区间分面还有其他一些参数可以选择,比如facet.range.hardend、facet.range.other和facet.range.include。与字段分面一样,区间分面的一些参数使用f.<fieldName>.<FacetParameter>=<value>在字段上指定
基于分面值的过滤
为了让用户根据分面对搜索结果进行搜索,solr返回分面只是第一步。向用户展示分面后,下一步是让用户点击一个或多个分面值,将其作为过滤器使用
分面过滤
与向查询中添加额外的过滤器(fq参数)相比,在分面上使用过滤器没那么困难:
用户第一次:
/select?q=*:*&facet=true&facet.field=name&facet.field=city&facet.query=price:[* TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *]
第二次选择了city:hangzhou:
/select?q=*:*&facet=true&facet.field=name&facet.field=city&facet.query=price:[* TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *]&fq=city:hangzhou
随后又对价格进行了第二个过滤器:
/select?q=*:*&facet=true&facet.field=name&facet.field=city&facet.query=price:[* TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *]&fq=city:hangzhou&fq=price:[* TO 20]
对于单一值字段的分面都是没问题的,然而并不是所有字段都包含单一值,schema文件中字段被标记为多值或要被分词,这两种情况都会分面产生多个词项。当按上面的方法对多值字段进行分面过滤时,显然会因为只要包含过滤值的文档仍然可以匹配所用的过滤器,但是该文档的其他值也会继续返回
对于单一值字段的分面还需要注意短语需要用”引号括起来,一些特殊符号需要进行转义。而且由于基于文本分析在内容索引和查询两个阶段可以分别定义,因此如果配置存在匹配失误,尝试过滤的值和分面返回的文档数不一致。使用词项查询解析器可以确保分面返回值和随后的过滤器值两者找到准确一直的文档。使用词项查询解析器的好处在于绕过了字段上已定义的文本分析链,直接将词项与solr索引进行匹配,节省了文本处理时间,并且避免了引号和转义逻辑等问题。对所有分面过滤器使用词项查询解析器有一个缺点,即它不支持布尔语法,因此要在一个过滤器里组合多个分面值,需要使用嵌套查询语法
两种方法:
1、分别为每个词项使用过滤器
/select?q=*:*&facet=true&facet.mincount=1&
facet.field=name&facet.field=tags&
fq={!term f=tags}coffee&fq={!term f=tags}hamburgers
2、通过词项查询解析器把这些分面词项组合成一个过滤器
/select?q=*:*&facet=true&facet.mincount=1&
facet.field=name&facet.field=tags&
fq=_query_:"{!term f=tags}coffee" AND _query_:"{!term f=tags}hamburgers"
其中fq=coffee&fq=hamburgers可以转换为fq=tags:(coffee AND hamburgers)或其他等价的布尔逻辑表达式
多选分面、键与标记
查询分面的分面名称是基于分面值和计数的查询本身,使用键这个局部参数可以方面地对分面进行重命名:
/select?q=*:*&facet=true&facet.mincount=1&
facet.field={!key="Location"}city&
facet.query={!key="<$20"}price:[* TO 20]&
facet.query={!key="$20 - $50}price:[20 TO 50]&
facet.query={!key=">$50"}price:[50 TO *]
分面重命名使用于很多应用场景。它允许搜索应用请求查询分面,比如在后置处理阶段不需要搜索应用对结果集的查询进行解析。还能为分面赋予易于理解的名称,不管分面的底层字段和查询怎样,让搜索界面上的结果更加直观。每个分面名称是唯一的,通过键指定,在相同字段上可以定义不止一个分面,返回的每个分面都有唯一的名称。这种方法的有点是,根据查询阶段的规则,它可以让多个字段映射成同一个名称
默认情况下,选择一个分面过滤后,分面值不在包含已过滤掉的文档。如果希望让用户在搜索中选择多个分面值,由于分面过滤掉的值不再出现在选线中,所以无法使用逻辑或(OR)来得到这个值。solr提供分面排除功能来解决这个问题。分面排除可以添加被搜索请求中任何过滤器过滤掉的文档。将过滤掉的文档数计入分面数,这样就可以对每个分面进行有效统计,又同时忽略该分面上已使用的过滤器。tag与ex是实现这个方法的两个必要参数:
/select?q=*:*&facet=true&facet.mincount=1&
facet.field={!ex=tagForName}name&
facet.field={!ex=tagForCity}city&
facet.query={!ex=tagForPirce}price:[* TO 20]&
facet.query={!ex=tagForPirce}price:[20 TO 50]&
facet.query={!ex=tagForPirce}price:[50 TO *]&
fq={!tag="tagForCity"}city:hangzhou
这样过滤器将city限定在hangzhou,但是与查询其余部分想匹配的文档数依然按每个城市返回,而不仅仅是hangzhou的文档数。然后其他分面不会忽略city:hangzhou上的过滤器
就查询机制而言,tagForCity作用于hangzhou的过滤器,实现的语法为fq={!tag=”tagForCity”}city:hangzhou。当请求城市分面时,排除所有标记为tagForCity的过滤器,实现语法为facet.field={!ex=tagForCity}city
需要注意的是,其他分面(比如state、price)也可能包含排除标记,当它们没有与任何标记过的过滤器对应。这些排除标记不是必需的,它们不会造成什么问题,也可以被忽略
结果高亮
预配置高亮
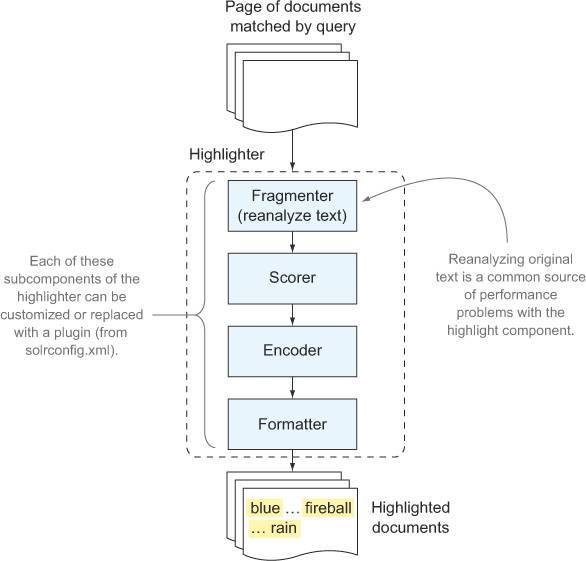
高亮是solr的核心功能之一,也是几乎所有搜索应用必备的一个重要功能。可以实现简单的基本高亮:/select?q=blue&wt=xml&hl=true使用hl开启内置搜索结果高亮搜索组件。solr返回的高亮片段在一个单独的元素lst中,因此必须处理这些信息才能对其进行高亮显示
高亮组件支持多种配置参数的微调。在某些情况下,每个结果高亮显示一个片段,可能不足以为用户提供足够的上下文信息,让他判断这个结果是否值得进一步研究。因此可以使用hl.snippets=2允许每个文档最多高亮显示两个片段。通过设置hl.fl参数,高亮组件能知道对文档哪些字段进行高亮显示,如果没有设置那么solr将回退到通过df参数设置的默认查询字段
 文本分析 - 分段(Fragmenting) - 评分 - 编码与格式
文本分析 - 分段(Fragmenting) - 评分 - 编码与格式
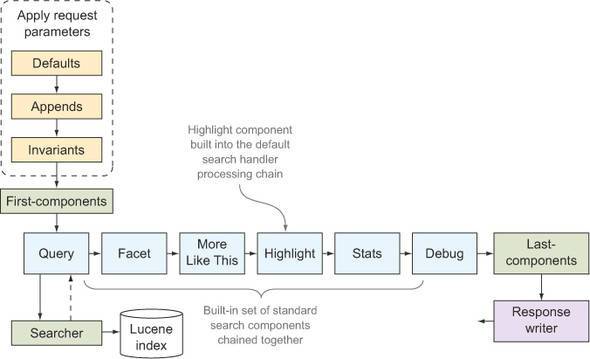
在solrconfig.xml中定义了默认的高亮搜索组件的XML定义。高亮组件位于查询处理链的下游,因此高亮组件每次只能对一页搜索结果进行高亮处理,因此如果使用一个较大的页面大小,那么每次请求中高亮组件的处理量很大,会对响应时间造成负面影响
其他高亮组件
FastVectorHighlighter组件:在生成片段时,跳过了分析步骤,因此比默认高亮组件速度更快,提升了性能
PostingsHighlighter组件:比默认组件快,而且无须FastVectorHighlighter组件的词向量开销,它依赖倒排索引中的倒排信息的词项偏移量。相比之下,FastVectorHighlighter组件需要在索引中有一个单独的数据结构,用于检索词项位置和偏移量,而PostingsHighlighter组件可以从倒排列表中直接访问这些信息。需要在schema中的field标签中添加storeOffsetsWithPositions="true",然后在solrconfig中配置对应的<searchComponent><highlighting/></searchComponent>,需要注意的是需要在solrconfig中删除已有的高亮组件定义或默认高亮组件定义
除了在速度和减少开销上有优势,PostingsHighlighter组件还为片段评分采用了更先进的相似度计算方法 —— MB25。PostingsHighlighter组件的主要缺点就是它要求在索引构建过程中设置精确的词项偏移量
查询建议
查询包括一个或多个拼写错误的词导致结果中得到不相关的内容,搜索引擎应当自动执行查询建议,但当用户对索引中不存在的词项进行搜索时,显然solr找不到相关文档,也无法做出有用的查询建议。拼写检查不需要在查询中传入参数,因为拼写检查组件已经集成在solrconfig定义的默认/select请求处理器中,查询建议是默认启用的核心功能,如果不希望启用,设置spellcheck=false即可。拼写检查组件在最后执行,如果设置spellcheck.collate=true启动校对,拼写检查组件则必须列为后处理模块
同样拼写检查也可以设置参数,可以在solrconfig中对searchComponent进行设置,默认拼写检查组件是DirectSolrSpellChecker组件,它根据主查询直接提供建议。其中最重要的三个参数是:field参数指定索引中用于提供建议的字段,distanceMeasure参数告诉solr如何确定查询词的建议,accuracy参数确定了查询建议需要的准确度
上面说到,如果用户输入错误比如没有在关键词间输入空格,导致solr没有查询出文档,那么就无法做出拼写建议。这种情况可以使用WordBreakSolrSpellchecker组件将查询词分成多个部分,然后在索引中查找分开后的词项,从而提供正确的查询建议。例如/select?q=...&spellcheck.dictionary=wordbreak&spellcheck.dictionary=default同时使用默认拼写检查组件和wordbreak拼写检查组件来提供一个准确的查询建议
自动建议查询词
自动建议的用户界面很简单,就是一个根据用户输入显示的建议列表,每增加一个字符都会改变建议列表。一般情况自动建议功能需要满足:1、速度快,跟上用户的输入节奏 2、根据词频顺序返回排名建议
/select不是处理自动建议的最佳途径,一方面/select已有拼写检查支持,另一方面不需要内置的组件(比如query、facets、highlighting)。solr专门设计了自定义的请求处理器,用来封装简单界面背后的复杂行为。在solrconfig中定义一个requestHandler,class为SearchHandler,配置spellcheck参数,在components里覆盖内置的组件管道,例如suggest。然后定义一个searchComponent,class为SpellCheckComponent,名称为suggest,设置相关参数,例如lookupImpl为FSTLookupFactory
主题建议组件匹配的主题并不一定必须在开头,只要出现就能生成建议。一种实现是使用通配符,但是执行速度很慢,而且通配符也无法控制返回文档的排序。更好的一种方法是,在文本分析过程中对每个词创建边缘(edge)n-grams。n-gram是由一个档次或字符串生成的连续字符序列,其中n表示序列的长度。使用中在schema中的fieldType中进行配置,设置EdgeNGramFilterFactory,然后在solrconfig中配置一个requestHandler
基于用户活动提供查询建议
当用户输入时,执行最可能的查询,该查询选自于最近热门查询数据库。solr的实现与n-gram配置类似,还需要对一个solr次索引进行查询,该索引包含来自查询日志的用户查询,而不是去匹配主索引字段。需要有一个查询日志分析工具,计算每个查询的热门程度得分,更新热门程序得分,纳入新的查询分析
结果分组
结果分组也是solr中非常有用的功能之一,它能确保针对用户的查询返回最佳搜索结果,结果分组也称为字段折叠,能针对一个字段里的唯一值(当前的实际值或动态计算的值)只返回一份文档(或者有限数量文档)。solr结果分组不仅可以对一个字段的重复值进行折叠并返回单一结果集,即字段折叠,还可以对单个查询返回多个结果集或者分组
比如在网上购物,搜索商品时可以在结果中看到成千上万个结果,但是针对单个商品只显示一份文档(连同该商品的数量)也许能提供更好的用户体验,那些单个商品的复制品或不同卖家,它们的内容一样,相关度得分也相同,那么可能前面N条都是它们,相反如果根据商品名称对结果进行分组,要求每个组只出现一件商品,那么用户也能看到其他的可能性商品结果。大多数情况下,使用结果分组功能对搜索结果进行折叠能提供更好的用户体验
开启分组功能,使用/select?fl=id,product,format&sort=popularity asc&q=tv&group=true&group.field=product&group.limit=1,通过在product字段上开启分组功能,且每组仅返回一个最相关的文档。group.field支持多个字段分组,返回多组结果。如果不需要每组折叠的数量,可以使用group.main=true参数将所有组折叠起来后放入主搜索结果中。还有一种介于高级分组格式(默认)和group.main格式之间的选择–简单分组格式,通过指定group.format=simple,返回多组结果,也能像main那样以扁平化清单列表方式返回每组请求的结果。实际上,从实现的角度看,设置group.main=true参数使用的是group.method=simple功能,并能在主要结果清单中返回最后指定的组
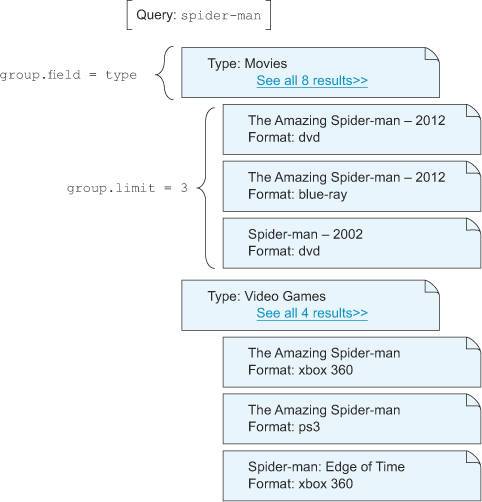
每组返回3个文档,每次最多返回5组:/select?q=spider-man&group=true&group.field=type&group.limit=3&rows=5&start=0&group.offset=0,group.offset参数通过每组里的文档数量控制分页大小
按函数和查询对结果分组
按函数进行分组:
基于函数的分组功能是借助group.func参数来完成的,例如/select?q=...&group=true&group.limit=3&rows=5&group.func=map(map(map(popularity,1,5,1),6,10,2),11,100,3),所有受欢迎程度的值被映射到三个分组上,受欢迎度1~5的映射到组1,受欢迎度6~10的映射到组2,受欢迎度11~100的映射到组3。函数时可以嵌套的,可以结合多个函数来全面控制所有计算出来的值
按照查询进行分组:
solr除了可以将预定义的字段值进行分组,还可以按任意查询进行动态分组。例如对以顾客为中心的用户体验进行高度定制化,返回三个搜索结果集:在用户地理位置50km范围内的商品,在顾客可接受价格区间之间的商品,以及顾客偏爱种类范围内的商品。因为solr允许在同一个查询请求中发送多个group.query参数,所以可以将这些结果集以单个分组的形式返回。例如按匹配所有movie,匹配关键词games相关,针对指定产品的进行3个不同的查询分组:/select?q=*:*&group=true&group.query=type:movies&group.query=games&group.query="The Hunger Games"
分组与排序:
solr的分组功能将全局参数rows、start以及sort也应用到分组本身。group.limit参数指定每组返回最大结果数,它执行的是rows参数在非分组搜索中的功能。grouup.offset参数允许将一个组里的结果进行分页,它执行的是start参数在非分组搜索中提供的功能。因此对分组搜索结果分页时,可以组合使用start、rows、group.limit和group.offset参数。对于排序而言,sort参数对它们进行了初始排序(决定了这些分组各自出现的顺序),还可以使用group.sort对不同分组里的文档进行重排序
分组陷阱
根据结果分组进行分面操作:默认情况下,分面数是基于原始查询的结果,而不是分组查询的结果。这意味着无论查询时是否开启分组功能,分面数都是一样的,不过可以通过设置group.facet=true来开启返回折叠结果后的分面数
分布式结果分组:结果分组功能需要重点考虑该功能如何与分布式搜索交互的问题,与标准搜索不同,结果分组功能再分布式模式下不能完全起作用。在分布式模式下,分组功能确实能返回汇总后的结果,但仅仅是在每个solr内核上本地计算出来的分组汇总结果。如果计划在分布式模式下使用solr的分组功能,并获得精确的分组数量(group.ngroups=true参数返回),就要将数据根据分组的分割到各个分片上。除了这些数据分割限制以外,分布式模式下group.truncate和group.func也不能运行
按多值和分词字段进行分组:分组功能对于多值字段完全不起作用(field设为multivalued=”true”),如果尝试这样做会抛出异常。相反,根据分词字段(将文本分割成多个标记的字段)进行分组是可以返回结果的,但是返回的结果不太可靠,很大程度上也不太确定。具体讲,如果根据分词字段对结果进行分组,groupValue只能代表每隔文档的该字段里的标记,而且用户也不能选择使用哪个标记。因此用户看不到针对每个标记的单独groupValue,只能对正在进行分组的字段里看似随机的标记进行分组。所以大多数情况下,按字段进行分组的功能只适用于单一标记、非多值的字段上
分组性能:虽然分组功能强大,但是执行速度仍然比标准solr查询慢很多。对具有不同字段值的大量文档进行分组,分组查询会花费很多时间。为了提高分组功能的速度,可以使用group.cache.percent查询参数为分组查询启用缓存功能,该参数默认为0,将其设置为1到100之间任意值都可以开启,代表了从第一个搜索开始,就能和其他得分一起被缓存的文档占索引中所有文件的百分比,因此越高速度越快,消耗的内存也就越多
折叠查找解析器:CollapsingQParserPlugin进行高效的字段折叠,该解析器不需要激活完整的结果分组堆栈,就能按照不同字段值将搜索结果折叠成单个结果。比如/select?q=...&fq={!collapse field=fieldToCollapseOn},查询fieldToCollapseOn,只会为字段里的不同值返回一个文档,且是相关度最高的,还可以通过fq={!collapse field=fieldToCollapseOn max=sum(field1, field2) nullPolicy=ignore}
扩展:
Solr系列六:solr搜索详解优化查询结果(分面搜索、搜索结果高亮、查询建议、折叠展开结果、结果分组、其他搜索特性介绍)