zookeeper(一) 基础
zookeeper(二) Java API
zookeeper(三) 管理
简单Demo
导入依赖Maven:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
加入log4j.properties:
log4j.rootLogger = info,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [%c]-[%p] %m%n
查看ZooKeeper的构造函数,可以发现需要的基本元素:服务器串、会话超时时间、监视器
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
throws IOException {
this(connectString, sessionTimeout, watcher, false); // boolean canBeReadOnly
}
由于Watcher是一个接口,里面定义了内部类Event。因此先自定义一个简单的Watcher,实现其process抽象方法:
public class FirstWatcher implements Watcher {
public void process(WatchedEvent event) {
System.out.println("Watcher: " + event);
}
}
然后写一个启动类,连接ZK
public static void main(String[] args) throws Exception {
String hostPort = "127.0.0.1:2181";
int timeout = 15000;
FirstWatcher watcher = new FirstWatcher();
ZooKeeper zk = new ZooKeeper(hostPort, timeout, watcher);
// 等待接受Event后再关闭
Thread.sleep(5 * 1000);
// zk.close();
}
查看连接打印结果,收到SyncConnected事件:
// 代码客户端输出:
2019-02-02 16:58:37 [org.apache.zookeeper.ZooKeeper]-[INFO] Client environment:...
... environment信息 ...
2019-02-02 16:58:37 [org.apache.zookeeper.ZooKeeper]-[INFO] Initiating client connection, connectString=127.0.0.1:2181 sessionTimeout=15000 watcher=com.zk.demo.FirstWatcher@306a30c7
2019-02-02 16:58:37 [org.apache.zookeeper.ClientCnxn]-[INFO] Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2019-02-02 16:58:37 [org.apache.zookeeper.ClientCnxn]-[INFO] Socket connection established to 127.0.0.1/127.0.0.1:2181, initiating session
2019-02-02 16:58:37 [org.apache.zookeeper.ClientCnxn]-[INFO] Session establishment complete on server 127.0.0.1/127.0.0.1:2181, sessionid = 0x168ad6de1590000, negotiated timeout = 15000
Watcher: WatchedEvent state:SyncConnected type:None path:null
// ZK服务端输出:
2019-02-02 16:58:37,677 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:11914
2019-02-02 16:58:37,677 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@900] - Client attempting to establish new session at /127.0.0.1:11914
2019-02-02 16:58:37,677 [myid:] - INFO [SyncThread:0:FileTxnLog@199] - Creating new log file: log.1d8
2019-02-02 16:58:37,724 [myid:] - INFO [SyncThread:0:ZooKeeperServer@645] - Established session 0x168ad6de1590000 with negotiated timeout 15000 for client /127.0.0.1:11914
2019-02-02 16:58:43,048 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@362] - Exception causing close of session 0x168ad6de1590000 due to java.io.IOException: 远程主机强迫关闭了一个现有的连接。
2019-02-02 16:58:43,054 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:11914 which had sessionid 0x168ad6de1590000
2019-02-02 16:58:54,005 [myid:] - INFO [SessionTracker:ZooKeeperServer@355] - Expiring session 0x168ad6de1590000, timeout of 15000ms exceeded
2019-02-02 16:58:54,005 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@489] - Processed sessiontermination for sessionid: 0x168ad6de1590000
如果这时候关闭了ZooKeeper服务端,则会抛出异常,并获取到Disconnected事件
2019-02-02 17:09:12 [org.apache.zookeeper.ClientCnxn]-[WARN] Session 0x168ad6de1590001 for server 127.0.0.1/127.0.0.1:2181, unexpected error, closing socket connection and attempting reconnect
java.io.IOException: 远程主机强迫关闭了一个现有的连接。
...
Watcher: WatchedEvent state:Disconnected type:None path:null
2019-02-02 17:09:14 [org.apache.zookeeper.ClientCnxn]-[INFO] Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2019-02-02 17:09:15 [org.apache.zookeeper.ClientCnxn]-[WARN] Session 0x168ad6de1590001 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused: no further information
...
可以看到ZooKeeper库会负责重新连接服务,当不幸遇到网络中断或服务器故障时,ZooKeeper可以处理这些故障问题。如果ZooKeeper服务至少由三台服务器组成,那么一个服务器的故障并不会导致服务中断。而客户端也会很快收到Disconnected事件,之后便为SyncConnected事件。因此并不需要开发者自己去管理ZooKeeper客户端的连接
znode操作
获取管理权
为了确保同一时间只有一个主节点进程处于活动状态,使用ZooKeeper来实现简单的群首选举法。所有潜在的主节点进程尝试创建/master节点,但只有一个成功,成为主节点。ZooKeeper通过插件式的认证方法提供了每个节点的ACL策略功能,因此可以限制某个用户对某个节点的哪些权限,对于这个简单的例子,采用OPEN_ACL_UNSAFE策略。因此会用到临时znode来打到目的,在主节点挂了后/master节点会消失
首先创建临时节点/master,并且在这个节点上保存对应这个服务器的唯一ID。如果/master存在,那么可以使用/master中的数据来确定哪台服务器是群首。在操作中会抛出两种异常:KeeperException和InterruptedException。特别的ConnectionLossException(KeeperException子类)异常发生于客户端与ZK服务端失去连接时,一般是网络原因导致,如网络分区或ZK服务器故障,当这个异常发生时,不知道是在ZK服务器处理前丢失请求,还是处理后客户端未收到通知,虽然ZooKeeper的客户端库会请求重新建立连接,但进程仍然必须知道一个未决请求是否已经处理了还是需要再次发送请求。对于InterruptedException异常源于客户端线程调用了Thread.interrupt,进程中断本地客户端的请求过程,并使该请求处于未知状态
private String serverId = "abc";
private boolean isLeader = false;
public void runForMaster(ZooKeeper zk) throws InterruptedException{
while(true) {
try {
// 尝试创建/master临时znode,成功则自己为主节点
zk.create("/master", serverId.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
isLeader = true;
break;
// 如果节点已经存在,那么自己就是从节点
} catch (KeeperException.NodeExistsException e) {
isLeader = false;
break;
// 多种可能,在不确认前不希望确定主节点
} catch (KeeperException.ConnectionLossException e) {
// ----> 去尝试判断自己是否是主节点
if (checkMaster(zk)) {
break;
}
} catch (KeeperException e) {
// LOGGER错误日志,中止
break;
}
}
}
private boolean checkMaster(ZooKeeper zk) throws InterruptedException{
while(true) {
try {
// 获取/master节点的数据,来判断自己是否是群首
byte data[] = zk.getData("/master", false, new Stat());
isLeader = new String(data).equals(serverId);
return true;
} catch (KeeperException.NodeExistsException e) {
// 没有节点,继续尝试创建
return false;
} catch (KeeperException.ConnectionLossException e) {
// 不处理,可能响应信息丢失
} catch (KeeperException e) {
// LOGGER错误日志,中止
return true;
}
}
}
在ZooKeeper中,所有同步调用都有对应的异步调用方法。通过异步调用,可以在单线程中同时进行多个调用,也可以简化实现方式:
private AsyncCallback.StringCallback masterCreateCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
checkMaster();
return;
case OK:
isLeader = true;
break;
default:
isLeader = false;
}
}
};
public void runForMaster() {
zk.create("/master", serverId.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL,
masterCreateCallback, null);
}
对于checkMaster方法,同样采用异步:
private AsyncCallback.DataCallback masterCheckCallback = new AsyncCallback.DataCallback() {
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 继续尝试确认
checkMaster();
case NONODE:
// 通过创建来判断
runForMaster();
return;
}
}
};
private void checkMaster() {
zk.getData("/master", false, masterCheckCallback, null);
}
这里通过对回调的错误处理来完成while循环和主节点判断。应用程序常常由异步变化通知所驱动,因此最终以异步方式构建系统,简单有效而且不会阻塞应用程序,其他事务可以继续进行
设置数据
在创建节点的时候,就可以设置数据,使用异步方式与上面的类似:
private AsyncCallback.StringCallback createNodeCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 尝试再创建
createNode(path, (byte[])ctx);
return;
case OK:
// 成功,doSomething...
break;
case NODEEXISTS:
// 已经存在
break;
default:
// LOGGER日志
}
}
};
// 传入data,第二个参数表示要保存到znode的数据,第四个参数可以在回调函数中继续使用
zk.create("/master", data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL,
createNodeCallback, data);
使用setData可以设置内容,比如更新状态数据,由于ZK严格维护执行顺序,并提供有序保障,因此多线程下要小心面对顺序问题:
public void setStatus(String status) {
this.status = status;
updateStatus(status);
}
synchronized private void updateStatus(String status) {
// 重新处理异步请求连接丢失时有个小问题:
// 处理流程可能变得无序,因为ZK对请求和响应都会很好保持顺序,但如果连接丢失,再发起一个新的请求,会导致整个时序出现空隙
// 因此进行一个状态更新请求前,先获得当前状态,否则就要放弃更新
if (status == this.status) {
// 执行无条件更新,-1代表禁止版本号检查
zk.setData("/workers/work1", status.getBytes(), -1, statusUpdateCallback, status);
}
}
private AsyncCallback.StatCallback statusUpdateCallback = new AsyncCallback.StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (KeeperException.Code.get(rc)) {
// 丢失事件时,重新更新,由于在updateStatus方法中做了竞态条件的检查,这里就不需要再次检查
case CONNECTIONLOSS:
updateStatus((String) ctx);
return;
}
}
};
任务队列化
使用有序节点很容易实现:
String name = zk.create("/tasks/task-", task.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL)
获取znode内容在”获取管理权”代码里有写到,类似使用同步方法(忽略异常处理):
Stat stat = new Stat();
// 由于不关心节点变化,第二个参数使用false
byte[] taskData = zk.getData("/tasks", false, stat);
// 通过Stat结构,可以获得当前节点的信息,这里获取了当前节点创建时间
Date startDate = new Date(stat.getCtime());
System.out.println("task: " + new String(taskData) + " ,since:" + startDate);
System.out.println("tasks:");
for (String name : zk.getChildren("/tasks", false)) {
byte[] task = zk.getData("/tasks/" + name, false, null);
System.out.println(name + ": " + new String(task));
}
watch操作
当程序注册了一个监视点来接收通知,匹配该监视点条件的第一个事件会触发监视点的通知,并且最多只触发一次。客户端设置的每个监视点与会话关联,如果会话过期,等待中的监视点将会被删除。不过监视点可以跨越不同服务端的连接而保持。例如一个ZK客户端与一个ZK服务端的连接断开后连接到集合中的另一个服务端,客户端会发送未触发的监视点列表,在注册监视点时,服务端将要检查已监视的znode节点在之前注册监视点之后是否已经有变化,如果znode节点已经发生变化了,一个监视点事件就会被发送给客户端,否则再新的服务端上注册监视点
ZooKeeper的API中的所有读操作:getData、getChildren和exists,都可以选择在读取的node节点上设置监视点。使用监视点机制,需要实现Watcher接口类的process方法:
abstract public void process(WatchedEvent event)
public class WatchedEvent {
// ZK会话状态:Unknown、Disconnected、SyncConnected、AuthFailed、ConnectedReadOnly、SaslAuthenticated和Expired
final private KeeperState keeperState;
// 事件类型:NodeCreated、NodeDeleted、NodeDataChanged、NodeChildrenChanged和None
// 前面三种事件类型只涉及单个znode节点,第四种涉及监视点的znode节点的子节点。None表示无事件发生,而是ZK的会话状态发生了改变
final private EventType eventType;
// 如果事件类型不是None时,返回znode路径
private String path;
}
监视点有两种类型:数据监视点和子节点监视点。创建、删除或设置一个znode节点的数据都会触发数据监视点,exists和getData这两个操作都可以设置数据监视点。只有getChildren操作可以设置子节点监视点,这种监视点只有在znode子节点创建或删除时才触发,在zookeeper(一) 基础中的Watcher中有事件类型与操作的表,可以看出相应的操作
对于ZooKeeper节点的事件通知,可以使用默认的监视点,也可以单独实现一个,比如getData调用就有两种方式的实现:
// 同步
public byte[] getData(String path, boolean watch, Stat stat)
public byte[] getData(final String path, Watcher watcher, Stat stat);
// 异步
public void getData(String path, boolean watch, DataCallback cb, Object ctx)
public void getData(final String path, Watcher watcher, DataCallback cb, Object ctx)
注意:在当前使用的zk3.4.8及之前的版本,监视点一旦设置后就无法移除。如果要移除,只有两个办法,一是触发这个监视点,二是使其会话被关闭或过期
主-从模式监视
上一篇和之前都说到的“主-从”模式,在通过创建/master得知主节点后,还需要处理一些变化:
1、管理权变化:主节点崩溃后从节点的接管
2、主节点等待从节点列表的变化(加入、退出,与本地缓存列表比较)
3、主节点等待新任务进行分配(加入新任务,读取新任务)
4、从节点等待分配任务(加入从节点列表,监视自己的任务)
5、客户端等待任务的执行结果(创建任务,监视任务状态)
管理权变化
其实在临时节点/master上设置监视点,在节点删除时(无论显式关闭还是会话过期等),ZK就会通知客户端,对上面的稍作修改:
private AsyncCallback.StringCallback masterCreateCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接丢失时,检查/master节点是否存在
checkMaster();
return;
case OK:
state = States.ELECTED;
// do Leader something 行使领导权
break;
case NODEEXISTS:
state = States.NOT_ELECTED;
// 其他进程已经创建了节点,----> 监视该节点
masterExists();
break;
default:
state = States.NOT_ELECTED;
// LOGGGER.error
}
}
};
private void masterExists() {
// 调用exists设置监视点
zk.exists("/master", masterExistsWatcher, masterExistsCallback, null);
}
private Watcher masterExistsWatcher = new Watcher() {
public void process(WatchedEvent event) {
// 如果/master被删除了,那就重新创建,竞争主节点
if (event.getType() == Event.EventType.NodeDeleted) {
assert "/master".equals(event.getPath());
runForMaster();
}
}
};
private AsyncCallback.StatCallback masterExistsCallback = new AsyncCallback.StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接丢失时,重新设置监视点
masterExists();
break;
case OK:
// 在create的回调方法执行和exists操作执行之间发生了/master节点被删除的情况
// 因此在exists返回操作成功后,需要检查返回的stat对象是否为空,因为当节点不存在时stat为null
if (stat == null) {
state = States.RUNNING;
// 就要重新去创建,竞争主节点
runForMaster();
}
break;
default:
// 通过获取节点来检查/master节点是否存在
checkMaster();
}
}
};
主节点等待从节点列表的变化
和之前说的一样,通过/workers下添加临时子节点来加入,当从节点崩溃或被系统移除(会话过期等),对应znode节点删除。通过getChildren来获取有效的从节点里列表,同时监控这个列表的变化:
public void getWorkers() {
zk.getChildren("/workers", workersChangeWatcher, workersGetChildrenCallback, null);
}
// 节点列表监视点对象
private Watcher workersChangeWatcher = new Watcher() {
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeChildrenChanged) {
assert "/workers".equals(event.getPath());
getWorkers();
}
}
};
private AsyncCallback.ChildrenCallback workersGetChildrenCallback = new AsyncCallback.ChildrenCallback() {
public void processResult(int rc, String path, Object ctx, List<String> children) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接丢失时,重新获取子节点并设置监视点的操作
getWorkers();
break;
case OK:
// 更新本地从节点列表缓存,如果有节点被移除,需要重新分配任务
reassignAndSet(children);
break;
default:
// LOGGER.error
}
}
};
主节点等待新任务进行分配
监视/tasks任务节点与上面的”主节点等待从节点列表的变化”一样,关键是在OK的情况下,如果children != null,那么就去获取任务子节点
private void assignTasks(List<String> tasks) {
for (String task : tasks) {
getTaskData(task);
}
}
private void getTaskData(String task) {
zk.getData("/tasks/" + task, false, taskDataCallback, task);
}
private AsyncCallback.DataCallback taskDataCallback = new AsyncCallback.DataCallback() {
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 丢失连接时,重新获取数据
getTaskData((String) ctx);
break;
case OK:
// 随机选择一个工作从节点
int worker = new Random().nextInt(workerList.size());
String designatedWorker = workerList.get(worker);
// 分配任务
String assignmentPath = "/assign/" + designatedWorker + "/" + (String) ctx;
createAssignment(assignmentPath, data);
break;
default:
// LOGGER.error
}
}
};
分配任务,删除tasks下对应节点:
// 创建分配任务节点/assign/worker-id/task-num
private void createAssignment(String path, byte[] data) {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT, assignTaskCallback, data);
}
private AsyncCallback.StringCallback assignTaskCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
createAssignment(path, (byte[]) ctx);
break;
case OK:
// 删除/tasks下对应的任务节点
deleteTask(name.substring(name.lastIndexOf("/") + 1));
break;
default:
// LOGGER.error
}
}
};
从节点等待分配任务
首先需要在/workers节点下创建代表自己的临时子节点,而且重复注册不会有问题,可以在NODEEXISTS中处理日志之类的事情
除此之外,还需要创建/assign/work-id节点,这样主节点可以为这个从节点分配任务,为了避免主节点分配失败,需要在创建/workers/work-id后在创建/assign/work-id
然后使用getChildren监视/assign/work-id下的NodeChildrenChanged事件,获取任务,具体代码与上面的类似
客户端等待任务的执行结果
客户端将在/tasks下创建任务节点,使用CreateMode.PERSISTENT_SEQUENTIAL持久有序节点。特别要注意的是,在创建有序节点时发生CONNECTIONLOSS事件,处理这种情况比较棘手,因为ZK每次分配一个序列号,对于连接断开的客户端,无法确定这个节点是否创建成功。为了解决这个问题,需要添加一些提示信息来标记这个znode的创建者,比如加入服务器ID等信息,通过这个方法,通过获取所有任务列表来确定任务是否添加成功
然后对/status/task-id进行exists监视,如果发生NodeCreated事件,获取状态节点内容
multiop/事务
multiop可以原子性地执行多个ZooKeeper的操作,执行过程为原子性:
// 同步
public List<OpResult> multi(Iterable<Op> ops) throws InterruptedException, KeeperException;
// 异步
public void multi(Iterable<Op> ops, MultiCallback cb, Object ctx);
比如删除/a节点以及其下的/a/b节点:
List<OpResult> results = zk.multi(Arrays.asList(Op.delete("/a/b", -1), Op.delete("/a", -1)));
Transaction封装了multi方法,提供了简单的接口。可以通过创建Transaction实例添加操作,提交事务:
Transaction t = zk.transaction();
t.delete("/a/b", -1);
t.delete("/a", -1);
// 同步
List<OpResult> results = t.commit();
commit方法同样也有异步版本,传入MultiCallback和Object
使用multiop可以简化上面的主从例子,并且提供原子性操作,保证节点崩溃后的操作正确。同时multiop提供了另外一个功能,就是检查一个znode节点的版本,在输入的znode节点与版本号不匹配时,multiop调用失败:public static Op check(String path, int version)
顺序的保障
在通过ZK实现应用时,需要牢记一些涉及顺序性的事项
写操作的顺序:ZooKeeper状态会在所有服务端组成的集合中进行复制(多数原则)。服务端对状态变化的顺序达成一致,并使用相同的顺序执行状态的更新。所有服务端并不需要同时执行这些更新,因为它们以不同的速度运行,即使它们运行在同种硬件下,很多原因会导致这种时滞发生,如操作系统的调度、后台任务等。对于应用程序来说,在不同时间点执行状态更新并不是问题,因为它们会感知到相同的更新顺序
读操作的顺序:ZooKeeper客户端总是会观察到相同的更新顺序,即使它们连接到不同的服务端上。但是客户端可能是在不同的时间观察到了更新,如果它们还在ZooKeeper以外通信,这种差异就会更就明显,称之为隐藏通道,因为ZooKeeper并不知道客户端之间额外的通信。为了避免读到过去的数据,客户端应该使用ZooKeeper进行所有涉及状态的通信,消除隐藏通道
通知的顺序:ZooKeeper对通知的排序涉及其他通知和异步响应,以及对系统状态更新的顺序。比如为了保障客户端不会读到任何无效配置,有一个/config节点,子节点存储了配置元数据/config/m1、/config/m2…,主节点通过setData更新每个znode节点且不能让客户端只读到部分更新,因此可以在开始更新这些配置前先创建/config/invalid节点,其他需要读取状态的客户端监视/config/invalid节点,如果该节点存在就不会读取配置状态,当该节点删除后,就意为着有一个新的有效的配置节点集合可用,客户端可以进行读取该集合的操作。对于这个原子性问题,也可以使用multiop代替对额外znode节点或通知的依赖,不过通知机制非常通用,而且并未约束为原子性的
总结
zookeeper的getData(),getChildren()和exists()方法都可以注册watcher监听。而监听有以下几个特性:
- 一次性触发(one-time trigger)
- 当数据改变的时候,那么一个Watch事件会产生并且被发送到客户端中。但是客户端只会收到一次这样的通知,如果以后这个数据再次发生改变的时候,之前设置Watch的客户端将不会再次收到改变的通知,因为Watch机制规定了它是一个一次性的触发器。当设置监视的数据发生改变时,该监视事件会被发送到客户端,例如,如果客户端调用了 getData(“/znode1”, true) 并且稍后 /znode1 节点上的数据发生了改变或者被删除了,客户端将会获取到 /znode1 发生变化的监视事件,而如果 /znode1 再一次发生了变化,除非客户端再次对 /znode1 设置监视,否则客户端不会收到事件通知
- 发送给客户端(Sent to the client)
- 这个表明了Watch的通知事件是从服务器发送给客户端的,是异步的,这就表明不同的客户端收到的Watch的时间可能不同,但是ZooKeeper有保证:当一个客户端在看到Watch事件之前是不会看到结点数据的变化的。例如:A=3,此时在上面设置了一次Watch,如果A突然变成4了,那么客户端会先收到Watch事件的通知,然后才会看到A=4
- Zookeeper 客户端和服务端是通过 Socket 进行通信的,由于网络存在故障,所以监视事件很有可能不会成功地到达客户端,监视事件是异步发送至监视者的,Zookeeper 本身提供了保序性(ordering guarantee):即客户端只有首先看到了监视事件后,才会感知到它所设置监视的 znode 发生了变化(a client will never see a change for which it has set a watch until it first sees the watch event). 网络延迟或者其他因素可能导致不同的客户端在不同的时刻感知某一监视事件,但是不同的客户端所看到的一切具有一致的顺序
- 被设置了watch的数据(The data for which the watch was set)
- 这是指节点发生变动的不同方式。你可以认为ZooKeeper维护了两个watch列表:data watch和child watch。getData()和exists()设置data watch,而getChildren()设置child watch。或者,可以认为watch是根据返回值设置的。getData()和exists()返回节点本身的信息,而getChildren()返回 子节点的列表。因此,setData()会触发znode上设置的data watch(如果set成功的话)。一个成功的 create() 操作会触发被创建的znode上的数据watch,以及其父节点上的child watch。而一个成功的 delete()操作将会同时触发一个znode的data watch和child watch(因为这样就没有子节点了),同时也会触发其父节点的child watch
- Watch由client连接上的ZooKeeper服务器在本地维护。这样可以减小设置、维护和分发watch的开销。当一个客户端连接到一个新的服务器上时,watch将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到watch的。而当client重新连接时,如果需要的话,所有先前注册过的watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch可能会丢失:对于一个未创建的znode的exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch事件可能会被丢失
对于watch,ZooKeeper提供了这些保障:
1、Watch与其他事件、其他watch以及异步回复都是有序的。ZooKeeper客户端库保证所有事件都会按顺序分发
2、客户端会保障它在看到相应的znode的新数据之前接收到watch事件
3、从ZooKeeper接收到的watch事件顺序一定和ZooKeeper服务所看到的事件顺序是一致的
注意事项
羊群效应
当变化发生时,ZooKeeper会触发这个znode节点的所有监视点集合。如果有1000个客户端通过exists操作监视这个节点,那么会发送1000个通知,因为被监视的znode节点的一个变化就会产生一个尖峰的通知,该尖峰可能带来影响,比如尖峰时刻提交的操作延迟。因此应该避免在一个特定节点设置大量的监视点,最好是每次在特定的znode节点上,只有少量的客户端设置监视点,理想情况下只有一个
ACL
每次创建znode节点时,必须设置访问权限,而且子节点并不会继承父节点的访问权限。访问权限的检查也是基于每一个znode节点的,一个客户端可以访问一个znode节点,即使它无权访问该节点的父节点
ZooKeeper通过访问控制表ACL来控制访问权限。一个ACL包括以下形式的记录:scheme:auth-info,其中scheme对应了一组内置的鉴权模式,auth-info为对于特定模式说对应的方式进行编码的鉴权信息。ZooKeeper通过检查客户端进程访问每个节点时提交上来的鉴权信息来保证安全性。如果一个进程没有提供鉴权信息,或者提供的信息与请求znode的信息不匹配,进程就会收到一个权限错误
// 鉴权模式 + 鉴权信息
public void addAuthInfo(String scheme, byte auth[]);
ZooDefs.Ids.OPEN_ACL_UNSAFE
ZooDefs.Ids.CREATOR_ALL_ACL
ZooDefs.Ids.READ_ACL_UNSAFE
扩展:
ZooKeeper ACL权限控制
ZooKeeper 笔记(5) ACL(Access Control List)访问控制列表
恢复会话
当ZK客户端崩溃时,其他程序还在继续运行,也许已经修改了ZK的状态,因此客户端恢复后不要再使用之前从ZK获取的缓存信息,而是使用ZK作为协作状态的可信来源。例如主从模式下的主节点崩溃恢复后,不能再认为自己是主节点,并认为待分配任务列表已经发生变化。其次客户端崩溃时,已提交给ZK的待处理操作可能已经完成,但由于崩溃导致无法收到确认信息,ZK无法保证这些操作一定完成,因此客户端恢复后需要进行一些ZK状态的清理操作,以便完成某些未完成的任务
创建znode节点时重置版本号
显而易见,znode节点被删除重建后,其版本号会被重置。如果应用程序在一个znode节点重建后,进行版本号检查会导致错误发生
sync方法
如果客户端只对ZK的读写来通信,那就不需要考虑sync方法。sync方法是为了隐藏通道导致的某些问题。比如一个客户端通过某些直接通道(如TCP)来通知另一个客户端进行ZK状态变化,但是另一个客户端读取ZK状态时却未发现变化的情况。这有可能因为这个客户端所连接的ZK还没来得及处理变化情况,而sync方法可以用于处理这种情况。sync为异步调用方法,客户端在读操作前调用该方法,加入客户端从某些直接通道收到了某个节点变化的通知,并要读取这个znode节点,客户端就可以使用sync方法,然后再调用getData方法:
//...
zk.sync(path, voidCallback, ctx);
zk.getData(path, watcher, dataCallback, ctx);
// ...
在系统内部,sync方法实际上并不会影响ZooKeeper,当服务端处理sync调用时,服务端会刷新群首与调用sync操作所连接服务端之间的通道,刷新就是在调用getData的返回数据时候,服务端确保返回所有在调用sync方法时有可能发生的变化情况,即变化情况的通信会先于sync操作的调用而发生
顺序性保障
连接丢失时的顺序性:同步方法的调用客户端库会抛出异常,异步的回调函数会返回结果码,因此应用程序依赖客户端库来解决所有后续操作。同时需要避免无限循环,可以设置重试次数,或者重新连接时间过长关闭句柄。当多个操作执行顺序有影响时,就需要等待完成后再提交后续请求,这很安全,但是带来了性能上的损失,不能将这些操作并行化
同步API和多线程的顺序性:多线程环境下使用同步API,同步调用会阻塞运行,直到收到响应信息。不同线程同时提交多个操作请求,如果具有相关性,需要客户端在处理结果时注意这些操作的提交顺序
同步和异步混合调用的顺序性:混合同步和异步调用通常不是好方法,可能因为同步方法阻塞导致后续异步方法的结果顺序与提交顺序不一致
数据字段和子节点的限制
ZooKeeper默认对数据字段的传输限制为1MB,该限制为任何节点数据字段的最大可存储字节,同时也限制了任何父节点可以拥有的子节点数
高级封装库
除了原生客户端库外,还有几种常用客户端库,比如zkclient、Curator
Zookeeper API不足之处:
1、Zookeeper的Watcher是一次性的,每次触发之后都需要重新进行注册
2、Session超时之后没有实现重连机制
3、异常处理繁琐,Zookeeper提供了很多异常,对于开发人员来说可能根本不知道该如何处理这些异常信息
4、只提供了简单的byte[]数组的接口,没有提供针对对象级别的序列化
5、创建节点时如果节点存在抛出异常,需要自行检查节点是否存在
6、删除节点无法实现级联删除
ZkClient
ZkClient是一个开源客户端,在Zookeeper原生API接口的基础上进行了包装,更便于开发人员使用。内部实现了Session超时重连,Watcher反复注册等功能。像dubbo等框架对其也进行了集成使用
虽然ZkClient对原生API进行了封装,但也有它自身的不足之处:
1、几乎没有参考文档
2、异常处理简化(抛出RuntimeException)
3、重试机制比较难用
4、没有提供各种使用场景的实现
Curator
Curator是Netflix公司开源的一套zookeeper客户端框架,将许多复杂操作隐藏起来,和ZkClient一样,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。此外还还提供了Zookeeper各种应用场景(Recipe,如共享锁服务、Master选举机制和分布式计算器等)的抽象封装
Curator包含了几个包:
curator-framework:对zookeeper的底层API的一些封装,大大简化Zookeeper客户端编程
curator-recipes:封装了一些高级特性,典型应用场景的实现,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等
curator-client:用于取代原生的Zookeeper客户端(ZooKeeper类),提供一些客户端的操作,例如重试策略等
大多数情况下都是使用curator-recipes包
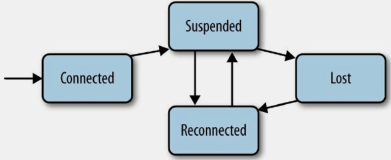
Curator连接状态机模型
创建会话
// RetryPolicy提供重试策略的接口,可以让用户实现自定义的重试策略
// 默认提供了以下实现,分别为ExponentialBackoffRetry、BoundedExponentialBackoffRetry、RetryForever、RetryNTimes、RetryOneTime、RetryUntilElapsed
// 给定一个初始化sleep时间baseSleepTimeMs,然后在此基础上设置重试次数
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// 还可以传入sessionTimeoutMs、connectionTimeoutMs
// 两种方法内部实现一样,只是对外包装成不同的方法。它们的底层都是通过第三个方法builder来实现的
CuratorFramework zkc = CuratorFrameworkFactory.newClient("127.0.0.1:2181", retryPolicy);
zkc.start();
创建包含隔离命名空间的会话:
// 指定一个Zookeeper的根路径,即该客户端对Zookeeper上的数据节点的操作都是基于该目录进行的
// 设置Chroot可以将客户端应用与Zookeeper服务端的一课子树相对应,在多个应用共用一个Zookeeper集群的场景下,这对于实现不同应用之间的相互隔离十分有意义
zkc = CuratorFrameworkFactory.builder()
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(retryPolicy)
// 将在/base下操作
.namespace("base")
.build();
节点操作
创建节点:
// 创建一个初始内容为空的节点,默认持久节点且内容为空
zkc.create().forPath(path);
// 创建一个包含内容的节点
zkc.create().forPath(path, content.getBytes());
// 创建一个包含内容的临时节点
zkc.create().withMode(CreateMode.EPHEMERAL).forPath(path, content.getBytes());
// 创建一个临时空的节点,并递归创建父节点,在递归创建父节点时,父节点为持久节点
zkc.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path);
删除节点:
// 删除一个子节点,且只能删除叶子节点
zkc.delete().forPath(path);
// 指定版本进行删除,如果此版本已经不存在,则删除异常
zkc.delete().withVersion(1).forPath(path);
// 删除节点并递归删除其子节点
zkc.delete().deletingChildrenIfNeeded().forPath(path);
// 强制保证删除一个节点,只要客户端会话有效,那么Curator会在后台持续进行删除操作,直到节点删除成功。比如遇到一些网络异常的情况,此guaranteed的强制删除就会很有效果
zkc.delete().guaranteed().forPath(path);
读取数据:
// 普通查询
zkc.getData().forPath(path);
// 包含状态查询
Stat stat = new Stat();
zkc.getData().storingStatIn(stat).forPath(path);
更新数据:
// 普通更新,当前最新版本,会返回一个Stat实例
zkc.setData().forPath(path, "new".getBytes());
// 指定版本更新,如果版本不一致抛出异常
zkc.setData().withVersion(1).forPath(path);
检查节点是否存在:
// 返回一个Stat实例,用于检查ZNode是否存在的操作
zkc.checkExists().forPath(path);
获取某个节点的所有子节点路径:
List<String> children = zkc.getChildren().forPath(path);
异步接口
同ZK原生API一样,有同步方法就有对应的异步方法,每一个接口都有一个inBackground()方法可供调用。此接口就是Curator提供的异步调用入口。对应的异步处理接口为BackgroundCallback。此接口指提供了一个processResult的方法,用来处理回调结果。其中processResult的参数event中的getType()包含了各种事件类型,getResultCode()包含了各种响应码
T inBackground();
T inBackground(Object var1);
T inBackground(BackgroundCallback var1);
T inBackground(BackgroundCallback var1, Object var2);
// 允许用一个专门线程池来处理返回结果之后的业务逻辑
T inBackground(BackgroundCallback var1, Executor var2);
T inBackground(BackgroundCallback var1, Object var2, Executor var3);
事务操作
zkc.inTransaction().check().forPath("/path")
.and()
.create().withMode(CreateMode.EPHEMERAL).forPath("/path", "data".getBytes())
.and()
.setData().withVersion(10).forPath("/path", "data2".getBytes())
.and()
.commit();
当前版本inTransaction方法已经废弃,使用transaction方法:
List<CuratorOp> operations = new ArrayList<CuratorOp>();
operations.add(zkc.transactionOp().check().forPath("/path"));
operations.add(zkc.transactionOp().create().withMode(CreateMode.EPHEMERAL).forPath("/path", "data".getBytes()));
operations.add(zkc.transactionOp().setData().withVersion(10).forPath("/path", "data2".getBytes()));
zkc.transaction().forOperations(operations);
监听器
第一种方式,与原生API类似的一次监听方式,使用usingWatcher来实现,不太实用:
byte[] content = zkc.getData().usingWatcher(new Watcher() {
public void process(WatchedEvent watchedEvent) {
System.out.println("监听器watchedEvent:" + watchedEvent);
}
}).forPath(path);
System.out.println("监听节点内容:" + new String(content));
第二种方式,监听器(listener)负责处理Curator库所产生的事件,此监听主要针对background通知和错误通知。使用此监听器之后,调用inBackground方法会异步获得监听,而对于节点的创建或修改则不会触发监听事件:
CuratorListener listener = new CuratorListener() {
public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("监听事件触发,event内容为:" + event);
try {
switch (event.getType()) {
case CHILDREN:
// ...
break;
case CREATE:
// ...
break;
case DELETE:
// ...
break;
case WATCHED:
// ...
break;
}
} catch (Exception e) {
// LOGGER.error
}
}
};
// 注册监听器
zkc.getCuratorListenable().addListener(listener);
还有一种监听器,负责处理后台工作线程捕获的异常:
UnhandledErrorListener errorListener = new UnhandledErrorListener() {
public void unhandledError(String message, Throwable e) {
// LOGGER.error
}
};
zkc.getUnhandledErrorListenable().addListener(errorListener);
另外ConnectionStateListener监听器监控连接的状态,当连接状态为LOST时,curator-recipes包下的所有Api将会失效或者过期
第三种方式,Curator引入了Cache来实现对Zookeeper服务端事件监听,Cache是Curator中对事件监听的包装,可以看作是对事件监听的本地缓存视图,Cache事件监听可以理解为一个本地缓存视图与远程Zookeeper视图的对比过程。Cache提供了反复注册的功能。Cache分为两类注册类型:节点监听和子节点监听;有三种:NodeCache、PathChildrenCache、TreeCache
public NodeCache(CuratorFramework client, String path);
public NodeCache(CuratorFramework client, String path, boolean dataIsCompressed);
final NodeCache nodeCache = new NodeCache(zkc, path);
// start方法有一个带Boolean参数的方法,如果设置为true则在首次启动时就会缓存节点内容到Cache中
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener() {
public void nodeChanged() throws Exception {
System.out.println("重新获得节点内容为:" + new String(nodeCache.getCurrentData().getData()));
}
});
NodeCache不仅可以监听节点内容变化,还可以监听指定节点是否存在。如果原本节点不存在,那么Cache就会在节点被创建时触发监听事件,如果该节点被删除,就无法再触发监听事件
PathChildrenCache用于监听数据节点子节点的变化情况:
PathChildrenCache pathChildrenCache = new PathChildrenCache(zkc, parentPath, true);
pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("事件类型:" + event.getType() + ";操作节点:" + event.getData().getPath());
}
});
PathChildrenCache不会对二级子节点进行监听,只会对子节点进行监听。而TreeCache可以监听到指定节点下所有节点的变化
另外需要注意的是,zookeeper原生API注册Watcher需要反复注册,即Watcher触发之后就需要重新进行注册。另外,客户端断开之后重新连接到服务器也是需要一段时间。这就导致了zookeeper客户端不能够接收全部的zookeeper事件。zookeeper保证的是数据的最终一致性。因此,对于此问题需要特别注意,在不要对zookeeper事件进行强依赖。虽然curator帮开发人员封装了重复注册监听的过程,但是内部依旧需要重复进行注册,而在第一个watcher触发第二个watcher还未注册成功的间隙,进行节点数据的修改,显然无法收到watcher事件
高级特性
缓存Cache特性在上面已经讲过
群首选举
基本思路和之前的一样,通过创建/master来确定主节点。Curator所做的事情就是进行了封装,把原生API的节点创建、事件监听和自动选举进行整合封装,提供了一套简单易用的解决方案
LeaderLatch:随机从候选者中选出一台作为leader,需要主动调用close释放领导权,否则其他的后选择无法成为leader。如果一个client连接断开后,会在存活的client中重新选出leader。spark使用的就是这种方法:
List<LeaderLatch> latchList = new ArrayList();
List<CuratorFramework> clients = new ArrayList();
String path = "/master";
try {
for (int i = 0; i < 5; i++) {
final CuratorFramework client = connect();
clients.add(client);
String clientId = "client#" + i;
final LeaderLatch leaderLatch = new LeaderLatch(client, path, clientId);
leaderLatch.addListener(new LeaderLatchListener() {
public void isLeader() {
System.out.println(leaderLatch.getId() + ":I am leader. I am doing jobs!");
try {
Thread.sleep(1000 * 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主动close释放领导权
client.close();
}
public void notLeader() {
System.out.println(leaderLatch.getId() + ":I am not leader. I will do nothing!");
}
});
leaderLatch.start();
}
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
} finally {
for(CuratorFramework client : clients){
CloseableUtils.closeQuietly(client);
}
for(LeaderLatch leaderLatch : latchList){
CloseableUtils.closeQuietly(leaderLatch);
}
}
LeaderLatch通过增加了一个ConnectionStateListener监听连接。如果出现SUSPENDED或者LOST,leader会报告自己不再是leader(直到重新建立连接,否则不会有leader)。如果LOST的连接被重新建立即RECONNECTED,leaderLatch会删除先前的zNode并重新建立zNode
LeaderSelector:可以对领导权进行控制, 在适当的时候释放领导权,这样每个节点都有可能获得领导权。当被选为leader之后,调用takeLeadership方法进行业务逻辑处理,处理完成即释放领导权。其中autoRequeue()方法的调用确保此实例在释放领导权后还可能获得领导权:
List<LeaderSelector> selectors = new ArrayList();
List<CuratorFramework> clients = new ArrayList();
String path = "/master";
try {
for (int i = 0; i < 5; i++) {
CuratorFramework client = connect();
clients.add(client);
final String name = "client#" + i;
LeaderSelector leaderSelector = new LeaderSelector(client, path, new LeaderSelectorListener() {
public void takeLeadership(CuratorFramework client) throws Exception {
System.out.println(name + ":I am leader.");
Thread.sleep(2 * 1000);
}
public void stateChanged(CuratorFramework client, ConnectionState newState) {
switch (newState) {
case CONNECTED:
// ...
break;
case SUSPENDED:
// ...
break;
case LOST:
// ...
}
}
});
leaderSelector.autoRequeue();
leaderSelector.start();
selectors.add(leaderSelector);
}
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
} finally {
for(CuratorFramework client : clients){
CloseableUtils.closeQuietly(client);
}
for(LeaderSelector selector : selectors){
CloseableUtils.closeQuietly(selector);
}
}
LeaderSelectorListener类继承了ConnectionStateListener。一旦LeaderSelector启动,它会向curator客户端添加监听器。 使用LeaderSelector必须时刻注意连接的变化。一旦出现连接问题如SUSPENDED,curator实例必须确保它可能不再是leader,直至它重新收到RECONNECTED。如果LOST出现,curator实例不再是leader并且其takeLeadership()应该直接退出。推荐的做法是,如果发生SUSPENDED或者LOST连接问题,最好直接抛CancelLeadershipException,此时,leaderSelector实例会尝试中断并且取消正在执行takeLeadership方法的线程。建议扩展LeaderSelectorListenerAdapter,LeaderSelectorListenerAdapter中已经提供了推荐的处理方式
注意点:
通过Leader选举可以选举出一台机器来执行定时任务。这里有两种选择:
1、选出Leader之后,以后所有的定时任务都由此台机器执行
2、每次到执行Job的时候重新进行一次竞选,成为Leader者进行执行
针对以上两种情况就需要考虑一下问题:
1、第一种方案如果Leader选出之后,Leader在执行定时任务宕机,后面如何进行重新Leader选举
2、第二种方案如果服务器的时间不一致如何处理?如果每台机器Job执行的时间不一致如何处理?如果任务执行的时间很短暂,Leader执行之后马上释放,后面因网络延迟等原因又获得Leader权限重新执行了任务,如何处理?
3、定时任务的幂等性保证
分布式锁
Curator提供的InterProcessMutex是分布式锁的实现。acquire方法用户获取锁,release方法用于释放锁:
InterProcessMutex interProcessMutex = new InterProcessMutex(zkc, path);
interProcessMutex.acquire();
// interProcessMutex.acquire(timeout, unit);
interProcessMutex.release();
Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。
然后使用Zookeeper也有可能带来并发问题,只是并不常见。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点