Dubbo(一):从dubbo-demo初探dubbo源码
Dubbo(二):架构与SPI
Dubbo(三):高并发下降级与限流
Dubbo(四):其他常用特性
Dubbo(五):自定义扩展
前提
超时(timeout):在接口调用过程中,Consumer调用Provider的时候,如果Provider要10s响应,那么Consumer也会至少10s才响应。这种响应时间慢的症状会像波浪一样一层一层从底层系统一直传到最上层,造成整个链路的超时,降低整体的服务性能。所以Consumer不可能无限制地等待Provider接口的返回,需要设置一个时间阈值,超过了这个时间阈值后就不再继续等待。对于一条链路A-B-C…,如果链路前面的超时时间短于后面的,也是不合理的,链路前面直接挂断,后面设置太长是没任何意义的。同样由于涟漪效应,链路后面服务的抖动,如果上游没有处理好,会一直传递给最上层,所以从整个体系的角度来看,每个服务一定要尽量控制住自己下游服务的抖动,不要让整个体系跟着某个服务抖动。更严重一点的是如果某个服务出现故障不可用了,传递性地导致整个系统服务不可用,因此也需要尽量减少关键路径依赖的数量,并且缩短路径,缩短最长时间路径的用时,提高服务稳定性
重试(retry):超时时间的配置是为了保护服务,尽量保持Consumer原有的性能。但是也有可能Provider只是偶尔抖动,那么超时后直接放弃不做后续处理,就会导致当前请求错误,也会带来业务方面的损失。因此对于这种偶尔抖动,可以在超时后重试一下,比如换一台服务器进行调用,避免因为之前服务器临时负载较高导致的超时失败,当然带来的代价就是比原来的响应更慢一点。和超时类似,对于一条链路A-B-C…,如果后面的性能不好导致要重试,会造成链路前的服务超时,所以站在长链路的视角来思考,我们需要整体规划每个服务的超时时间和重试次数
幂等(idempotent):如果允许Consumer做重试,那么Provider就要能够做到幂等,意为无论同一个请求被Consumer调用几次,Provider产生的影响是一致的。而且这个幂等应该是服务级别的,而不是某台机器层面的,重试调用任何一台机器都需要做到幂等
在高并发系统中,有很多方法来保护系统,比如:缓存、降级、限流等
降级(fallback)
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心服务正常运作或高效运作。也可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。简单讲,就是在调用的下游服务出现问题(常见超时)时提供PLAN-B,或者在大流量冲击下暂时放弃非关键服务
降级分类:
- 是否自动化
- 自动开关降级
- 超时降级:配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
- 失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值、兜底数据、缓存
- 限流降级:当达到限流阀值,后续请求会被降级,比如抢购降级后的处理方案可以是:排队页面、无货、错误页
- 人工开关降级
- 自动开关降级
- 功能
- 读服务降级:比如一些直接从DB读取的数据,改为从缓存中获取
- 写服务降级:比如在秒杀抢购业务中,由于并发的数量比较大。除了在各个层面上限流、使用队列等方式应对,还可以对写库进行降级,可以将库存扣减操作在内存中进行,当高峰过去之后,再异步的同步至DB中做扣减操作
- 访问链路
- 页面降级:比如在大促时,某些页面占用了稀缺资源,可以对整个页面进行降级。或者当页面上会异步加载推荐信息等一些非核心的业务时,此时如果响应变慢,则可以进行降级处理
- 其他类型:比如在系统繁忙时,可以将爬虫的流量直接丢弃,当高峰过后,再自动恢复。秒杀业务中,风控系统可以识别刷子/机器人,然后可以直接对这些用户执行拒绝服务
对于服务降级这个问题,如果从整体来操作:
1、一定是先降级优先级低的接口,两权相害取其轻,区分核心和非核心服务
2、如果服务链路整体没有性能特别差的点,比如就是外部流量突然激增,那么就从外到内开始降级
3、如果某个服务能检测到自身负载上升,那么可以从这个服务自身做降级
4、业务支持降级策略,放通策略
dubbo实现
dubbo提供了一些服务降级措施,当服务提供端某一个非关键的服务出错时候,在dubbo中可以对消费端的调用进行降级,这样服务消费端就避免了在去调用出错的服务提供端,而是使用自定义的返回值直接在在本地返回,但是比如相比Spring Cloud的熔断机制,不能自动熔断和恢复,显得不智能
dubbo可以使用mock来设置本地伪装,提供了两种服务降级策略:
1、force:return策略:表示服务调用方在调用该接口服务时候会直接在客户端内返回设置的mock值,而不会在通过远程调用方式调用服务提供者。比如使用mock=force:return+null表示消费方对该服务的方法调用都直接返回null值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响
2、fail:return策略:表示服务调用方调用服务提供方服务失败后再返回设置的mock值,并不会抛出异常。需要注意的是并不是调用一次失败后就直接返回mock值,具体和设置的集群容错方式(retries)有关。比如使用mock=fail:return+null表示消费方对该服务的方法调用在失败后(在抛出RpcException异常时执行),不抛异常直接返回null值。用来容忍不重要服务不稳定时对调用方的影响
// 获取服务注册中心工厂
RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();
// 根据zk地址,获取具体的zk注册中心的客户端实例
Registry registry = registryFactory.getRegistry(URL.valueOf("zookeeper://127.0.0.1:2181"));
// 注册降级方案到zk,对test分组1.0.0版本的服务降级。category必须为configurators,override://0.0.0.0/表示该降级策略对所有的服务消费者生效
// dynamic=false表示该数据为持久数据,注册放退出依旧保存在注册中心,application表示只对指定应用生效,否则表示所有应用生效
registry2.register(URL.valueOf(
"override://0.0.0.0/com.test.TestService?category=configurators&dynamic=false&application=myConsumer&mock=force:return+null&group=test&version=1.0.0"
));
设置完后可以在管理控制台查看,也可以直接在控制台进行手工操作。当服务消费者启动时候会去ZK订阅com.test.TestService子树中的信息,比如Providers(服务提供者列表)、Routes(路由信息)、Configurators(服务降级策略等信息)。当服务消费者具体发起远程调用时候会根据路由规则和负载均衡算法从服务提供者列表选择一个IP作为调用目标,然后具体发起远程调用前,会看是否设置了force:return降级策略,如果设置了则直接返回mock值,并不发起远程调用。否者发起远程调用,如果远程调用结果成功,则直接返回远程调用返回的结果。如果远程调用失败,则看当前的集群从容策略是什么,如果是失败重试,那么还要看通过retries设置的重试次数是多少,比如重试2次,则会在调用失败后再进行重试两次调用,如果其中一次成功了则直接返回结果。如果两次都失败了,则看当前是否设置了fail:return的降级策略,如果设置了则直接返回mock值,否者返回调用远程服务失败的具体原因
服务消费端订阅降级策略并保存
服务消费端的启动流程:
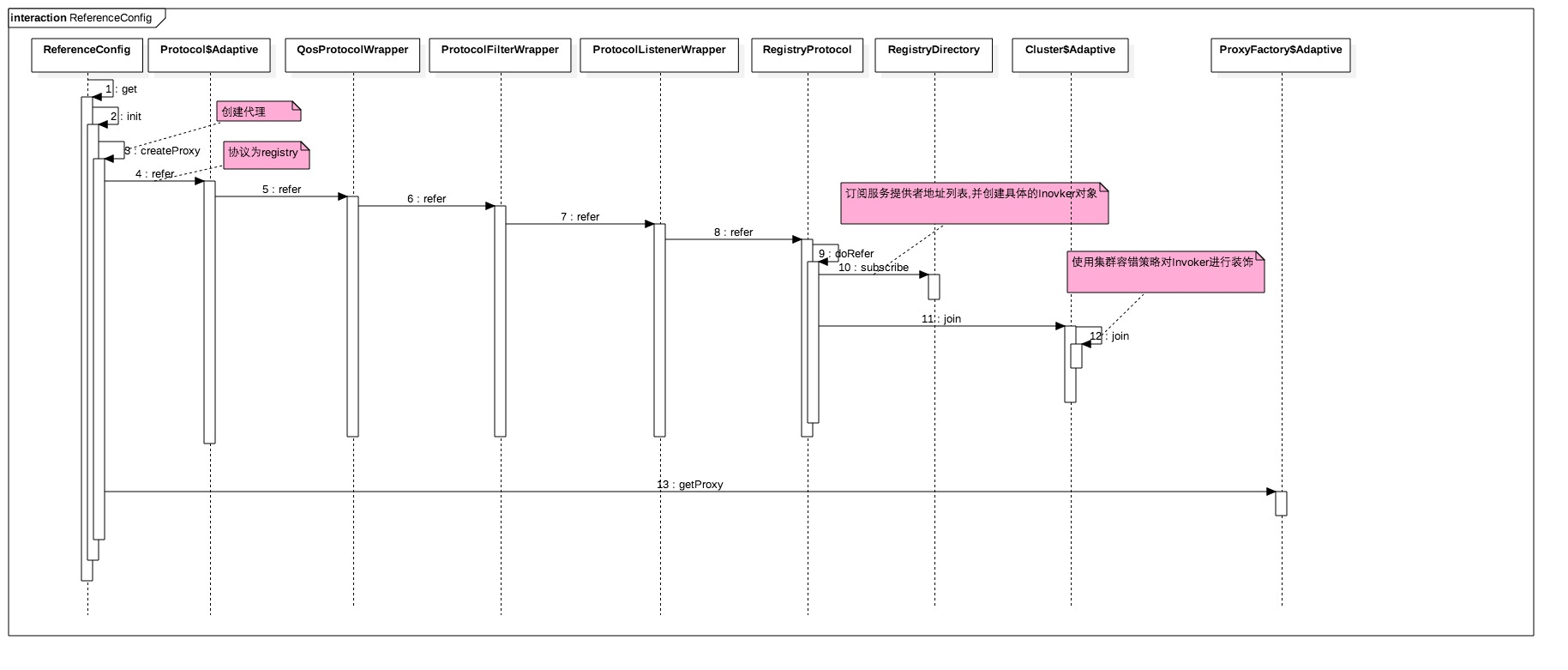 在步骤10中具体是消费端从ZK获取设置的降级策略:
在步骤10中具体是消费端从ZK获取设置的降级策略:
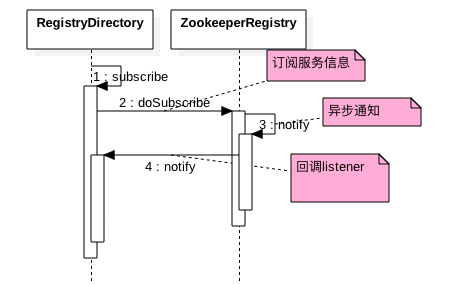 其中消费端从ZK订阅服务信息,ZK在准备好数据后会异步把数据发送给注册的listener,而RegistryDirectory本身就是一个listener,所以zkclient会把服务数据传递给RegistryDirectory的notify方法:
其中消费端从ZK订阅服务信息,ZK在准备好数据后会异步把数据发送给注册的listener,而RegistryDirectory本身就是一个listener,所以zkclient会把服务数据传递给RegistryDirectory的notify方法:
public synchronized void notify(List<URL> urls) {
// 存放服务提供者列表
List<URL> invokerUrls = new ArrayList<URL>();
// 存放设置的路由规则
List<URL> routerUrls = new ArrayList<URL>();
// 存放设置的降级策略等
List<URL> configuratorUrls = new ArrayList<URL>();
// 设置不同类别的信息
for (URL url : urls) {
String protocol = url.getProtocol();
String category = url.getParameter(Constants.CATEGORY_KEY, Constants.DEFAULT_CATEGORY);
if (Constants.ROUTERS_CATEGORY.equals(category)
|| Constants.ROUTE_PROTOCOL.equals(protocol)) {
routerUrls.add(url);
} else if (Constants.CONFIGURATORS_CATEGORY.equals(category)
|| Constants.OVERRIDE_PROTOCOL.equals(protocol)) {
configuratorUrls.add(url);
} else if (Constants.PROVIDERS_CATEGORY.equals(category)) {
invokerUrls.add(url);
} else {
logger.warn("Unsupported category " + category + " in notified url: " + url + " from registry " + getUrl().getAddress() + " to consumer " + NetUtils.getLocalHost());
}
}
// configurators 解析服务降级策略等到configurators
if (configuratorUrls != null && !configuratorUrls.isEmpty()) {
this.configurators = toConfigurators(configuratorUrls);
}
// routers 解析路由规则到 routers
if (routerUrls != null && !routerUrls.isEmpty()) {
List<Router> routers = toRouters(routerUrls);
if (routers != null) { // null - do nothing
setRouters(routers);
}
}
List<Configurator> localConfigurators = this.configurators; // local reference
// merge override parameters ---> 具体这里把降级策略拼接到url
this.overrideDirectoryUrl = directoryUrl;
if (localConfigurators != null && !localConfigurators.isEmpty()) {
for (Configurator configurator : localConfigurators) {
this.overrideDirectoryUrl = configurator.configure(overrideDirectoryUrl);
}
}
// providers 刷新本地服务提供者列表providers
refreshInvoker(invokerUrls);
}
服务消费端使用降级策略
服务消费端具体使用降级策略是在MockClusterInvoker类的invoker方法里面:
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
// 查看url里面是否有mock字段
String value = directory.getUrl().getMethodParameter(invocation.getMethodName(), Constants.MOCK_KEY, Boolean.FALSE.toString()).trim();
if (value.length() == 0 || value.equalsIgnoreCase("false")) {
// no mock 或 值为默认false时 -> 正常调用
result = this.invoker.invoke(invocation);
} else if (value.startsWith("force")) {
if (logger.isWarnEnabled()) {
logger.warn("force-mock: " + invocation.getMethodName() + " force-mock enabled , url : " + directory.getUrl());
}
// force:direct mock -> 直接返回mock值
result = doMockInvoke(invocation, null);
} else {
// fail-mock -> 失败后返回mock值
try {
result = this.invoker.invoke(invocation);
} catch (RpcException e) {
if (e.isBiz()) {
throw e;
} else {
if (logger.isWarnEnabled()) {
logger.warn("fail-mock: " + invocation.getMethodName() + " fail-mock enabled , url : " + directory.getUrl(), e);
}
// 返回mock值
result = doMockInvoke(invocation, e);
}
}
}
return result;
}
本地伪装
dubbo的本地伪装通常用于服务降级,比如某验权服务,当服务提供方全部挂掉后,客户端不抛出异常,而是通过Mock数据返回授权失败。在 spring 配置文件中按以下方式配置:
<dubbo:reference interface="com.foo.BarService" mock="true" />
或
<dubbo:reference interface="com.foo.BarService" mock="com.foo.BarServiceMock" />在工程中提供Mock实现
或
<dubbo:reference interface="com.foo.BarService" mock="return null" />
特别的,对于return来返回一个字符串表示的对象,作为Mock的返回值。合法的字符串可以是:
1、empty: 代表空,基本类型的默认值,或者集合类的空值
2、null: null
3、true: true
4、false: false
5、JSON 格式: 反序列化JSON所得到的对象
也可以使用throw来返回一个Exception对象,作为Mock的返回值:
当调用出错时,抛出一个默认的 RPCException:
<dubbo:reference interface="com.foo.BarService" mock="throw" />
当调用出错时,抛出指定的 Exception:
<dubbo:reference interface="com.foo.BarService" mock="throw com.foo.MockException" />
其他就是上面写到的两种降级方式的force和fail,并且可以在方法级别配置Mock
熔断(circuit break)
在高并发访问下,dubbo服务依赖的稳定性与否对系统的影响非常大,但是依赖有很多不可控问题,比如网络连接缓慢、资源繁忙、暂时不可用、服务脱机等。服务器压力剧增导致Provider持续的响应时间超长或直接崩溃,那么如果该服务不是核心路径的服务,就会因为这个服务一直响应超长导致Consumer的核心服务被拖慢,那么就得不偿失了。当高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险!这种现象被称为雪崩现象
以单纯的超时解决不了这种情况,因为一般超时时间都比平均响应时间长一些,现在所有调用到Provider的请求都超时了,那么Consumer请求的平均响应时间就等于超时时间了,负载也被拖下来了。而重试只是为了应付偶尔抖动的情况,以求更多地挽回损失,这时反而会加重这种问题,使Consumer的可用性变得更差。因此就出现了熔断器,就是说如果检查出来频繁超时,就把Consumer调用Provider的请求直接短路掉(降级),不实际调用,直接返回一个mock的值,等Provider服务恢复稳定之后,再重新调用。简单讲,熔断器就是一根保险丝,保障何时走到降级方法、何时恢复、以什么样的策略恢复,对依赖做隔离(快速失败)
服务降级和服务熔断的异同:
相同点:
1、目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段
2、最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用
3、粒度一般都是服务级别,当然业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改)
4、自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下完全靠人显然不可能,开关预置、配置中心都是必要手段
相异点:
1、触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑
2、管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
3、实现方式不太一样
所以从某种角度讲,熔断也可以算是降级的一种实现
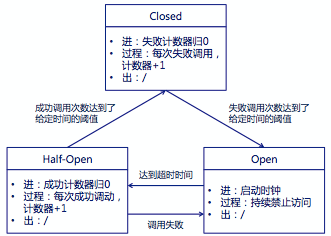
一般来说熔断器需要实现三个状态机:
1、Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制
2、Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态
3、Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态
dubbo本身没有熔断器,需要自己实现,或者整合Spring Cloud NetFlix Hystrix框架
Hystrix
Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。可配置依赖调用超时时间,当调用超时时直接返回或执行fallback逻辑。为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间。请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。提供近实时依赖的统计和监控
在Hystrix的整个机制中,涉及到依赖边界的地方,都是通过这个Command模式进行调用的,显然这个Command负责了核心的服务熔断和降级的处理,子类要实现的方法主要有两个:
1、run方法:实现依赖的逻辑,或者说是实现服务之间的调用
2、getFallBack方法:实现服务降级处理逻辑,只做熔断处理的则可不实现
流程结构
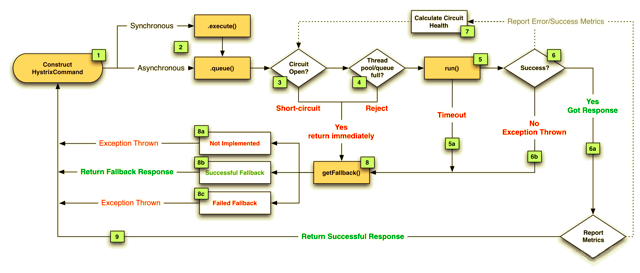 1、每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中
1、每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中
2、执行execute/queue做同步或异步调用
3、判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤4
4、判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤
5、调用HystrixCommand的run方法,运行依赖逻辑
5a、依赖逻辑调用超时,进入步骤8
6、判断逻辑是否调用成功
6a、返回成功调用结果
6b、调用出错,进入步骤8
7、计算熔断器状态,所有的运行状态(成功、失败、拒绝、超时)上报给熔断器,用于统计从而判断熔断器状态
8、getFallback()降级逻辑
以下四种情况将触发getFallback调用:
(1) run()方法抛出非HystrixBadRequestException异常
(2) run()方法调用超时
(3) 熔断器开启拦截调用
(4) 线程池/队列/信号量是否跑满
8a、没有实现getFallback的Command将直接抛出异常
8b、fallback降级逻辑调用成功直接返回
8c、降级逻辑调用失败抛出异常
9、返回执行成功结果
线程隔离: 把执行依赖代码的线程与请求线程分离,请求线程可以自由控制离开的时间(异步过程)。通过线程池大小可以控制并发量,当线程池饱和时可以提前拒绝服务,防止依赖问题扩散。线上建议线程池不要设置过大,否则大量堵塞线程有可能会拖慢服务器
信号量隔离: 信号隔离也可以用于限制并发访问,防止阻塞扩散,与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请),如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销
配置线程隔离,则执行中断处理;配置信号量隔离,则进行终止操作。因为信号量隔离和主线程是在一个线程中执行,其不会中断线程处理。所以要根据实际情况选择类型。线程池隔离:对每个command创建一个自己的线程池,执行调用。通过线程池隔离来保证不同调用不会相互干扰和每一个调用的并发限制。信号量隔热:对每个command创建一个自己的计数器,当并发量超过计数器指定值时,直接拒绝。使用信号量和线程池的一个区别是,信号量没有timeout机制
Demo
超时降级
配置参数:
1、withFallbackEnabled:是否启用降级,默认开启。若启用则在超时或异常时调用getFallback进行降级
2、withFallbackIsolationSemaphoreMaxConcurrentRequests:配置了fallback()请求并发的信号量,当调用fallback()的并发超过阀值(默认10),则会进入快速失败
3、withExecutionIsolationThreadInterruptOnFutureCancel:当隔离策略为THREAD时,当线程执行超时,是否进行中断处理,即异步的Future#cancel()。默认为false
4、withExecutionIsolationThreadInterruptOnTimeout:当隔离策略为THREAD时,当线程执行超时,是否进行中断处理。默认为true,这里指的是同步调用:execute()
5、withExecutionTimeoutEnabled:是否启用超时机制,默认为true
6、withExecutionTimeoutInMilliseconds:执行超时时间,默认1000毫秒
1、首先加上maven依赖:
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-core</artifactId>
<version>1.5.18</version>
</dependency>
2、实现类继承HystrixCommand:
public class HystrixFallbackTest extends HystrixCommand<String> {
private HelloService helloService;
public HystrixFallbackTest(HelloService helloService) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("FallbackGroup"))
// 10秒超时
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(10000)));
this.helloService = helloService;
}
@Override
protected String run() throws Exception {
// 方法内sleep10秒以上,触发超时fallback
return helloService.sayHello();
}
@Override
protected String getFallback() {
return "hello fallback";
}
}
// 同步调用
new HystrixFallbackTest(new HelloService()).execute()
对于getFallback()还需要注意以下的几点:
1、最大并发数受fallbackIsolationSemaphoreMaxConcurrentRequests控制,如果失败率非常高,则需要重新配置该参数。如果并发数超过了该配置,则不会再执行getFallback(),而是快速失败。如抛出HystrixRuntimeException的异常
2、该方法不进行网络调用,只是返回兜底的数据
3、如果必须要走一个网络调用,则就需要调用另外一个Command
4、Command可以有降级和熔断机制,而getFallback只有fallbackIsolationSemaphoreMaxConcurrentRequest参数控制最大并发数
失败熔断
Command首先调用HystrixCircuitBreaker#allowRequest判断是否熔断了,如果没有则执行Command#run方法;若熔断了则直接调用Command#getFallback方法降级处理
对于熔断阈值设置,在HystrixCommand构造方法中有一个HystrixPropertiesStrategy策略类,返回相关属性的配置,其中有:
1、circuitBreakerEnabled:是否开启熔断机制,默认为true
2、circuitBreakerErrorThresholdPercentage:如果在一个采样时间窗口内,失败率超过该配置,则自动打开熔断开关,快速失败。默认采样周期为10秒,失败率为50%
3、circuitBreakerRequestVolumeThreshold:在熔断开关闭合的情况下,在进行失败率判断之前,一个采样周期内必须进行至少N个请求才能进行采样统计。目的是有足够的采样使得失败率计算的比较接近真实值,默认为20
4、circuitBreakerSleepWindowInMilliseconds:熔断后的重试时间窗口,在窗口内只允许一次重试。在熔断开关打开后,若重试成功,则重试Health采样统计,并闭合熔断开关实现快速恢复。否则熔断开关还是打开状态,会进行快速失败
5、withCircuitBreakerForceClosed:是否强制关闭熔断开关,如果强制关闭了熔断开关,则请求不会被降级,一些场景可以动态设置该开关,默认为false
6、withCircuitBreakerForceOpen:是否强制打开熔断开关,如果打开了,则请求强制降级调用getFallback处理,可以通过动态配置来打开开关实现一些特殊需求,默认为false
同样实现类继承HystrixCommand:
public HystrixCircuitBreakerTest(String name, MorningService morningService) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("CircuitBreakerTestGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("CircuitBreakerTestKey"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("CircuitBreakerTest"))
.andThreadPoolPropertiesDefaults( // 配置线程池
HystrixThreadPoolProperties.Setter()
.withCoreSize(200) // 配置线程池里的线程数,设置足够多线程,以防未熔断却打满threadpool
)
.andCommandPropertiesDefaults( // 配置熔断器
HystrixCommandProperties.Setter()
.withCircuitBreakerEnabled(true) // 熔断器在整个统计时间内是否开启的阀值
.withCircuitBreakerRequestVolumeThreshold(3) // 至少有3个请求才进行熔断错误比率计算
.withCircuitBreakerErrorThresholdPercentage(50) //当出错率超过50%后熔断器启动
.withMetricsRollingStatisticalWindowInMilliseconds(5000) // 统计滚动的时间窗口
.withCircuitBreakerSleepWindowInMilliseconds(1000) // 熔断器工作时间,超过这个时间,先放一个请求进去,成功的话就关闭熔断,失败就再等一段时间
)
);
this.helloService = helloService;
}
@Override
protected String run() throws Exception {
// 随机成功或超时
return helloService.sayBye();
}
new HystrixCircuitBreakerTest(new HelloService()).execute();
// 熔断器是否打开
boolean isOpen = HystrixCircuitBreaker.Factory.getInstance(HystrixCommandKey.Factory.asKey("CircuitBreakerTestKey")).isOpen()
采样统计
Hystrix在内存中存储采样数据,支持如下3种采样:
1、BucketedCounterStream:计数统计。记录一定时间窗口内的失败、超时、线程池拒绝、信号量拒绝数量。写入第N组时,用前N-1组统计,然后基于时间窗口平滑后移统计
2、RollingConcurrencyStream:最大并发数统计。如Command/ThreadPool的最大并发数
3、RollingDistributionStream:延迟百分比统计,和HystrixRollingNumber类似,差别在于其是百分位数的统计。比如每组记录P(如100)个数值,统计时用前N-1组数据,将分组数据按从小到大排序,然后累加,处于p%位置的就是p百分位数,通过它可以实现P50、P99、P999,Hystrix用来统计延时的分布情况
继续上面的配置:
7、withMetricsRollingStatisticalWindowInMilliseconds:配置采样统计滚转之间窗口,默认为10秒
8、withMetricsRollingStatisticalWindowBuckets:配置采用统计滚转时间窗口内的桶的总数量,默认为10,比如时间窗口为10000,桶数量为10,则采用统计间隔为每秒一个桶统计
9、withMetricsHealthSnapshotIntervalInMilliseconds:记录健康度采用统计的快照频率,默认为500ms,即500ms一个采样统计间隔,那么桶的数量为10000/500=20个
该统计在熔断机制中使用时,如果计算熔断的频率非常高,则需要控制好采样的频率。如果太频繁,就有可能造成CPU计算密集。所以选择Hystrix要注意此处的性能消耗和调优,如果此处是瓶颈,则可以费除掉统计
依赖隔离/限流
依赖命名CommandKey:每个CommandKey代表一个依赖抽象,相同的依赖要使用相同的CommandKey名称。依赖隔离的根本就是对相同CommandKey的依赖做隔离
依赖分组CommandGroup:CommandGroup是每个命令最少配置的必选参数,在不指定ThreadPoolKey的情况下,字面值用于对不同依赖的线程池/信号区分。用于对依赖操作分组,便于统计、汇总等
线程池/信号ThreadPoolKey:当对同一业务依赖做隔离时使用CommandGroup做区分,但是对同一依赖的不同远程调用如(一个是redis一个是http),可以使用HystrixThreadPoolKey做隔离区分。虽然在业务上都是相同的组,但是需要在资源上做隔离时,可以使用HystrixThreadPoolKey区分
上面的例子用到了线程池,Hystrix可以使用“舱壁模式”实现线程池的隔离,它会为每一个Hystrix命令创建一个独立的线程池,这样就算某个在Hystrix命令包装下的依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的服务
通过对依赖服务的线程池隔离实现,可以带来如下优势:
1、应用自身得到完全的保护,不会受不可控的依赖服务影响。即便给依赖服务分配的线程池被填满,也不会影响应用自身的额其余部分
2、可以有效的降低接入新服务的风险。如果新服务接入后运行不稳定或存在问题,完全不会影响到应用其他的请求
3、当依赖的服务从失效恢复正常后,它的线程池会被清理并且能够马上恢复健康的服务,相比之下容器级别的清理恢复速度要慢得多
4、当依赖的服务出现配置错误的时候,线程池会快速的反应出此问题(通过失败次数、延迟、超时、拒绝等指标的增加情况)。同时可以在不影响应用功能的情况下通过实时的动态属性刷新来处理它
5、当依赖的服务因实现机制调整等原因造成其性能出现很大变化的时候,此时线程池的监控指标信息会反映出这样的变化。同时也可以通过实时动态刷新自身应用对依赖服务的阈值进行调整以适应依赖方的改变
6、除了上面通过线程池隔离服务发挥的优点之外,每个专有线程池都提供了内置的并发实现,可以利用它为同步的依赖服务构建异步的访问
总之,通过对依赖服务实现线程池隔离,让我们的应用更加健壮,不会因为个别依赖服务出现问题而引起非相关服务的异常。同时也使得我们的应用变得更加灵活,可以在不停止服务的情况下,配合动态配置刷新实现性能配置上的调整。而且不用过于担心每一个依赖服务都分配一个线程池是否会过多地增加系统的负载和开销。Netflix在设计Hystrix的时候,认为线程池上的开销相对于隔离所带来的好处是无法比拟的。同时,Netflix也针对线程池的开销做了相关的测试,以证明和打消Hystrix实现对性能影响的顾虑
注解方式
使用注解方式配置@HystrixCommand时,dubbo框架对内部异常进行了封装,导致异常抛出后直接进入了dubbo处理流程。因此可以定义一个Filter,拦截dubbo的请求,对response进行分析,拿到success/exception,根据这里的结构,进入降级流程:
@Activate(group = "consumer")
public class HystrixFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
DubboHystrixCommand command = new DubboHystrixCommand(invoker, invocation, "aaa");
Result res = command.execute();
return res;
}
}
实现HystrixCommand:
public class DubboHystrixCommand extends HystrixCommand<Result> {
private static Logger logger = LoggerFactory.getLogger(DubboHystrixCommand.class);
private static final int DEFAULT_THREADPOOL_CORE_SIZE = 30;
private Invoker invoker;
private Invocation invocation;
private String fallbackName;
public DubboHystrixCommand(Invoker<?> invoker, Invocation invocation, String fallbackName) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey(invoker.getInterface().getName()))
.andCommandKey(HystrixCommandKey.Factory.asKey(String.format("%s_%d", invocation.getMethodName(), invocation.getArguments() == null ? 0 : invocation.getArguments().length)))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withCircuitBreakerRequestVolumeThreshold(20) // 10秒钟内至少19此请求失败,熔断器才发挥起作用
.withCircuitBreakerSleepWindowInMilliseconds(3000) // 熔断器中断请求30秒后会进入半打开状态,放部分流量过去重试
.withCircuitBreakerErrorThresholdPercentage(50) // 错误率达到50开启熔断保护
.withExecutionTimeoutEnabled(false) // 使用dubbo的超时,禁用这里的超时
)
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(getThreadPoolCoreSize(invoker.getUrl())))); // 线程池为30
this.invoker = invoker;
this.invocation = invocation;
this.fallbackName = fallbackName;
}
/**
* 获取线程池大小
* <dubbo:parameter key="ThreadPoolCoreSize" value="20" />
*
* @param url
* @return
*/
private static int getThreadPoolCoreSize(URL url) {
if (url != null) {
int size = url.getParameter("ThreadPoolCoreSize", DEFAULT_THREADPOOL_CORE_SIZE);
if (logger.isDebugEnabled()) {
logger.debug("ThreadPoolCoreSize:" + size);
}
return size;
}
return DEFAULT_THREADPOOL_CORE_SIZE;
}
@Override
protected Result run() throws Exception {
Result res = invoker.invoke(invocation);
if (res.hasException()) {
throw new HystrixRuntimeException(HystrixRuntimeException.FailureType.COMMAND_EXCEPTION,
DubboHystrixCommand.class,
res.getException().getMessage(),
res.getException(), null);
}
return res;
}
@Override
protected Result getFallback() {
if (StringUtils.isEmpty(fallbackName)) {
//抛出原本的异常
return super.getFallback();
}
return new RpcResult("the dubbo fallback.");
}
}
最后注册、使用Filter
<dubbo:service interface="com.test.HelloService" ref="helloService" timeout="50000" filter="hystrixFilter">
<dubbo:method name="sayHello" retries="0" />
<dubbo:parameter key="ThreadPoolCoreSize" value="30" />
</dubbo:service>
Spring Boot上使用
1、首先加上maven依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
2、为application加上EnableHystrix注解:
@SpringBootApplication
@EnableHystrix
public class Application {}
3、最后分别为服务端和消费端配置:
// Provider端,增加@HystrixCommand配置,调用就会经过Hystrix代理
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") })
public String sayHello(){}
// Consumer端,可以在method上配置@HystrixCommand,当调用出错时增加一层method调用,走到fallbackMethod配置的调用里
@HystrixCommand(fallbackMethod = "reliable")
public String doSayHello(String name) {
return helloService.sayHello(name);
}
public String reliable(String name) {
return "hystrix fallback value";
}
3、如果是使用hystrix-core + hystrix-javanica,那么需要配置Aspect:
@Configuration
public class HystrixConfig {
@Bean
public HystrixCommandAspect hystrixCommandAspect() {
return new HystrixCommandAspect();
}
}
其他
hystrix-metrics-event-stream,是收集hystrix统计的接口信息,比如success、exception次数等。访问http://xxxx/hystrix.stream 返回信息就是metric结果
Hystrix-dashboard可以搭建监控平台
参考:
dubbo集成netflix原生的hystrix框架
如何在springboot中快速加入Hystrix
限流(current limiting)
Provider有时候也要防范来自Consumer的流量突变问题。比如一个核心服务为N个Consumer提供服务,突然某个Consumer抽风流量飙升,占用了Provider大部分机器时间,导致其他可能更重要的Consumer不能被正常服务。所以Provider端需要根据Consumer的重要程度,以及平时的QPS大小,来给每个Consumer设置一个流量上限,超过限制则等待或者直接拒绝
高并发下的限流,一般通过熔断策略,拒绝服务,排队处理,降级等方式,常用于秒杀等场景。在实际业务中,一般的业务服务器都部署在反向代理服务器(Ngnix)后面,一般情况下,Ngnix不会成为瓶颈,后端的应用服务器会由于各种原因(IO等待时间长、数据库慢、代码自身的缺陷等)成为瓶颈,所以主要是根据应用服务器的负载情况来计算一个阀值,如果超过这个值,则拒绝新的请求
限流的方式:
1、限制瞬间并发数:通过防刷算法,拒绝疑似攻击的请求。通过用户识别码、IP、所在区域、上网特征、黑名单等方式拒绝频繁访问的用户
2、限制总并发数:通过配置连接池、线程池大小来约束并发数
3、限制时间窗口的平均速率:在接口层面,通过限制访问速率来控制接口的并发请求
4、资源隔离:Provider对Consumer来的流量进行限流,防止provider被拖垮。同样Consumer也对调用Provider的线程资源进行隔离,确保某个Provider调用逻辑不会耗光整个Consumer的线程池资源
5、服务降级:当Consumer发现服务出现异常,比如经常超时、数据错误,可以采取一定的策略,降级Provider的逻辑,通常可以直接返回固定值。当provider端发现流量激增的时候,为了保护自身的稳定性也可以考虑降级服务,比如直接给Consumer返回固定数据,需要实时写入数据库的,先缓存到队列或内存里,异步写入数据库
常见限流算法:
1、漏桶(Leaky Bucket):用于控制从本节点发出请求的速率,可以控制应用服务器发送请求到其它应用服务器的速率,确保一下稳定的速率,用于控制回调的洪峰。算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率
2、令牌桶(Token Bucket):用于控制从外界发送到本节点的请求的速率,针对用户洪峰。与漏桶效果一样但方向相反的算法,随着时间流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token(和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了。新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务。令牌桶的另外一个好处是可以方便的改变速度, 一旦需要提高速率,则可以按需提高放入桶中的令牌的速率
3、计数器:最简单的一种,通过控制时间段内的请求次数,可以看成是滑动窗口的低精度实现
4、滑动窗口算法:用来改善吞吐量的技术,由于需要存储多份的计数器(每一个格子存一份),所以滑动窗口在实现上需要更多的存储空间
dubbo实现
一般在分布式系统中,限流和熔断是处理并发的两大利器,一般来说客户端熔断,服务端限流。dubbo提供了多个和请求相关的filter:TPSLimiterFilter、ActiveLimitFilter、ExecuteLimitFilter,三者的侧重点各有不同
TpsLimitFilter
dubbo中的限流通过TpsLimitFilter来实现,会在invoker执行实际业务逻辑前进行拦截,判断单位时间请求数是否超过上限,如果超过,抛出异常阻断调用。用于控制一段时间类中的请求数:
// PROVIDER服务端限制
@Activate(group = Constants.PROVIDER, value = Constants.TPS_LIMIT_RATE_KEY)
public class TpsLimitFilter implements Filter {
private final TPSLimiter tpsLimiter = new DefaultTPSLimiter();
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
if (!tpsLimiter.isAllowable(invoker.getUrl(), invocation)) {
throw new RpcException(
"Failed to invoke service " +
invoker.getInterface().getName() +
"." +
invocation.getMethodName() +
" because exceed max service tps.");
}
return invoker.invoke(invocation);
}
}
通过源码很明显看出,是通过TPSLimiter的isAllowable实现限流的。其内部采用了计数器算法,单位时间内限制多少调用次数,超过限制,返回false:
public class DefaultTPSLimiter implements TPSLimiter {
// TPSLimiter针对每个service都创建一个计数器StatItem,通过StatItem的isAllowable方法判断请求是否有效
private final ConcurrentMap<String, StatItem> stats
= new ConcurrentHashMap<String, StatItem>();
public boolean isAllowable(URL url, Invocation invocation) {
int rate = url.getParameter(Constants.TPS_LIMIT_RATE_KEY, -1);
long interval = url.getParameter(Constants.TPS_LIMIT_INTERVAL_KEY,
Constants.DEFAULT_TPS_LIMIT_INTERVAL);
// servicekey并没有和方法绑定,只能限流接口
String serviceKey = url.getServiceKey();
if (rate > 0) {
StatItem statItem = stats.get(serviceKey);
if (statItem == null) {
stats.putIfAbsent(serviceKey,
new StatItem(serviceKey, rate, interval));
statItem = stats.get(serviceKey);
}
return statItem.isAllowable();
} else {
StatItem statItem = stats.get(serviceKey);
if (statItem != null) {
stats.remove(serviceKey);
}
}
return true;
}
}
查看StatItem类的部分代码,逻辑很简单,针对每段时间允许rate次调用,只要计数器达不到上限就返回true,超过时间重置计数器:
class StatItem {
// 接口名
private String name;
// 计数周期开始
private long lastResetTime;
// 计数间隔 默认60s
private long interval;
// 剩余计数请求数
private AtomicInteger token;
// 总共允许请求数
private int rate;
public boolean isAllowable() {
long now = System.currentTimeMillis();
if (now > lastResetTime + interval) {
token.set(rate);
lastResetTime = now;
}
int value = token.get();
boolean flag = false;
while (value > 0 && !flag) {
// 乐观锁增加计数
flag = token.compareAndSet(value, value - 1);
value = token.get();
}
return flag;
}
}
TpsLimitFilter是一个扩展点自动激活配置,首先TpsLimitFilter只对Provider端有效,其次Provider的url需要包括tps=xxx这个配置才能生效。而且Dubbo框架并没有默认通过配置文件启动这个Filter,所以我们需要在classpath的META-INF/dubbo/目录下增加com.alibaba.dubbo.rpc.Filter文件:
tps=com.alibaba.dubbo.rpc.filter.TpsLimitFilter
前面说过,需要在url上配置tps参数才可以生效,如同降级一样,通过override动态配置覆盖规则,可以在代码中完成,也可以在监控中心或治理中心页面完成,因为在RegistryProtocol使用export方法对服务进行本地暴露以及注册Provider Url到zk后,还做了另外一个操作,监听服务对应的/dubbo/interface/configurations目录,一旦configurations目录下节点发生变化,就会重新生成暴露的url,然后进行reexport:
// 得到override url,用于监听configurations目录
final URL overrideSubscribeUrl = getSubscribedOverrideUrl(registedProviderUrl);
// 构造监听器,用于provider url被override时,重新发布exporter
// 监听路径为:/dubbo/interface/configurations
final OverrideListener overrideSubscribeListener = new OverrideListener(overrideSubscribeUrl, originInvoker);
overrideListeners.put(overrideSubscribeUrl, overrideSubscribeListener);
// 向registry订阅这个url路径
registry.subscribe(overrideSubscribeUrl, overrideSubscribeListener);
比如最简单的:override://127.0.0.1:20880/com.test.TestService?category=configurators&tps=5&tps.interval=5000
ActiveLimitFilter
dubbo中使用ActiveLimitFilter控制客户端同样的方法可同时并发请求数量,即该方法的并发度:
// CONSUMER客户端限制
@Activate(group = Constants.CONSUMER, value = Constants.ACTIVES_KEY)
public class ActiveLimitFilter implements Filter {
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
String methodName = invocation.getMethodName();
// 获取设置的acvites的值,默认为0
int max = invoker.getUrl().getMethodParameter(methodName, Constants.ACTIVES_KEY, 0);
// 获取当前方法目前并发请求数量
RpcStatus count = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
if (max > 0) {
// 等待结束依赖于timeout,需要搭配一起使用
long timeout = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.TIMEOUT_KEY, 0);
long start = System.currentTimeMillis();
long remain = timeout;
int active = count.getActive();
// 超过了指定的active值之后该请求将等待前面的请求完成
if (active >= max) {
synchronized (count) {
while ((active = count.getActive()) >= max) {
try {
count.wait(remain);
} catch (InterruptedException e) {
}
long elapsed = System.currentTimeMillis() - start;
remain = timeout - elapsed;
// 如果等待时间超时,则抛出异常
if (remain <= 0) {
throw new RpcException("Waiting concurrent invoke timeout in client-side for service: "
+ invoker.getInterface().getName() + ", method: "
+ invocation.getMethodName() + ", elapsed: " + elapsed
+ ", timeout: " + timeout + ". concurrent invokes: " + active
+ ". max concurrent invoke limit: " + max);
}
}
}
}
}
// 没有限流正常调用
try {
long begin = System.currentTimeMillis();
RpcStatus.beginCount(url, methodName);
try {
Result result = invoker.invoke(invocation);
RpcStatus.endCount(url, methodName, System.currentTimeMillis() - begin, true);
return result;
} catch (RuntimeException t) {
RpcStatus.endCount(url, methodName, System.currentTimeMillis() - begin, false);
throw t;
}
} finally {
if (max > 0) {
synchronized (count) {
count.notify();
}
}
}
}
}
消费端并发控制配置(接口/方法):<dubbo:service interface="com.foo.BarService" actives="10" />表示限制com.foo.BarService的每个方法,每客户端并发执行(或占用连接的请求数)不能超过10个
ExecuteLimitFilter
控制在单台服务上的并行度,单个方法的并发处理个数,与客户端控制区别是超过数量不会等待,而是直接抛出异常:
// PROVIDER服务端限制
@Activate(group = Constants.PROVIDER, value = Constants.EXECUTES_KEY)
public class ExecuteLimitFilter implements Filter {
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
String methodName = invocation.getMethodName();
Semaphore executesLimit = null;
boolean acquireResult = false;
//获取executes值,默认为0
int max = url.getMethodParameter(methodName, Constants.EXECUTES_KEY, 0);
if (max > 0) {
RpcStatus count = RpcStatus.getStatus(url, invocation.getMethodName());
// if (count.getActive() >= max) {
/**
* http://manzhizhen.iteye.com/blog/2386408
* use semaphore for concurrency control (to limit thread number)
*/
// 计数信号量设为max
executesLimit = count.getSemaphore(max);
// 如果并发处理数量大于设置的值,抛出异常
if(executesLimit != null && !(acquireResult = executesLimit.tryAcquire())) {
throw new RpcException("Failed to invoke method " + invocation.getMethodName() + " in provider " + url + ", cause: The service using threads greater than <dubbo:service executes=\"" + max + "\" /> limited.");
}
}
long begin = System.currentTimeMillis();
boolean isSuccess = true;
RpcStatus.beginCount(url, methodName);
try {
Result result = invoker.invoke(invocation);
return result;
} catch (Throwable t) {
isSuccess = false;
if (t instanceof RuntimeException) {
throw (RuntimeException) t;
} else {
throw new RpcException("unexpected exception when ExecuteLimitFilter", t);
}
} finally {
RpcStatus.endCount(url, methodName, System.currentTimeMillis() - begin, isSuccess);
if(acquireResult) {
executesLimit.release();
}
}
}
}
服务端并发控制配置(接口/方法):<dubbo:service interface="com.foo.BarService" executes="10" />表示限制com.foo.BarService的每个方法,服务器端并发执行(或占用线程池线程数)不能超过10个
连接控制
限制服务器端接受的连接不能超过10个:
<dubbo:provider protocol="dubbo" accepts="10" />
或
<dubbo:protocol name="dubbo" accepts="10" />
限制客户端服务使用连接不能超过10个:
<dubbo:reference interface="com.foo.BarService" connections="10" />
优先于
<dubbo:service interface="com.foo.BarService" connections="10" />
Sentinel
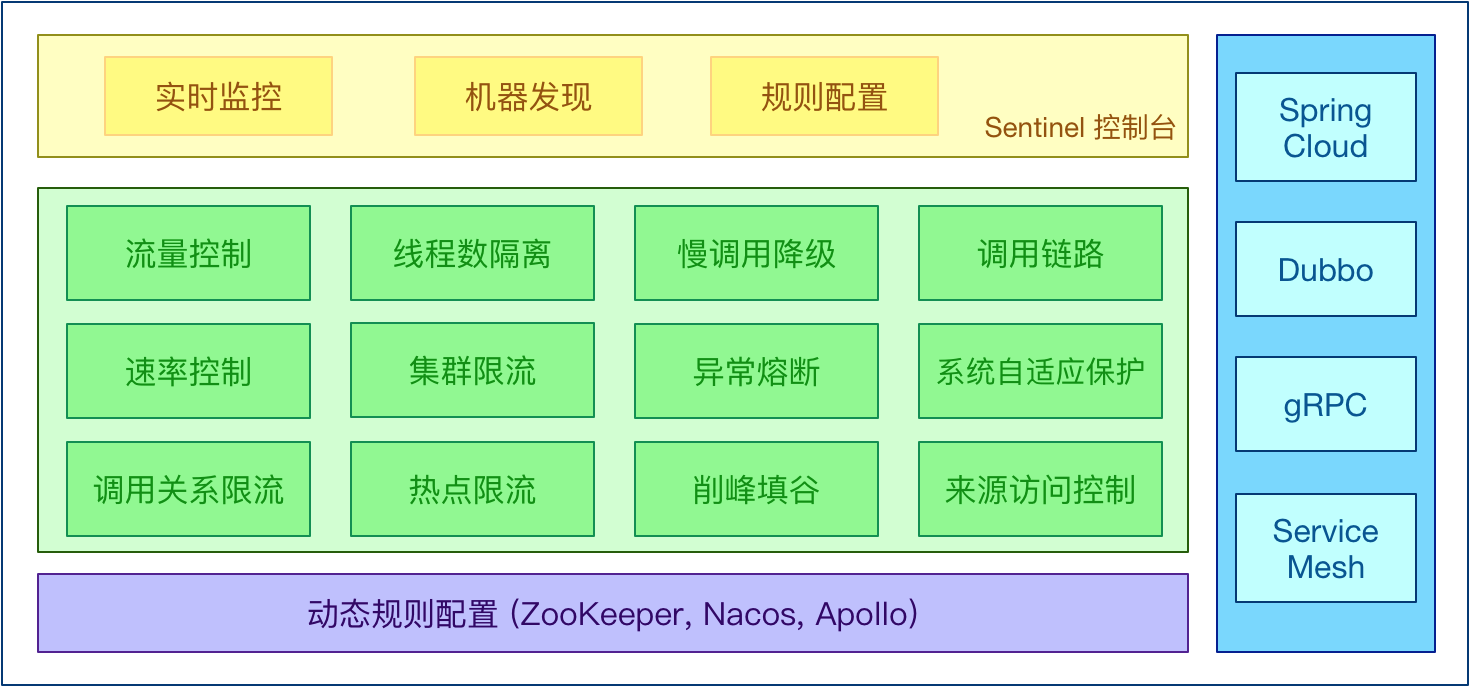 Sentinel正如它英文的意思“哨兵”一样,为整个服务化体系的稳定运行行使着警戒任务,是对资源调用的控制平台,主要涵盖了授权、限流、降级、调用统计监控四大功能:
Sentinel正如它英文的意思“哨兵”一样,为整个服务化体系的稳定运行行使着警戒任务,是对资源调用的控制平台,主要涵盖了授权、限流、降级、调用统计监控四大功能:
1、授权:通过配置白名单和黑名单的方式分布式系统的接口和方法进行调用权限的控制
2、限流:对特定资源进行调用的保护,防止资源的过度使用
3、降级:判断依赖的资源的响应情况,但依赖的资源响应时间过长时进行自动降级,并且在指定的时间后自动恢复调用
4、监控:提供了全面的运行状态监控,实时监控资源的调用情况,如QPS、响应时间、限流降级等信息
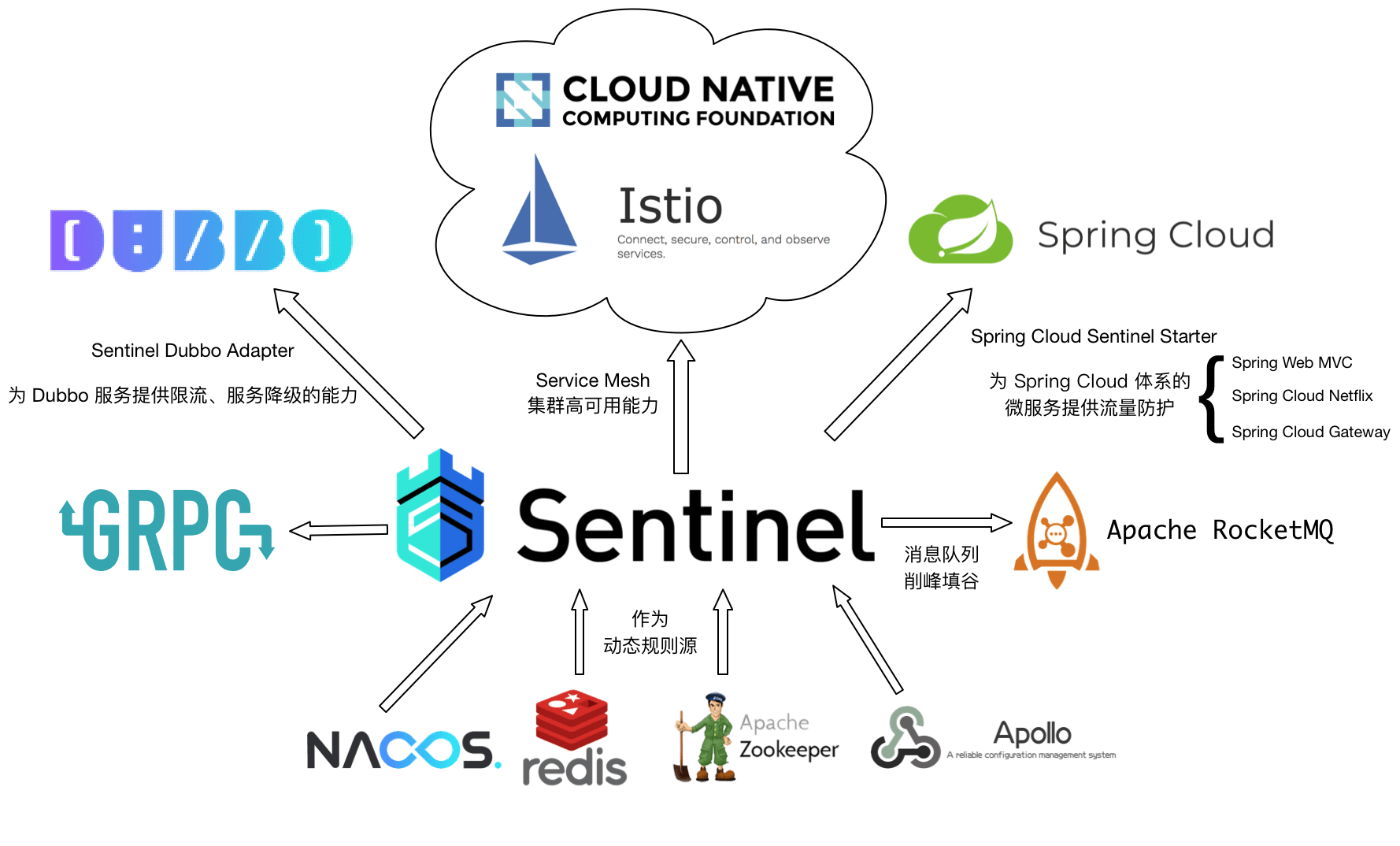
Sentinel 的开源生态:
 Sentinel分为两个部分:
Sentinel分为两个部分:
1、核心库(Java客户端)不依赖任何框架/库,能够运行于所有Java运行时环境,同时对Dubbo / Spring Cloud等框架也有较好的支持
2、控制台(Dashboard)基于Spring Boot开发,打包后可以直接运行,不需要额外的Tomcat等应用容器
Sentinel平台有两个基础概念,资源和策略,对特定的资源采取不同的控制策略,起到保障应用稳定性的作用。Sentinel 提供了多个默认切入点,比如服务调用时,数据库、缓存等资源访问时,覆盖了大部分应用场景,保证对应用的低侵入性,同时也支持硬编码或者自定义AOP的方式来支持特定的使用需求
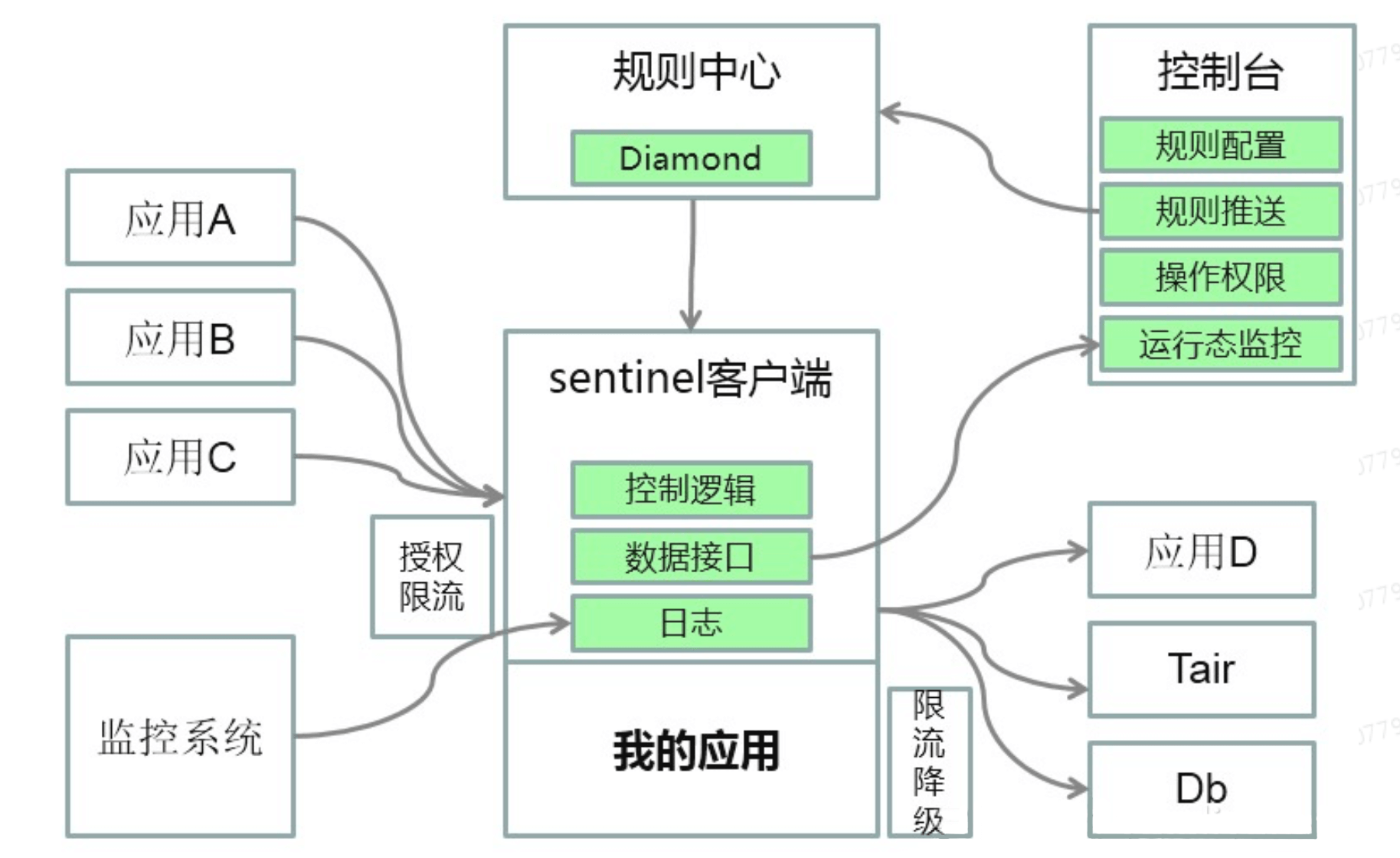 Sentinel平台架构如图,需要通过Sentinel实现限流功能的应用中都嵌入Sentinel客户端,通过Sentinel客户端中提供对服务调用和各资源访问缺省实现的切入点,使得应用完全不需要对实现限流的服务或资源进行单独的AOP配置和实现,同时不仅可以限制自己的应用调用别的应用,也可以限制别的应用调用我的应用。通过这些资源埋点实时计算当前服务的QPS,也可通过现有的监控系统获取到应用所在服务器的相关系统监控指标,用于限流规则配置中的阀值比对
Sentinel平台架构如图,需要通过Sentinel实现限流功能的应用中都嵌入Sentinel客户端,通过Sentinel客户端中提供对服务调用和各资源访问缺省实现的切入点,使得应用完全不需要对实现限流的服务或资源进行单独的AOP配置和实现,同时不仅可以限制自己的应用调用别的应用,也可以限制别的应用调用我的应用。通过这些资源埋点实时计算当前服务的QPS,也可通过现有的监控系统获取到应用所在服务器的相关系统监控指标,用于限流规则配置中的阀值比对
Quick Start
1、首先加入maven依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.4.1</version>
</dependency>
2、定义资源,使用API:SphU.entry(“resourceName”) and entry.exit()将需要控制流量的代码包围起来
// initFlowRules();
while (true) {
Entry entry = null;
try {
entry = SphU.entry("HelloWorld");
/*您的业务逻辑 - 开始*/
System.out.println("hello world");
/*您的业务逻辑 - 结束*/
} catch (BlockException e1) {
/*流控逻辑处理 - 开始*/
System.out.println("block!");
// sleep();
/*流控逻辑处理 - 结束*/
} finally {
if (entry != null) {
entry.exit();
}
}
}
3、通过规则来指定允许该资源通过的请求次数,例如下面的代码定义了资源 HelloWorld 每秒最多只能通过20个请求:
private void initFlowRules() {
List<FlowRule> rules = new ArrayList<FlowRule>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
运行后可以发现每秒稳定最多输出20条hello world
注解支持
从0.1.1版本开始,Sentinel提供了@SentinelResource注解用于定义资源,并提供了AspectJ的扩展用于自动定义资源、处理BlockException等。使用Sentinel Annotation AspectJ Extension的时候需要引入以下依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-annotation-aspectj</artifactId>
<version>1.4.1</version>
</dependency>
配置,如果直接使用了 AspectJ,需要在aop.xml文件中引入对应的Aspect:
<aspects>
<aspect name="com.alibaba.csp.sentinel.annotation.aspectj.SentinelResourceAspect"/>
</aspects>
一般会使用Spring AOP,所以需要通过配置的方式将SentinelResourceAspect注册为一个Spring Bean:
@Configuration
public class SentinelAspectConfiguration {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}
@SentinelResource用于定义资源,并提供可选的异常处理和fallback配置项,其中:
1、value: 资源名称,必需项(不能为空)
2、entryType: 入口类型,可选项(默认为EntryType.OUT)
3、blockHandler/blockHandlerClass: blockHandler对应处理BlockException的函数名称,可选项。若未配置,则将BlockException直接抛出。blockHandler函数访问范围需要是public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为BlockException。blockHandler函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定blockHandlerClass为对应的类的Class对象,注意对应的函数必需为static函数,否则无法解析
4、fallback: fallback函数名称,可选项,仅针对降级功能生效(DegradeException)。fallback函数的访问范围需要是public,参数类型和返回类型都需要与原方法相匹配,并且需要和原方法在同一个类中。业务异常不会进入fallback逻辑
注意:若blockHandler和fallback都进行了配置,则遇到降级的时候首先选择fallback函数进行处理。并且blockHandler是处理被block的情况(所有类型的BlockException),而fallback仅处理被降级的情况(DegradeException)。其它异常会原样抛出,Sentinel不会进行处理
比如:
// 原函数
@SentinelResource(value = "hello", blockHandler = "exceptionHandler", fallback = "helloFallback")
public String hello(long s) {
return String.format("Hello at %d", s);
}
// Block异常处理函数,参数最后多一个BlockException,其余与原函数一致
public String exceptionHandler(long s, BlockException ex) {
// Do some log here.
return "Oops, error occurred at " + s;
}
// Fallback函数,函数签名与原函数一致
public String helloFallback(long s) {
return String.format("Halooooo %d", s);
}
// 对应的handleException函数需要位于ExceptionUtil类中,并且必须为static函数
@SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil`.class})
public void test() {
System.out.println("Test");
}
注意:从1.4.0版本开始,注解方式定义资源支持自动统计业务异常,无需手动调用Tracer.trace(ex)来记录业务异常。Sentinel 1.4.0以前的版本需要自行调用Tracer.trace(ex)来记录业务异常
接入dubbo
Sentinel提供Dubbo的相关适配Sentinel Dubbo Adapter,主要包括针对Service Provider和Service Consumer实现的Filter。使用时需引入以下模块:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-dubbo-adapter</artifactId>
<version>1.4.1</version>
</dependency>
引入此依赖后,Dubbo的服务接口和方法(包括调用端和服务端)就会成为Sentinel中的资源,在配置了规则后就可以自动享受到Sentinel的防护能力。若不希望开启Sentinel Dubbo Adapter中的某个Filter,可以手动关闭对应的Filter,比如:
<!-- 关闭 Sentinel 对应的 Service Consumer Filter -->
<dubbo:consumer filter="-sentinel.dubbo.consumer.filter"/>
或者
@Bean
public ConsumerConfig consumerConfig() {
ConsumerConfig consumerConfig = new ConsumerConfig();
consumerConfig.setFilter("-sentinel.dubbo.consumer.filter");
return consumerConfig;
}
限流粒度可以是服务接口和服务方法两种粒度:
服务接口:resourceName为接口全限定名,如:
com.alibaba.csp.sentinel.demo.dubbo.FooService
服务方法:resourceName为接口全限定名:方法签名,如:
com.alibaba.csp.sentinel.demo.dubbo.FooService:sayHello(java.lang.String)
Sentinel Dubbo Adapter还支持配置全局的fallback函数,可以在Dubbo服务被限流/降级/负载保护的时候进行相应的fallback处理。用户只需要实现自定义的DubboFallback 接口,并通过DubboFallbackRegistry注册即可。默认情况会直接将BlockException包装后抛出。同时,我们还可以配合Dubbo的fallback机制(本地伪装)来为降级的服务提供替代的实现
扩展:
官方:Sentinel 为 Dubbo 服务保驾护航
官方:sentinel-demo-dubbo示例
Service Provider
对服务提供方的限流可分为服务提供方的自我保护能力和服务提供方对服务消费方的请求分配能力这两个维度
服务提供方用于向外界提供服务,处理各个消费方的调用请求。为了保护提供方不被激增的流量拖垮影响稳定性,可以给提供方配置QPS模式的限流,这样当每秒的请求量超过设定的阈值时会自动拒绝阈值外的请求。若希望整个服务接口的QPS不超过一定数值,则可以为对应服务接口资源(resourceName为接口全限定名)配置QPS阈值;若希望对某个服务函数的QPS不超过一定数值,则可以为对这个服务函数资源(resourceName为接口全限定名:方法签名)配置QPS阈值
官方:流量控制
根据调用方的需求来分配服务提供方的处理能力也是常见的限流方式。比如有两个服务A和B都向Service Provider发起调用请求,我们希望只对来自服务B的请求进行限流,则可以设置限流规则的limitApp为服务B的名称。Sentinel Dubbo Adapter会自动解析Dubbo消费方(调用方)的application name作为调用方名称(origin),在进行资源保护的时候都会带上调用方名称。若限流规则未配置调用方(default),则该限流规则对所有调用方生效。若限流规则配置了调用方则限流规则将仅对指定调用方生效
注:Dubbo 默认通信不携带对端 application name 信息,因此需要开发者在调用端手动将 application name 置入 attachment 中,provider 端进行相应的解析。Sentinel Dubbo Adapter 实现了一个 Filter 用于自动从 consumer 端向 provider 端透传 application name。若调用端未引入 Sentinel Dubbo Adapter,又希望根据调用端限流,可以在调用端手动将 application name 置入 attachment 中,key 为 dubboApplication
Service Consumer
对服务提供方的限流可分为对控制并发线程数,和服务降级两个维度
服务消费方作为客户端去调用远程服务。每一个服务都可能会依赖几个下游服务,若某个服务A依赖的下游服务B出现了不稳定的情况,服务A请求服务B的响应时间变长,从而服务A调服务B的线程就会产生堆积,最终可能耗尽服务A的线程数。我们通过用并发线程数来控制对下游服务B的访问,来保证下游服务不可靠的时候,不会拖垮服务自身。采用基于线程数的限制模式后,我们不需要再去对线程池进行隔离,Sentinel会控制资源的线程数,超出的请求直接拒绝,直到堆积的线程处理完成。限流粒度同样可以是服务接口和服务方法两种粒度
动态规则数据源
Sentinel的动态规则数据源用于从中读取及写入规则。从0.2.0版本开始,Sentinel将动态规则数据源分为两种类型:
1、读数据源(ReadableDataSource):仅负责监听或轮询读取远程存储的变更
2、写数据源(WritableDataSource):仅负责将规则变更写入到规则源中
其中读数据源常见的实现方式有:
1、Pull模式:客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是RDBMS、文件等。这样做的方式是简单,缺点是可能无法及时获取变更,拉取过于频繁也可能会有性能问题
2、Push模式:规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用Nacos、Zookeeper等配置中心。这种方式有更好的实时性和一致性保证
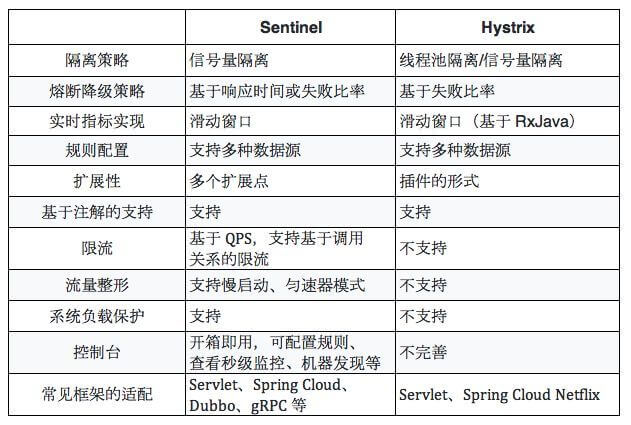
对比Hystrix
其他:Resilience4J,原生支持Spring Boot 1.x/2.x,支持和Micrometer(Pivotal开源的监控门面,Spring Boot 2.x中的Actuator就是基于Micrometer的)、prometheus(开源监控系统,来自谷歌的论文)、以及Dropwizard metrics(Spring Boot曾经的模仿对象,类似于Spring Boot)进行整合