Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
Solr
部署
solr在编译后形成一个标准的war包,该包能被部署到任何现代的servlet容器中
solr进行分面、排序、索引文档和查询请求缓存时会消耗大量内存,因此需要确保给solr分配足够大的内存空间,以安全地存储上述数据结构。如果solr索引比服务器当前未分配给JVM的可用内存空间大,这意味着在处理搜索请求时需要进行硬盘寻道,以将索引文档加载到内存中,这会打打降低应用程序的查询速度和查询吞吐量。虽然固态硬盘能抵消硬盘寻道的时间消耗,但是最好还是保证有足够大的内存空间,让索引可以存储在内存中,不必要调用硬盘进行索引置换,就能实现solr最佳查询性能。如果需要更大的索引吞吐量,那么SSD可以提供更大好处,因为索引的性能更多是受磁盘I/O限制。在大部分现代操作系统中,当文档加载到内存,它将一直保存在内存直到系统回收这部分内存。因为solr需要反复地访问相同的大块数据(solr的索引数据),所以操作系统的文件系统缓存机制对solr服务器的总体性能就显得尤为重要。尽管许多solr索引有数千亿字节大小,超过服务器RAM大小,但是可以管理solr索引,控制它的大小总是小于RAM大小,这样solr在执行查询时就无需磁盘寻道,实现一个高效的内存搜索引擎,加速索引吞吐和查询处理
JVM设置:首先预先决定分配给solr的JVM的内存大小,而不依赖JVM在需要时再去获取内存java -Xms2g -Xmx2g -jar start.jar。不建议分配给JVM过多的内存空间,而应该只分配必要的内存空间来存储核心数据结构(缓存、solr内核和其他内存数据结构)和执行查询操作。如果分配了过多的内存,JVM垃圾回收时间会增加,因为一次回收的垃圾更多了。同时为了将solr索引文件都加载到内存而避免硬盘的寻道,通用准则就是分配给solr的内存空间比它所需要的多一点点,而将其他的内存空间都留给操作系统。solr在管理页面提供了内存统计数据,可以帮助计算solr实例消耗的内存大小
策略
增量索引:
solr在内部利用Lucene创建文档的倒排索引,这个索引过程遵循增量索引原则,即总是将修改添加到新文档中,而不添加到之前已写的文件中。这意味着索引文档一旦创建就不再改变。所以增量索引有以下优势:
1、因为之前的索引文件可以在多个新的索引版本之间共享,所以减少了存储空间的占用
2、将一个服务器的修改复制到另一个服务器只需要复制比较小的新增文档
3、无论新版本的索引何时被提交,操作系统都缓存了大部分的索引(旧索引)
但是增量索引也要付出一些代价,最主要的就是旧的索引文档不会被更新,因为任何文档更新和删除实际上都要占用额外空间,因为它们需要重新被写到新的索引文档中,索引大小将持续增长。在许多更新请求被提交后,solr中存在许多索引块,需要将它们合并成新的索引块,合并过程并不会修改旧的索引块,而是创建新的索引块,让旧的索引块失效,当旧的索引块不再被solr引用时,会删除释放空间。为了让新添加的文档能够被索引,必须要发生一次提交操作。硬提交操作启动一个新的搜索器,以取代当前正在运行的搜索器,新搜索器会创建新的索引(旧索引块加上新增索引块)
索引块合并:是否以及如何合并索引块在solrconfig.xml文件中定义了合并策略决定。合并调度器(Merge Scheduler)和合并策略(Merge policy)决定何时以及如何合并索引
索引切换和缓存预热:
当一次硬提交操作发生时,solr会创建一个新的搜索器,新的搜索器会引用索引中的旧索引块,以及所有新的索引块。因为solr可能持续接受到新的搜索请求,所以solr通过并行运行两个搜索器来实现新旧索引的无缝过渡。旧的搜索器(仅使用旧索引块)继续接受用户请求,新的搜索器(引用旧索引块和所有新增索引块)在后台被加载。因为solr利用缓存存储历史查询、过滤器、字段值及其他数据来加快搜索,所以当前新的搜索器开始处理查询请求时,需要保证这些缓存继续工作。不幸的是,缓存都绑定了特定的索引版本,因此新搜索器必须要花时间利用旧搜索器的缓存数据预热新的缓存。每当一个提交操作发生时,都会创建一个新的搜索器,并预热新的缓存。对新搜索器利用中的缓存总大小和缓存对象数目的配置都存储在solrconfig.xml文件中:
<filterCache class="solr.FastLRUCache" size="512" initialSize="512" autowarmCount="0"/>
<queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0"/>
<documentCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0"/>
<fieldValueCache class="solr.FastLRUCache" size="512" autowarmCount="128" showItems="32" />
其中合理设置缓存大小,设置合理的autowarmCount,优化新搜索器中的缓存效率和预热时间
监控
solr管理页面中,选择一个solr内核,在页面左边栏会出现插件/统计(Plugins/Stats)链接,里面可以查看有关缓存、内核、查询处理器及其他solr组件与插件情况
从请求处理器和MBeans获取统计信息:/mbeans?stats=true&wt=json便捷的获取信息
通过外部监控:启用JMX,在solrconfig中配置<JMX/>
负载测试工具:SolrMeter
SolrCloud
solr集群每个实例的索引分割称为分片,每个分片包含一部分的文档。在SolrCloud中,跨多个节点的索引分割称为集合。
可扩展性:SolrCloud倾向于使用分片和复制这样的横向扩展技术。分片能将大型索引分割成多个较小的索引。复制操作能在多态服务器上创建solr索引的其他副本,增加冗余,防止故障发生时造成的损失。尽管SolrCloud侧重于横向扩展,特别的,solr最适合于快速的、多核的CPU,容量大的内存和告诉硬盘。实际上大多数大规模的solr安装都会用到这两种方法
可用性:系统的高可用性包含两个主要特征:关键业务失效时备源到正常服务上的能力和数据冗余性。SolrCloud能够对同一个数据中心里的不同服务器进行故障转移和数据冗余
一致性:SolrCloud不允许参与查询的副本存在相同文件的版本差异。比起写操作的可用性来说,solr更强调一致性,没有一致性程度配置协调,写操作必须在分片的所有处于激活状态的副本上执行成功。但是solr确定一次写操作是否成功时,只会考虑处于激活状态和处于恢复过程中的副本,不会考虑离线副本也需要更新的问题。因为一旦使用内置的恢复过程对故障副本进行恢复,离线副本的问题就会被解决。一些系统会允许客户端应用程序容忍弱一致性,也就是最终一致性,但是SolrCloud对这种弱一致性是零容错,因为Solr为了简化一致性API,用户创建solr索引的客户端代码不需要担心部分失败,因为在分片所有副本上,更新请求要么全部成功,要么全部失败。另一方面,要查询同一个分片的内容,无论哪个副本参与其中,每次查询都能确保得到一致的搜索结果
核心
在云模式下启动solr:
java -Dcollection.confgiName=testCloud 指定zookeeper配置目录的名称
-DzkRun 运行zookeeper,与solr一样,内嵌相同的JVM,嵌入式zk的监听端口是9983
-DnumShards=2 将testCloud索引分成2个分片
-Dbootstrap_confdir=./solr/testCloud/conf 上传配置文件到zookeeper
-jar start.jar
java -DzkHost=localhost:9983
-Djetty.port=8984
-jar start.jar
如果之后在不同的端口继续启动新的实例,因为2个分片都已激活状态,因此之后的节点都会被分配作为副本
集合与内核:
solr的内核是运行在solr服务器中具有唯一命名的、可管理和可配置的索引。一台solr服务器可以托管一个或多个内核。内核的典型用途是区分不同模式的文档。SolrCloud引入了集合的概念,集合将索引扩展成不同的分片,并且分配到多台服务器上,分布式索引的每个分片都被托管在一个solr的内核中。谈及SolrCloud时,更应该从分片的角度,而不是内核的角度去思考问题。索引的分片之间是互斥关系,分片是由solr内核来支撑的。正如单台solr服务器能托管多个内核,一个SolrCloud集群也能托管多个集群。如果需要呈现不同模式的文档,可以像在单台服务器安装使用多个内核那样,在SolrCloud中使用多个集合
zookeeper:
zk是分布式系统中的一项协调服务。solr将zk用于三个关键操作:
1、集中化配置存储和分发
2、检测和提醒集群的状态改变
3、确定分片代表
SolrCloud中实例的几种可能状态:活跃、不活跃、构建中、恢复中、恢复失败、故障、消失
solr.xml中的配置:
<solr>
<solrcloud>
<str name="host">${host:}</str> 主机
<int name="hostPort">${jetty.port:8983}</int> 端口
<str name="hostContext">${hostContext:solr}</str> 主机环境
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool> 内核节点名
<int name="zkClientTimeout">${zkClientTimeout:30000}</int> zk客户端超时
<int name="distribUpdateSoTimeout">${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">${zkCredentialsProvider:org.apache.solr.common.cloud.DefaultZkCredentialsProvider}</str>
<str name="zkACLProvider">${zkACLProvider:org.apache.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:600000}</int>
<int name="connTimeout">${connTimeout:60000}</int>
</shardHandlerFactory>
</solr>
分布式索引
从客户端角度看,SolrCloud里的索引文档是相同的。实际上不需要修改代码就可以直接使用,也可以做一些优化。从Solr服务器的角度看,索引已经发生了巨大的变化。SolrCloud中分布式索引的总体目标是能够将文档发送到集群的任何节点上,并且使文档能在正确的分片中被索引,此外去除所有的单点故障
在solr索引新文档时,需要将其分配到一个分片上,且只能将一个文档分配到每个集合的一个分片上。solr使用文档路由器组件来确定该文档应该被分配到哪个分片上。支持两种基本的文档路由策略:compositeID(默认)和隐式路由(用户以在个性化定制分片的分配)。之前说过,必须设定分片的数量才能初始化一个集合,一旦solr知道分片数量,会给每个分片分配一个32位散列值,默认的compositeId路由器会计算出文档里唯一ID字段的数字散列值,并将文档分配给哈希值区间包含计算的到哈希值的分片
solr有4种类型的更新请求:添加、更新、删除和提交
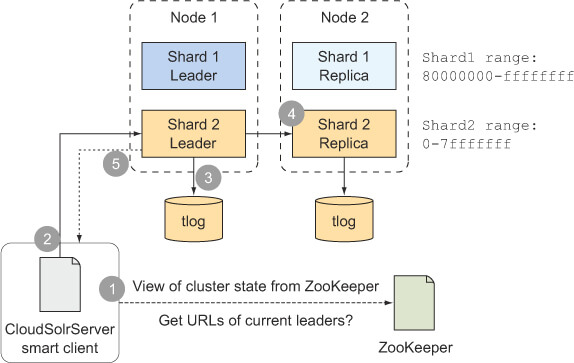 步骤1:使用CloudSolrServer发送更新请求,CloudSolrServer连接到zk上以获集群的当前状态
步骤1:使用CloudSolrServer发送更新请求,CloudSolrServer连接到zk上以获集群的当前状态
步骤2:将文档分配给正确的分片,CloudSolrServer使用文档路由进程来确定发送到哪一个分片上
步骤3:代表分配版本ID号,在将文档发送给副本前,分片代表会在本地索引文档。这是为了在将文档转送给副本前,使用更新日志验证文档并确保文档时安全持久地存储在系统里
步骤4:将请求转发给副本,一旦文档通过验证并被分配给了版本号,代表就会决定哪些副本可用,并使用多线程并行将更新请求发送给每个副本
步骤5:确认写操作成功,一旦代表受到了来自于所有活跃和恢复进程中的副本的确定,它就会将确认返回给索引客户端应用程序
提交:除非文件被提交了,否则再搜索结果里是看不到它们的。在分布式索引中,当把提交请求发送给任何节点时,系统将会提交请求转发给集群里的所有节点,以便顺利提交每个分片。简单地说,在需要打开新的搜索器时,客户端代码应该发送硬提交请求,SlorCloud会将提交请求传播给集权里的所有节点
近实时搜索(NRT):
NRT是SolrCloud设计呗合的主要驱动力之一。近实时搜索能使文件被索引之后的数秒内就出线在搜索结果中,因此会使用到近似合格(near qualifier)。为了实现近实时搜索,solr提供了软提交机制,它能避免硬提交中成本高昂的操作,例如将存储在内存中的文件洗入到磁盘中。之前说过,分片代表在对索引客户端程序作出响应之前,会将更新请求转发给所有副本,这能确保所有分片产生一致的搜索结果。这也说明,此设计决定将更新发送给所有副本在很大程度上依赖于近实时搜索的支持。与此相反,主从系统不能支持近实时搜索,因为近实时搜索的目的是使文档在被添加到索引之后的大约一秒钟内就能出现在搜索结果中。基于主从系统的复制依赖于整个片段从主节点复制到从节点。我们可以使用任意现有客户端程序在近实时搜索中构建索引:
<autoSoftCommit>
<maxTime>1000</maxTime> 每1000毫秒发出一个软提交
</autoSoftCommit>
由于软提交成本低,所以每隔几秒就能发起一个软提交,这样就能在近实时搜索中看到新进被索引的文件。然而某个时间点仍然需要执行硬提交,以确保文件最终被写入到永久存储里。当执行软提交时,solr必须打开新的搜索器,让软提交的文档在搜索结果中可见。这意味着,solr还必须让所有缓存与软提交带来的改变保持一致。在软提交之后打开新的搜索器,solr会对缓存进行预热,执行在solrconfig中配置好的预热查询,因此缓存自动预热设置和预热查询的执行速度必须比执行软提交的速度更快。尽管近实时搜索是很强大的功能,但并不是一定要与SolrCloud一起使用。不适用软提交,近实时搜索也是可以完全接受的,除非真的要让搜索文档近实时出现在搜索结果中,否则不要使用它,因为软提交的缺点之一就是,缓存经常会无效
节点恢复:SolrCloud提供两种基本的恢复方案:对等同步(peer sync)和快照复制(snapshot replication)
分布式搜索
索引分片后,必须查询所有的分片才能得到完整的结果。查询集合中所有分片并创建统一结果集的过程称为分布式查询。distrib参数确定查询是分布式还是本地的,启用了SlorCloud后,该参数默认值为true
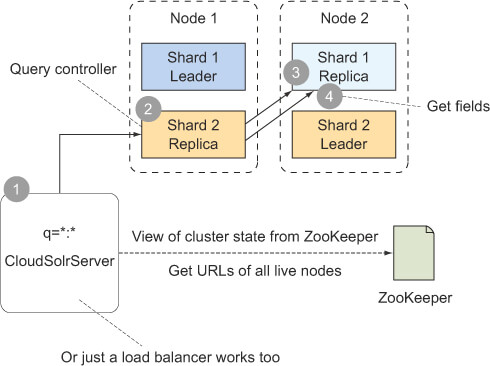 步骤1:客户端发送查询请求至任何节点,常见情况是使用负载均衡将查询请求分配到集群中各个不同的节点上
步骤1:客户端发送查询请求至任何节点,常见情况是使用负载均衡将查询请求分配到集群中各个不同的节点上
步骤2:查询控制器接受请求,接受初始请求的节点是查询控制器(或聚合器),它要负责创建统一的结果集并返回给客户端。集群里的任何节点都能充当任何查询的控制器
步骤3:查询阶段,查询控制器会给每个分片发送一个非分布式查询,以确定匹配分片里的文档
步骤4:获取字段阶段
分布式搜索的局限性:不是所有的solr查询功能都能使用分布式模式
扩展:
Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)