Solr学习01 - 入门
Solr学习02 - 基本配置
Solr学习03 - 创建索引与文本分析
Solr学习04 - 查询与处理结果
Solr学习05 - solr分面、高亮、查询建议和分组
Solr学习06 - solr与solrCloud
Solr学习07 - 多语种等复杂查询和相关度提升
多语种搜索
词干提取:程序化地确定单词词干的过程。比如一个英语词干提取器可能会将单词后面类似s、es、ed和ing等词尾去掉。因为solr在索引和查询时都会进行词干提取,这意味着用户搜索某个单词的任意变化形式都将与它所有的变化形式匹配
缺点:
1、如果一个单词的所有变化形式没有映射到相同的词干,搜索会出现失误匹配。比如单词dry被词干化为dry,而单词dries被词干化为dri,这种情况下就不能匹配,因为它们映射到了不同的词干
2、可能会导致过渡匹配。比如animal和animated都词干化为anim,或者iron和ironic都词干化为iron。过度词干化产生的结果很多单词会被错误地匹配其他不相关的单词,从而降低搜索的查准率
没有哪个词干提取算法是完美的,所以需要选择一个能够满足绝大多数实例需求的词干提取算法。一般来说,如果更在意查全率,应该选择贪婪性强的词干提取器,相反更在意查准率,则应该选择一个贪婪性较弱的词干提取器
词形还原:是确定一个单词的词根形式的过程。词干提取通过算法发现一个单词的词根形式,词形还原主要利用字典查找一个单词的词根。词项还原会将单词went还原为go,将单词am、is、are、was、being、been都还原为be。显然,词形还原比词干提取更准确,但找到好的词典要比使用它本身更难
形态分析:形态分析工具使用统计自然语言处理(NLP)技术,从大型文本库中分析得出一种语言的语种结构,也能达到很好的效果。但是目前只能通过商业供应商来获取词形还原和形态学中经过加工后有序的语种模型库
处理边界情况:没有哪个词干提取算法能完美应对搜索应用可能遇到的所有情况。有时候会产生错误词干,有时候不想改变某些特定的词。solr提供了一些功能来克服词干提取器实现的自身局限性:
1、KeywordMarkerFilterFactory:不希望对某些特定的词进行词干提取,这些词属于专用名词。KeywordMarkerFilterFactory可以指定一个受保护词表,其中单词会被solr中所有词干提取器忽略
2、StemmerOverrideFilterFactory:使用一个自定义的词干提取字典,且先于后续词干提取器运行
语种库
由于不同语种之间的巨大差异,在定义solr中的字段以正确处理某一语种时,并没有一个统一的模型可供遵循。一些语种需要用它们自己的词干过滤器,其他语种则可能需要多种过滤器来处理不同语言特征(如字符归一化、重音消除、甚至自定义小写转换),一些语种由于语言分析的复杂性需要使用它们特有的分词器
大多数分析器链的最后一个特征是词干提取器的使用。绝大多数语种都有一个或更多可使用的特定语种词干提取器,可以根据贪婪性的高低选择合适的词干提取器
基于词典的词干提取:Hunspell支持许多词干提取算法,它是一个基于词典的词干提取器,这意味着它只对包含在词典中的词有作用
多语种搜索
一个文档集可能有不同的语种,甚至在一个文档或字段中就有多种语种,有三种主要方法来实现这些类型的多语种搜索功能:
1、为每种语言创建一个独立字段,跨每个字段查询
2、在相同字段名上建立并配置多个索引,为每个索引配置字段来处理不同的语种
3、设置一种能够同时支持跨语种索引和搜索的字段类型
field-per-language模型配置多语种搜索的索引和查询:
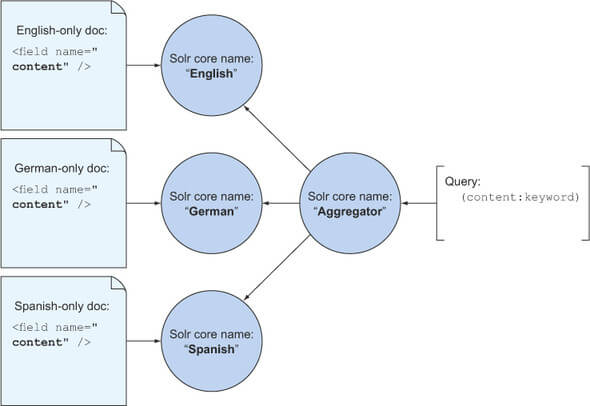
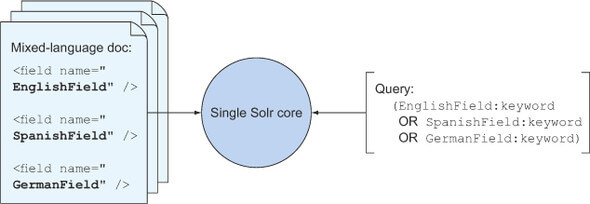 core-per-language模型实现多语种搜索的索引和查询:
core-per-language模型实现多语种搜索的索引和查询:
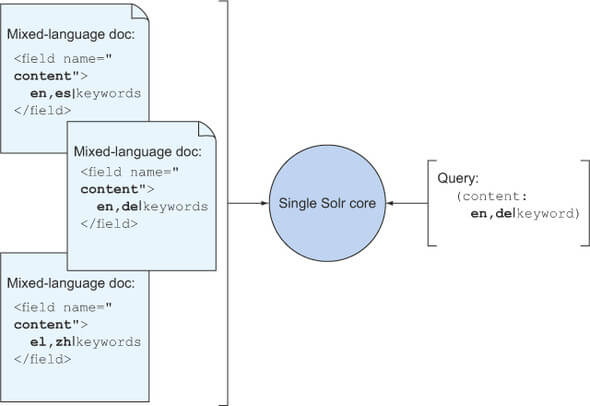
 支持多语种的单个字段,指定多个分析器(每个语种一个),每个语种都有一个完全独立的分析器链,自定义TextField与Analyzer、Tokenizer:
支持多语种的单个字段,指定多个分析器(每个语种一个),每个语种都有一个完全独立的分析器链,自定义TextField与Analyzer、Tokenizer:
语种识别
支持多语种内容的一个内在挑战是确定出现在每个文档中的语种。因为识别一种语言需要文本块,因此当全部的文档都呈现出来的时候,通常在索引时比在查询时更容易识别语种。不推荐用语种识别算法来确定用户查询语句中的语种类型,因为大多数搜索语句都很短,不能提供足够有意义的内容。基于web的项目可以通过其他方式,比如通过用户属性或IP地址来确定用户位置,来确定用户的语种类型,所以通常不用担心在查询时基于用户的查询语句来进行语种识别的不可靠性问题
语种识别更新处理器:
为了支持文档中的语种识别,solr提供了2个特有的更新处理器:TikaLanguageIdentifierUpdateProcessor和LangDetectLanguageIdentifierUpdateProcessor。第一个利用Apache Tika中的语种识别库,第二种使用Java的开源语种识别库,它的精确率很高。语种识别更新处理器中一些额外的可用语种识别选项,可以支持基于语种识别将内容映射到不同的字段中,以langid.开头。这样内容将会被转移到对应的语种字段,通过使用eDisMax查询解析器进行跨字段搜索
复杂查询
函数查询
solr的函数可以动态计算每个文档的值,而不是返回在索引阶段对应字段的静态数值集。函数查询是一类特殊的查询,它可以像关键词一样添加到查询中,对所有文档进行匹配并返回它们的函数计算值最为文档得分。使用函数查询,函数计算结果将用于修改相关度得分或用于搜索结果排序。函数允许嵌套任意多层
语法:functionName(inuput1, input2, …)
例如,以下3种语句都是等效的:
1、值挂接:q=Solr AND _val_:add(1, boostField)
2、查询解析器挂接(显式嵌套查询):q=Solr AND _query_:"{!func}add(1, boostField)"
3、查询解析器挂接(隐式嵌套查询):q=Solr AND {!func v="add(1, boostField)"}
frange查询解析器:对搜索结果进行过滤,只留下函数计算产生特定值的文档,可以选择函数区间解析器。frange过滤器执行一个特定的函数查询,然后过滤掉函数值落在最低值和最高值范围之外的文档。例如/select?q=*:*&fq={!frange l=10 u=15}product(basePrice, sum(1, $userSalesTax))&userSalesTax=0.07,此查询通过userSalesTax参数来计算每件产品的总价格,同时将营业税添加到每件产品基础价格定义的basePrice字段。frang查询解析器过滤了总价格在10~15区间以外的那些文档
以字段形式返回函数:在solr中其他一些地方用函数代替字段也是可行的。例如上面的例子,计算每篇文档中产品的总价格然后返回:/select?q=*:*&userSalesTax=0.07&fl=id,basePrice,totalPrice:product(basePrice, sum(1, $userSalesTax))
函数排序:函数的计算结果可以作为一个字段添加到文档并返回到搜索结果。这是因为ValueSource(查询函数)产生了DocValues(每个文档与它们取值的映射),包含了每个文档的计算值。所以就可以根据每个文档计算出的函数值来过滤搜索结果集、修改文档的相关度,以及添加或修改搜索请求的返回字段和取值。那么就还可以进行排序,例如:/select?q=*:*&userSalesTax=0.07&sort=product(basePrice, sum(1, $userSalesTax)) asc, score desc
如果将之前的所有方法组合起来,就能构造更加复杂的查询:
/select?q=_query_:"{!func}recip(ord(date),1,100,100)"&
userSalesTax=0.07&
totalPriceFunc=product(basePrice, sum(1, $userSalesTax))&
fq={!frange l=10 u=15 v=$totalPriceFunc}&
fl=*,totalPrice:$totalPriceFunc&
sort=$totalPriceFunc asc, score desc
solr可用函数集:数据转换函数(map…)、数学函数(sum…)、相关度函数(idf…)、距离函数(dist…)、布尔函数(if…)
自定义函数:创建solr的自定义插件需要三个步骤:
1、编写函数类,继承ValueSource类,保证在搜索索引中的每个文档都返回一个计算值
2、编写ValueSourceParser类,它可以理解自定义函数语法,将它解析成第1步自定义的ValueSource函数需要的变量
3、向solrconfig.xml中添加一个XML元素,定义自定义函数的名称以及ValueSourceParser的位置
地理空间搜索
根据单个点搜索
支持基于圆的半径或者正方形的过滤
1、定义位置字段
2、地理位置和边界框过滤器
3、在搜索结果中返回已计算好的距离值
4、距离排序
高级地理空间搜索
基于网格的位置搜索
分面透视
提供基于多个字段值的条件分面计数
跨文档和跨内核的连接
做大数据分析
相关度
由于用户考虑很多因素,在用户判断是否相关的认知中,关键词的相关度显然只是影响因素之一。精确地把握搜索应用的所属领域,这一点很重要,这样才能更好地改进搜索的相关度
相关度计算调试:之前说过,通过debug=results或debug=true来启用查询调试。debug参数出现在solr响应的末尾部分,以单独一节返回调试信息
提升相关度
字段提升:
1、索引阶段的字段提升:在提交文档给solr时,添加boost字段设置权重,并且在fieldType中设置omitNorms=”false”
2、查询阶段的字段提升:人工查询/select?q=restaurant_name:(red lobster)^10 OR description:(red lobster)或者eDisMax查询/select?defType=edismax&q=red lobster&qf=restaurant_name^10 description
词项提升:人工查询/select?q=restaurant_name:(red^2 lobster^8)^10 OR description:(red^2 lobster^8)或者eDisMax查询/select?defType=edismax&q=red^2 lobster^8&qf=restaurant_name^10 description
负载提升:payload
函数提升:向查询添加函数,可以操作或替换solr的相关度算法,修改相关度评分方法,以满足搜索应用需求。例如/select?q=restaurant_name:(Burger king) AND _query_:"{!func}recip(geodist(location, 37.765, -122.43),1,10,1)"。查询中指定的地理位置靠近的文档会得到额外的相关度提升,boost值最高为10。另外比如对新闻查询,除了地理空间,还有流行度和新鲜度可以进行调整,例如过滤器(fq)限制关键词匹配结果,查询(q)依次计算各个值(关键词相关度、地理位置远近、文档时效性、文档流行度),取值1~100:
/select?fq={!cache=false v=$keywords}&
q=_query_:"{!func}scale(query($keywords),0,100)"
AND _query_:"{!func}div(100,map(geodist(location,$pt),0,1,1))"
AND _query_:"{!func}recip(rord(publicationDate),1,100,1)"
AND _query_:"{!func}scale(popularity,0,100)"&
keywords="street festival"&
pt=33.748,-84.391
词项邻近度提升:solr搜索时两种信息检索模型,词项的布尔匹配与向量空间相关度计算,结合使用。使用field~slop^boost
提升重要文档的相关度:与索引阶段的字段提升类似,只是将boost设置到了doc的维度。此外还可以使用查询提升组件修正个别相关度
个性化搜索与推荐
事实上,搜索与推荐都是匹配的表现而已。搜索引擎通常对查询与文档中的关键词与位置进行匹配,推荐引擎则是根据用户之间表现出来的类似行为来推荐文档,或者对两个文档的内容进行匹配。从基本层面上看,搜索引擎与推荐引擎的工作原理相同:通过建立文档之间链接的稀疏矩阵,使用某种相似性度量来寻找最佳匹配。这些矩阵包括”词项——文档”矩阵(关键词搜索中典型的倒排索引)和”偏好——文档”(用于推荐行为的倒排索引,称为协同过滤)。那么,搜索与推荐的真正区别在于:搜索一般是需要用户输入的手工任务,而推荐通常是了解用户有关行为,自动地提供建议信息
solr可以视为一个匹配引擎,它能对已解析的文档进行匹配。而搜索是人工还是自动化的,这与solr没有关系
基于属性匹配:solr能够索引用户感兴趣的文档信息,比如类目、位置以及其他属性。为构建基于属性的推荐引擎,需要确保用户与文档具备相同类型的描述属性。用户个人信息的许多属性与被搜索的内容可以很好地进行匹配,则适用于大多数搜索应用
分层匹配:由于并不是所有属性都是以相同方式创建的,有时需要对具体属性做出选择。如果属性匹配,就要为它们赋予更高权重。这就是分层匹配背后的思想。假设对用户和内容进行分类,将其归入某种层级中(从一般类目到特殊类目),这样就可以对这个层级进行查询,对更加专指的匹配赋予更高的相关度权重:
/select?df=classification&
q=(
( 最为接近的第一级目录层级
"healthcare.nursing.oncology"^40
OR
"healthcare.nursing"^20
OR
"healthcare"^10
)
OR
( 其次接近的第二级目录层级
"healthcare.nursing.transplant"^20
OR
"healthcare.nursing"^10
OR
"healthcare"^5
)
OR
(
"education.postsecondary.nursing"^10
OR
"education.postsecondary"^5
OR
"education"
)
)
更多类似结果:在solrconfig中启用MoreLikeThisHandler,并且在查询中添加mlt.fl等相关参数,例如/mlt?df=jobname&q=java&mlt.fl=jobtitle,jobname&mlt.interestingTerms=details&mlt.boost=true
基于概念的匹配:使用solr聚类组件,用于发现文档之间的相似度,找出初始查询或文档没有通过字面表达出来的相关概念
地理位置的匹配
协同过滤:机器学习领域中最常用的,也是性能最佳的推荐算法之一