Java基础: JVM(一) JVM概述与字节码
Java基础: JVM(二) 常量池
Java基础: JVM(三) JVM执行引擎01
Java基础: JVM(四) Java栈帧
Java基础: JVM(五) JVM执行引擎02
Java基础: JVM(六) 类变量和类方法解析
Java基础: JVM(七) 类生命周期与类加载器
Java基础: JVM(八) 热加载
Java基础: JVM(九) Java内存模型
Java基础: JVM(十) 编译相关
Java栈帧
Java方法的调用链路,就是由一个个Java方法的栈帧所组成的,每一个Java方法都有一个栈帧,比如你方法打断点看到的就是栈的调用层级,这个上一篇讲过,在这点上和C/C++程序并无区别。回顾一下,上一篇中讲了CallStub例程的实现机制,在JVM内部,例程就是一个功能性函数。站在宏观的角度上,它是一种预先设定好的逻辑,从程序实现角度看,它既可以用C语言实现也可以用其他编程语言实现,entry_point例程与CallStub例程一样,都是用C编写最终生成一段对应汇编的逻辑。在JVM调用Java程序的main()主函数,会经过CallStub例程,在该例程中仅仅完成了Java主函数的参数传递,并没有开始执行Java程序中的main()主函数的字节码指令,这是因为JVM在准备执行一个java方法的字节码指令之前,必须为该方法分配好对应的方法堆栈。而后在CallStub例程里调用entry_point例程,完成主函数的栈帧创建,找到Java主函数所对应的第一个字节码指令并进入执行
JVM内部可以调用各种不同的方法类型,比如JNI本地函数、Java静态方法、Java类的成员方法。调用不同类型的方法,会触发不同的entry_point例程,所谓entry_point即”进入点”,进入目标方法。正因为JVM在调用目标方法之前会进经过entry_point,并且JVM在执行目标方法的指令之前,需要先为其创建好相对应的方法堆栈,因此JVM选择在entry_point例程中完成方法堆栈创建
entry_point例程生成
与CallStub例程一样,entry_point例程也是在JVM启动过程中被创建,而且实际上JVM内部的所有例程都随着JVM启动而创建
java.c: main()
java_md.c: LoadJavaVM()
jni.c: JNI_CreateJavaVM()
Threads.c: create_vm()
init.c: init_globals()
interpreter.cpp: interpreter_init()
templateInterpreter.cpp: initialize()
templateInterpreter_x86_x32.cpp: InterpreterGenerator()
templateInterpreter.cpp: generate_all()
与CallStub一样,链路起步与JVM的main()函数,到init_globals()这个全局数据初始化模块后,与CallStub分道扬镳,在initialize()中:
void TemplateInterpreter::interpreter_init() {
// ...
{
ResourceMark rm;
TraceTime timer("Interpreter generation", TraceStartupTime);
int code_size = InterpreterCodeSize;
NOT_PRODUCT(code_size*=4);
_code = new StubQueue(new InterpreterCodeletInterface, code_size, NULL, "Interpreter");
// 创建解释器生成器的实例
InterpreterGenerator g(_code);
if (PrintInterpreter) print();
}
// ...
}
在Hotspot内部存在3种解释器,分别是字节码解释器、C++解释器、模板解释器。其中字节码解释器逐条解释执行字节码指令,由于使用C/C++这种高级语言执行字节码指令逻辑,因此执行效率比较低下;模板解释器相比于字节码解释器,它将字节码指令直接翻译成了对应的机器指令,这种直接生成的指令比C/C++代码编译后的机器指令,更加高效,因此JVM默认解释器就是模板解释器;对于C++解释器和模板解释器而言,都有一个对应的”解释器生成器”,模板解释器对应的生成器是TemplateInterpreterGenerator,在上面那个方法中就对其进行了实例化:
InterpreterGenerator::InterpreterGenerator(StubQueue* code)
: TemplateInterpreterGenerator(code) {
// 产生一款编译器运行时需要的各种例程与入口
generate_all(); // down here so it can be "virtual"
}
// /src/share/vm/interpreter/templateInterpreter.cpp
// 生成模板解释器所对应的各种模板例程的机器指令,并保存入口地址
void TemplateInterpreterGenerator::generate_all() {
// ...
// 下面定义了一些重要的逻辑入口
{
// 定义了return指令入口,同时会生成其对应的机器指令
CodeletMark cm(_masm, "return entry points");
for (int i = 0; i < Interpreter::number_of_return_entries; i++) {
Interpreter::_return_entry[i] = EntryPoint(
generate_return_entry_for(itos, i),
// ...
generate_return_entry_for(vots, i)
);
}
}
{CodeletMark cm(_masm, "earlyret entry points"); // ...}
{CodeletMark cm(_masm, "deoptimization entry points"); // ...}
{CodeletMark cm(_masm, "result handlers for native calls"); // ...}
// ...
// 从宏定义开始,定义了一系列方法入口,比如zerolocals、abstract、java_lang_math_sin等
// 在AbstractInterpreter中定义了JVM所支持的所有方法入口,当JVM调用Java函数时,例如构造方法、类成员方法、静态方法、虚方法等
// 或特定的数学函数,最终就会从不同的入口进去,在CallStub例程中进入不同的函数入口
#define method_entry(kind)
{
CodeletMark cm(_masm, "method entry point(kind = "#kind")");
Interpreter::_entry_table[Interpreter::kind] = generate_method_entry(Interpreter::kind);
}
// all non-native method kinds
// 对于正常的Java方法调用(包括Java程序主函数),其对应的entry_point一般都是zerolocals或zerolocals_synchronized
method_entry(zerolocals)
method_entry(zerolocals_synchronized)
method_entry(empty)
method_entry(accessor)
// ...
}
这里来看zerolocals方法入口,method_entry()这正是前面定义的宏,调用method_entry(zerolocals)就相当于调用了Interpreter::_entry_table[Interpreter::zerolocals] = generate_method_entry(Interpreter::zerolocals);,这个逻辑执行完后,JVM会为zerolocals生成本地机器指令,同时将这串机器指令的首地址保存到Interpreter::_entry_table数组中。为zerolocals方法入口生成机器指令的generate_method_entry()函数会switch(kind)判断入参的枚举类型,对于zerolocals不做任何处理直接跳出,执行return ((InterpreterGenerator*)this)->generate_normal_entry(synchronized),在generate_normal_entry()函数中要为zerolocals生成本地机器指令了,比如在32位X64 Linux平台上可以看templateInterpreter_x86_32.cpp文件。generate_normal_entry()函数在JVM启动过程中调用,执行完成后会向JVM的代码缓存区写入对应的本地机器指令。当JVM调用一个特定的Java方法时,会根据Java方法所对应的entry_point类型找到对应的函数入口,并执行这段预先生成好的机器指令
generate_normal_entry()函数主要逻辑大致可以分为9步:
1、定义寄存器变量
2、获取Java方法入参数量、max_locals、局部变量slot数量
3、获取返回地址
4、计算Java方法第一个入参在堆栈中的地址
5、为局部变量slot分配堆栈空间,初始化为0
6、创建栈帧
7、引用计数
8、开始执行Java方法第一条字节码
9、进入Java方法第一条字节码
CallStub例程所进入的entry_point其实就是方法入口,并且这个方法入口并不是只有一个,而是由一批,至于会进入哪一个入口其实在编译期就确定了,编译器会判断Java方法的签名(方法名、访问标识、是否synchronized、是否虚方法等),并根据Java方法的签名信息生成不同的方法调用指令。在一个Java类被JVM加载的过程中,同样会对每个Java方法进行签名信息分析,并最终确定一个Java方法的entry_point类型
局部变量表创建
constMethod内存布局
JVM充分基于数据结构展开其独特的算法,无论对象的位置或诞生消亡、算法怎么变化,对象所代表的数据结构是不会变化的,是一串结构中各个元素相对偏移。Java函数在JVM内部所对应的method也是如此。在entry_point()例程中,这种数据结构用来定位Java函数所对应的字节码位置,并计算局部变量表的容量
在JDK6中,JVM内部通过偏移量来为Java函数定下规则,至少需要以下3条规则:
1、method(方法在JVM的对等数据结构)对象的constMethod指针紧跟在methodOop对象头的后面,即constMethod的偏移量是固定的
2、constMethod内部存储Java函数所对应的字节码指令的位置相对于constMethod起始位的偏移是固定的
3、method对象内部存储Java函数的参数数量、局部变量数量的参数的偏移量是固定的
constMethod相对于methodOop起始位置偏移量是一个oopDesc对象头的距离,在32位X86平台上距离为8,即2个指针的宽度。而且Java函数中两个非常重要的属性:max_locals和size_of_parameters在JDK6中都被保存在methodOopDesc对象中,它们的对methodOop对象首地址的偏移量分别是36和38
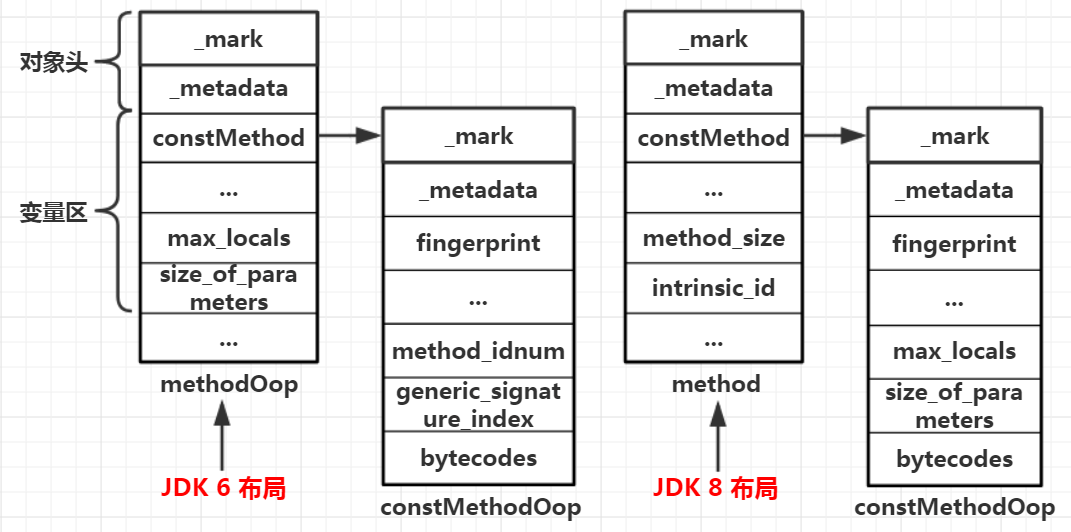 在JDK8中,研发人员可能认为对于一个给定的Java函数,其max_locals和size_of_parameters是不可能在运行过程中被修改的,因此应该将其当做只读属性,于是这两个属性从methodOopDesc对象中移动到了constMethod对象中,因为constMethod对象中的属性都是只读的。在JDK8中的两个对象名称后面的Oop都没有了,但是数据结构并没太大变化。所以在JDK8中想要读取这两个属性,就不能基于method的偏移量去读取了,只能基于constMethod的偏移量去读取,在32位X86平台上的偏移量分别为32和34
在JDK8中,研发人员可能认为对于一个给定的Java函数,其max_locals和size_of_parameters是不可能在运行过程中被修改的,因此应该将其当做只读属性,于是这两个属性从methodOopDesc对象中移动到了constMethod对象中,因为constMethod对象中的属性都是只读的。在JDK8中的两个对象名称后面的Oop都没有了,但是数据结构并没太大变化。所以在JDK8中想要读取这两个属性,就不能基于method的偏移量去读取了,只能基于constMethod的偏移量去读取,在32位X86平台上的偏移量分别为32和34
局部变量表空间计算
局部变量表作为Java方法堆栈(栈帧)的一部分,主要的作用就是保存Java方法内部所声明的局部变量和入参。成功为Java函数分配局部变量表的第一步就是正确计算出Java函数局部变量表所需的大小。局部变量表包含所有入参和方法内部声明的全部局部变量,其大小在编译阶段就被编译器准确计算出来,为max_locals的值。然而在运行期,通常Java方法的入参堆栈空间是由调用方所分配的,因此被调用方并不需要再分配编译器计算出来的全部局部变量空间,对于Java方法之间的调用(非本地方法调用Java方法),调用方的操作数栈与被调用方的局部变量表往往存在重叠区,这给Java局部变量表的分配带来了挑战。所以在运行期JVM只需要为Java方法的局部变量分配堆栈空间,而不需要为入参额外分配空间,因为入参的堆栈空间由调用方完成分配,这根本原因是编译期间所获得的信息与运行期间所获得的信息是不对称的,而且运行期间可能会有各种优化
// 例如:
public void add(int x, int y) {
int z = x + y;
}
// 使用javap -verbose分析:
public void add(int, int);
descriptor: (II)V
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=3
0: iload_1
1: iload_2
2: iadd
3: istore_3
4: return
add()方法局部变量表最大容量locals为4,入参数量args_size为3,这是因为add()方法是类的成员方法(非static),因此有隐藏的入参this。在执行z = x + y时,先将局部变量表的第1个槽位和第2个槽位的数据(槽位起始位0,存放的是this指针)推送至表达式的栈顶,这正是入参x和y,显然JVM内部的局部变量表包含了入参,执行完表达式后将结果保存到第3个槽位,正是内部定义的局部变量z,因此在运行期x和y这两个入参在调用方调用add()方法时就已经分配完毕,因此只需要为z分配堆栈空间大小,为编译期间计算的局部变量表大小减去入参数量,即4-3=1,JVM只需要为add()函数分配1个变量槽。在entry_point例程中正是这么去减的得到除入参以外所需分配的堆栈空间大小
最终生成的机器指令为:
// JDK 6 ebx寄存器指向method对象首地址
movzwl 0x26(%ebx), %ecx
movzwl 0x24(%ebx), %edx
sub %ecx, %edx
// JDK 8 这2个值从method移到了constMethod对象中,因此需要先将edx寄存器constMethod对象首地址
mov 0x8(%ebx), %edx
movzwl 0x22(%ebx), %ecx
movzwl 0x20(%ebx), %edx
sub %ecx, %edx
初始化局部变量表
对于绝大部分C/C++语言等可以直接编译为本地二进制机器语言指令的语言,分配堆栈空间基本使用sub oprand, %esp指令,esp寄存器指向调用者函数栈顶,要扩展堆栈内存空间只要往下移动就可以了,对操作系统而言会有一个最大堆栈深度的限制(JVM也有这种限制,使用-Xss控制)。而在entry_point例程中,分配堆栈使用了另一种方式,就是进行push操作:
address InterpreterGenerator::generate_normal_entry(bool synchronized) {
// ...
// get return address
__ pop(rax);
// compute beginning of parameters (rdi)
__ lea(rdi, Address(rsp, rcx, Interpreter::stackElementScale(), -wordSize));
// rax - # of additional locals
// allocate space for locals
// explicitly initialize locals
{
Label exit, loop;
// test %edx, %edx 测试edx是否为0,即判断Java函数中是否有局部变量
__ test1(rdx, rdx);
// jle 0x01ccbb08 如果Java函数内部没有声明局部变量,跳过堆栈空间分配
__ jcc(Assembler::leasEqual, exit); // do nothing if red <= 0
__ bing(loop);
// push $0x0 // 0xb36d6559
__ push((int32_t)NULL_WORD)); // initialize local variables
// dec %edx
__ decrement(rdx); // until everything initialized
// jg 0xb36d6559
__ jcc(Assembler::generate, loop);
__ bind(exit);
}
// ...
}
主要做了3件事情:
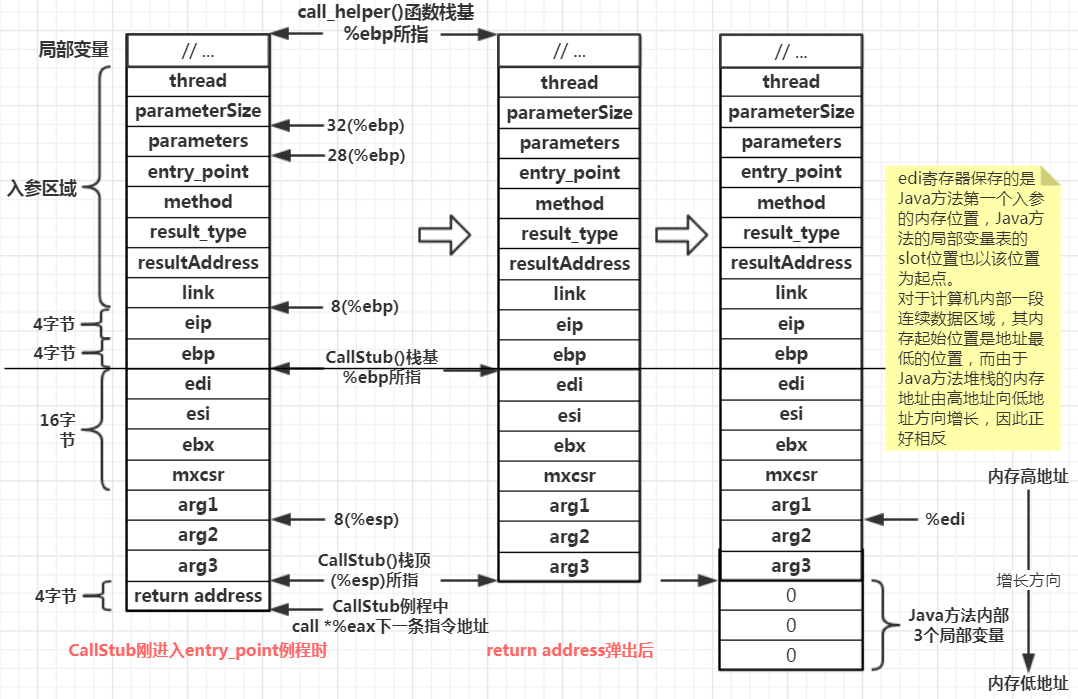
1、将栈顶的返回地址暂存到rax寄存器中:
CallStub例程中call *%eax这条指令所在内存区域的下一条指令地址,这个值实际是原本CallStub例程中eip寄存器的值。在JVM为被调用函数为局部变量分配空间前,先将”return address”保存到rax寄存器中。这是因为操作数栈被同时用作了入参的堆栈,而入参同时又是被调用方的局部变量表的一部分,因此就必然要将其内存空间连成一片,那么调用方的操作数栈其实同时也是被调用方的入参堆栈,因此入参堆栈与即将分配的局部变量的堆栈之间不允许存在一个碍事的return address参数,因此JVM便先将这个参数移走
2、获取Java函数第一个入参在堆栈中的位置:
在return address移走后,JVM栈顶就变为了argument word n,即最后一个入参。然后JVM通过lea -0x4(%esp, %ecx, 4), %edi,即展开后的(%edi) = ((%esp) + (%ecx入参数量) * 4) - 0x4,前部分计算出第一个入参的最高位置,由于大部分主流CPU是将一个数据的最低内存地址标记为该数据地址,因此还需要减去一个指针类型数据宽度(32位减4,64位减8),然后将第一个参数的堆栈坐标写入edi寄存器。之后JVM进行分配堆栈空间、执行Java字节码指令都需要涉及操作数栈和局部变量表之间相互传送数据,而JVM读取/写入局部变量表都需要知道局部变量表的起始位置,后续指令都要用到edi寄存器,这也正是对局部变量表的写入和读取都基于索引的原因,即JVM基于索引做偏移
3、为局部变量表分配堆栈空间:
如果(max_locals) - (size_of_parameters)不等于0,那么执行一个循环,先通过push $0x0往栈顶压入一个0,接着通过dec将edx寄存器的值减去1,判断edx如果不为0则跳转回push,否则循环结束。在entry_point例程中使用这种方式分配堆栈空间,而不使用sub operand, %esp这种方式,是因为对于同一块内存区域会重复利用,而Java方法执行完毕后并不负责清理堆栈,因此清零的工作只能由下一次使用这块堆栈空间的Java方法去负责,现在使用循环push 0的方式进行分配,一边分配一边清零,而不需要分配堆栈后再循环进行清零
堆栈与栈帧
在JVM位局部变量分配完堆栈空间后,就是要构建栈帧,准确的说是构建Java方法所对应的栈帧中的固定部分。这个固定部分在JVM内部称为fixed frame。fixed frame不是指固定的栈帧,而是指栈帧中固定的部分。众所周知在JVM内部,每个Java方法都对应一个栈帧,里面包含局部变量表、操作数栈、常量池缓冲指针、返回地址等数据,其实对于一个Java方法的栈帧,其首尾分别是局部变量表和操作数栈,中间则是除此之外其他重要信息,首尾部分数据在不同的Java方法是不同的,而中间部分的数据结构是固定不变的,这部分就是所谓的fixed frame,也可以称为“固定栈”数据
一个方法的栈帧就是这个方法的所对应的堆栈,一个方法内部会有许多变量,这些变量最终要在内存中占据内存空间,将它们作为一个整体分配在一起,有利于空间的整体内存申请和释放,所以抛开”栈帧”本身的含义,可以将其看成是一个“容器”。在程序运行的过程中,一个函数有一个栈帧,多个函数的栈帧连起来,就变成了堆栈。在《算法与数据结构》里”堆栈”是一种数据结构,也是一种容器,堆栈里的元素按FILO的顺序添加删除元素,所以程序的堆栈的成员元素就是函数的栈帧,而栈帧本身也是个容器,因此程序的堆栈算是容器的容器
堆栈的作用
对于调用者函数和被调用者函数,CPU首先需要拿到函数的机器指令位置。在编译阶段,编译器就将这两个函数的内存地址以标号这种相对位移方式(专业讲叫代码段)保存在了内存,因此CPU一定能拿到这两个地址。其次CPU从调用者函数进入被调用者函数后,需要为其变量分配内存空间,以便在内存中存储内部的局部变量值,那么就会创建对应的栈帧,而这两个对应的栈帧理论上可以分配到内存的任意位置,就类似于hashmap一样空间割裂也无所谓,但是这种碎片化的分配策略与线性分配策略相比,除了会造成CPU更多的计算(散列计算)外,还会造成更多的存储空间浪费,这种浪费体现在CPU对每一个堆栈的首地址的记忆上。对于线性顺序排列的堆栈布局中,CPU只需要知道每一个函数所需要的堆栈大小和第一个函数的堆栈起始位置(栈底),就可以推算出后续其他函数的堆栈起始地址,而且对于现代成熟的计算机和编程语言而言,都不需专门计算某个函数的堆栈起始地址,因为每个函数的栈底地址直接等同于其调用者函数的栈顶。而散列的策略下不但需要知道每个起始地址并保存下来,调用函数执行完后还需要重新定位到调用函数的堆栈空间地址,两个函数都需要额外留出一个指针宽度保存互相函数的堆栈空间地址,而如果是多个函数调用则需要留出更多空间来保存调用函数的地址,这是非常消耗内存空间的。而对于CPU读取堆栈空间,线性顺序的策略,当调用者函数进入被调用者函数时,由于SP寄存器保存了调用函数的栈顶地址,因此CPU可以直接使用mov %sp, %bp这种纯粹寄存器数据传输的方式读取到被调用函数的栈底,在计算机内部没有比纯寄存器之间直接数据传送更快的了。更进一步,随机散列策略不仅在时间和空间上低效,对堆栈的优化也被束缚地死死的,在Java虚拟机中,对堆栈有一项重要的优化策略就是堆栈重叠,即调用方法的操作数栈与被调用方法的局部变量表重叠,这能避免调用者函数内部局部变量中的入参被复制到调用方法堆栈,可以减少相当可观的内存数据复制
由于线性顺序分配栈帧(即堆栈的空间)有这么多好处,因此称为设计栈帧容器的优秀策略,而线性顺序存储元素成员的容器有好几种,最重要的两种容器分别是堆式容器(队列)和栈式容器,它们的区别就是FIFO和FILO,而由于函数调用的链路关系,最后调用的函数最后分配,而且最早被释放,因此自然使用栈式结构来作为栈帧的容器,这就是堆栈的由来。其次,操作系统一般是从高位地址向下扩展堆栈空间,而堆栈作为一个内存容器,并不一定非得从高地址开始往下增长,也可以从低地址向上增长,有部分操作系统是这样的。更重要的一点,对于一个应用程序,操作系统明显会将程序内存分为堆和栈(当然还有其他,比如方法区等),其中堆区往高地址增长,栈区向低地址方向增长,这是操作系统为了区分程序内存的堆内存和栈内存,不破坏函数栈帧在空间上的线性连续性的做法
例如main()函数堆栈从0开始分配(实际上不存在这种情况),mian()函数堆栈需要32字节空间,分配完毕后下一个数据会从第32内存单元开始分配,这时main()函数调用了alloc()向操作系统申请内存空间,那么操作系统将从第32内存单元开始分配,之后main()函数调用add()方法,此时CPU为add()函数分配栈空间,这时候栈空间的起始位置就在alloc()函数申请内存的末端位置。这样一来,main()函数与add()函数的栈帧在内存空间上就不是线性顺序的了,处于割裂状态。所以这要求存储程序函数栈帧的容器 – 堆栈,在内存分布上必须是完全线性的,中间不能出现任何分割。既然如此操作系统就要完全将应用程序的堆内存空间和栈内存空间完全隔离开来,将此作为操作系统治理内存的基本宗旨,而这也是程序函数堆栈这个级别的数据结构与软件程序中的堆栈的数据结构之间最大的不同点
在软件程序中设计所谓的堆栈容器,栈中的元素可以是容器,但是栈中往往仅保存对应元素的容器的指针,指针所指向的容器在堆中开辟空间,这便导致各个元素所指向的容器空间之间并不是连续的线性分布。使用软件程序模拟的栈帧完全是操作系统随机分配的内存空间,因此软件程序定义的栈结构,与操作系统层面的程序函数堆栈结构之间还是有区别的,程序函数堆栈中各个栈帧之间是完全紧密顺序排列的,栈帧之间不可能出现别的数据。如果要使用软件模拟出程序函数堆栈的空间分布,就需要将栈帧的分配变成堆栈这个大容器统一分配一整块连续的内存,然后在这块内存中再按顺序存放栈帧,当堆栈容量不够时,通过扩容重新分配一整块连续的内存空间,然后重新按顺序进行排列。综上所述,程序函数调用的堆栈的成员元素是栈帧,堆栈作为一个容器,其内部存储的是栈帧这种元素,而栈帧又是一个小的容器,存储函数内部的局部变量。函数调用堆栈与软件程序里设计堆栈结构最大的不同在于,函数调用堆栈的成员元素之间是连续分布的,而软件程序里设计的堆栈结构成员往往是不连续的
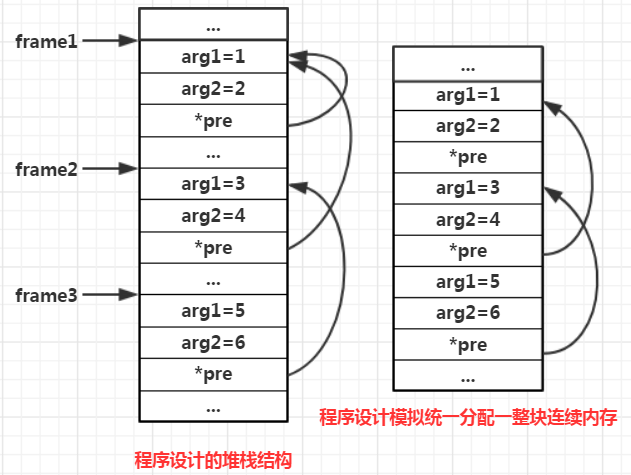
硬件对堆栈的支持
为了支持应用程序函数栈帧形成的堆栈结构,专门设计了两个硬件寄存器 —— SP和BP,用于存储当前函数栈帧的栈底和栈顶,在操作系统层面,栈底和栈顶指针是针对栈帧而言的,而软件设计实现的堆栈的栈底和栈顶指针更多是用来指向整个堆栈容器的底部栈帧和顶部栈帧。对于软件实现的堆栈,只需要获取指向堆栈顶部栈帧的指针,就能实现压栈和出栈的功能。而程序函数调动时为函数说开辟的堆栈空间,由于不同函数其内部局部变量不同,因此栈帧空间结构和大小都不同,必须要区分保存函数栈帧的栈顶地址和栈底地址,CPU会分别使用SP和BP这两个寄存器存储当前位于堆栈顶部的栈帧的栈顶与栈底。如果没有SP和BP这两个硬件寄存器,系统也能完成对堆栈顶部函数栈帧的栈顶与栈底标记,只不过要将其保存到内存,而内存的访问性能与寄存器不是一个档次,所以函数栈帧的空间分配虽然用纯软件也能实现,只不过借助两个特定的寄存器硬件,效率更高而已
当CPU完成一个函数的执行后,程序流会跳转到当前函数的调用方,同时CPU需要回收掉当前函数的栈帧空间,并使SP和BP这两个寄存器重新指向调用者函数的栈顶和栈底。CPU回收函数栈帧空间很简单,只需要将SP往BP方向移动一定距离就可以了,而重新定位到调用者的栈顶和栈底,由于真实的程序函数调用堆栈里的各个栈帧是首尾相连的,被调用者函数的栈底就是调用函数的栈顶,因此CPU在完成函数执行后,只需要将被调用函数的SP指向被调动函数的BP,这恰好是调用函数的SP,剩下将BP也恢复到调用者函数的栈底即可。在机器的函数调用堆栈层面,由于不同函数定义完全不同,因此栈帧结构大小不同,当进行出栈时想要将BP恢复至调用者函数的栈底,需要当前函数保存调用者函数的栈底地址,因此真实的函数调用中,物理机器必定会将调用者函数的栈底地址压入被调动函数的堆栈中,因此使用C语言或其他语言的程序被编译后,产生的每个函数机器指令必定包含这两条指令:push %bp+move %sp, %bp
栈帧的回收
操作系统为了简化内存管理,将内存空间划分为堆和栈,并且栈必须是内存空间中连续分配的,而堆可以随机分配。除此之外操作系统将堆和栈分开还有另一个原因,即两者的空间分配不同。使用C/C++开发的一大难点就是内存管理,容易造成内存泄漏,而造成内存泄漏的原因就是忘记释放已经申请的堆内存空间。对于使用malloc()接口申请的空间如果不使用free()去登记释放,除非程序结束,不然这部分申请的内存不会被回收,而相比于堆内存空间管理的要求,栈的开辟与回收就十分简单,想要开辟一个栈空间,只需要执行sub $32, %sp指令,将SP指针向前移动32个存储单元的距离,需要释放也只需要执行add $32, %sp将SP指针再移回去就可以了。而这在高级编程语言中被封装到了leave指令里了,是基本看不到的。因此应用程序申请和释放栈十分简单,这得益于栈的结构:必须连续线性分布
不管是为了能高效实现栈帧的压栈与出栈而将堆与栈空间分离,还是纯粹为了分开治理后能享受高效的压栈与出栈算法带来的性能提升,将应用程序中的堆与栈隔离开来,并规定栈帧在堆栈空间中必须线性连续分布,并借助SP与BP两个寄存器来实现高效的压栈与出栈指令,是历史上伟大的软件设计师经过千锤百炼后得出的最优方案,是精华中的精华
堆栈大小与多线程
现代操作系统支持多进程和多线程机制,JVM也是支持的。那么由于操作系统会将一个应用程序中的内存空间划分为堆和栈两大部分,函数的栈帧只能在栈空间分配,那么在多线程环境下,操作系统会为一个线程单独划分一个栈空间,还是一个应用程序下所有线程共用一个栈空间呢?
其实很简单,因为栈帧在堆栈空间中必须线性连续分布,如果多线程下同时执行一个函数,那么它们将被分配在了一起,造成被调用函数与调用函数隔离,这样不连续的内存布局对栈帧分配与回收,甚至栈帧的覆盖重写都造成影响。所以为了支持多线程应用,操作系统必须为应用程序的每一个线程专门划分一块连续的区域,各个线程中的函数就在各自的私有内存区域按照单一方向进行压栈与出栈
同理,一个操作系统上的不同应用程序(进程),为了每一个应用程序的堆栈空间能遵循线性顺序分布的规则,就需要操作系统在加载一个应用程序时,为其划分一块独立的、连续的内存区域作为其堆栈之用,这块内存区域不会与其他应用程序重叠
那么由于一个操作系统上会有许多进程,而一个进程中会有许多线程,最后大量的线程与有限的内存容量之间形成了矛盾,因此线程堆栈的空间不是任意大的,在大部分操作系统中都有默认的堆栈空间大小设置,例如64位Linux上默认的堆栈空间大小是1MB,而对于JVM可以由我们自行设置Java线程堆栈的空间大小。以Java程序为例,由于Java是面向对象的语言,因此线程堆栈上只有指向对象的指针,对象的实例不在堆栈上(JVM为了优化而内部实现的栈上对象分配策略除外),如果没有开启指针压缩选项,那么64位机器上一个指针占64bit的内存空间,那么1MB空间可以容纳1 * 1024 * 1024 * 8 / 64 = 131072,即13万多的指针宽度,大部分情况下是够用的,而且1MB的堆栈空间对于一个线程而言显然是比较浪费的
对比小结
关于栈(堆栈stack)和栈帧(frame):
1、每个JVM线程有一个私有栈,栈在线程创建的同时被创建
2、栈由许多帧组成,也叫”栈帧”
3、每次方法调用都会创建一个栈帧
换句话说,当一个Java方法被执行时:
1、当方法被执行时,一个新的栈帧被创建并用来给这个方法存储数据
2、栈帧大小各不相同,取决于方法的参数、局部变量和算法
3、当一个方法被执行时,程序只能访问当前栈帧中的数据,你能看到的只有栈顶的帧
1、关于栈(stack)与堆(heap):
—)stack: 栈使用的是一级缓存,通常都是被调用时处于存储空间中,调用完毕立即释放。操作方式类似于数据结构中的栈(FILO)
—)heap: 堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定
2、申请方式:
—)stack: 由操作系统自动分配,在函数中声明一个局部变量int b,系统自动在栈中为b开辟空间
—)heap: 需要程序员自己申请,并指明大小,例如C中malloc函数,当然Java是自动管理栈和堆的
3、申请后系统的响应:
—)stack: 只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出
—)heap: 操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。大多数系统会在这块内存空间中的首地址处记录本次分配的大小,另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中
4、申请大小的限制:
—)stack: 在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域
—)heap: 堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址
5、申请效率的比较:
—)stack: 栈由系统自动分配,速度较快,但程序员是无法控制的
—)heap: 堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便
6、存储内容:
—)stack: 局部变量表、操作数栈、动态连接、方法返回地址和一些额外的附加信息(固定帧)
—)heap: 一般在堆的头部用一个字节存放堆的大小,堆中的具体内容由程序员决定
JVM的栈帧
Java虚拟机是建立在物理操作系统之上的虚拟系统,其栈帧与操作系统的栈帧有所不同。操作系统直接基于CPU硬件执行指令,而JVM则只能基于栈式指令集运行,两者不同的运行机制决定了栈帧结构的不同。但是JVM本身又没有真正的执行能力,因此最终还是依靠调用CPU硬件指令去完成程序逻辑,因此Java函数的栈帧又与物理机器的栈帧有莫大的内在联系,主要体现在:
1、堆栈的设计:Java函数的堆栈设计直接借用操作系统的堆栈管理思想,JVM也将一个Java应用程序的内存划分为堆内存与栈内存分别治理。另一方面Java函数的调用链路既然也使用堆栈这种容器级别的数据结构,也决定了Java应用程序的堆与栈要分别划分
2、栈帧的设计:由于堆栈作为栈帧的容器,因此也是压栈和出栈,栈帧的设计也随之确定,而Java函数的内部数据使用栈帧这种容器进行存储,也必然导致Java函数的栈帧要存储Java函数的局部变量
在前面讲过,Java栈帧除了要保存Java方法的局部变量外,还需要保存一些支持堆栈开辟与回收的上下文数据。在Java栈帧中保存局部变量的区域叫局部变量表,保存上下文数据的区域叫JVM帧数据(fiexd frame)。由于Java语言被编译后生成的指令,并不是与硬件寄存器相关的,大部分是围绕栈的指令,例如iload将数据压栈、istore将栈顶数据弹出、iadd对栈顶的数据进行累加等。与直接基于寄存器指令的操作类似,栈式指令集若想对栈中数据进行操作,就需要一部分内存被当做栈空间,这样栈式命令才能对栈中数据进行逻辑运算,因此JVM必须为每个Java函数划分一定的空间作为栈式指令集操作的对象,既然每个函数都有一个与之配套的栈帧空间,因此将栈帧与操作栈合二为一。这样一来Java方法栈包含了至少3个部分:
1、Java方法的局部变量表
2、Java方法堆栈调用的上下文环境数据,即固定帧
3、Java方法的操作数栈
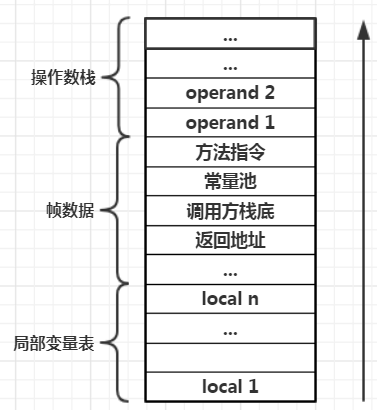
在编译程序代码时,栈帧需要多大的局部变量表,多深的操作数栈都已经完全确定了,并写入到字节码文件(.class)的方法表Code属性中,因此一个栈需要分配多少内存不受到程序运行期数据的影响,只取决于具体的虚拟器实现(还有slot复用与调用方法时操作栈复用)。在C/C++语言中有动态链接库的概念,Java中也有类似概念,每个栈帧都包含一个指向运行常量池中该栈帧所属方法的引用,字节码中的方法调用指令就以常量池中指向方法的符号引用为参数。这些符号引用一部分会在类加载阶段或第一次使用时转化为直接使用,这种转换成为静态解析。另一部分在每一次运行期间转换为直接引用,这部分成为动态链接,因此要实现动态链接需要Java方法栈中持有一个指针,指向常量池,以便能得到该Java方法的字节码指令,并根据字节码指令映射到机器指令完成方法逻辑处理
栈帧创建
entry_point例程的generate_normal_entry函数中,会为Java方法创建栈帧,然后引用计数,开始执行Java方法的第一条字节码。其中创建栈帧是在void TemplateInterpreterGenerator::generate_fixed_frame(bool native_call){}方法中创建的,具体代码可看templateInterpreter_x86_32.cpp文件,这个方法大体上可以分为9步:
1、恢复return address
2、创建新的栈帧
3、将最后一个入参位置压栈
4、计算Java方法的第一个字节码位置
5、将methodOop压栈
6、将ConstantPoolCache压栈
7、将局部变量表压栈
8、将第一条字节码指令压栈
9、将操作数栈栈底地址压栈
恢复return address
return address是干嘛用的,之前已经分析过几次了。那么来看这里为什么要恢复return address。在创建局部变量表前,用了pop %eax指令将return address从栈顶弹出至寄存器eax中,之后Java方法的局部变量全部入栈,于是就要把return address再次还原到堆栈中。这是因为Java方法的入参和内部局部变量共同组成了局部变量表,作为一个整体不能被分割,所以将return address先取出,在局部变量全部压栈后再恢复至栈顶
创建新的栈帧
创建新的栈帧,就是通过硬件寄存器真正开始为被调用的Java方法分配堆栈空间。第一步就是要标识出自己的栈底,栈底就是一个新的栈帧的领域边界,栈帧划分边界的方法也很简单,就是执行push %ebp和mov %esp, %ebp这两条机器指令即可。这样被调用的Java方法就有了自己栈帧的区域,接下来新增的栈帧空间就都属于被调用的Java方法了,以后对这块区域内的数据进行访问时都必须以新的bp(栈底指针)为基准进行偏移寻址。Java在这里又与C/C++有点不同,C/C++调用这两条指令后才会配合sub $operand, %esp为被调用函数分配新的栈帧,而Java在前面创建局部变量表时,局部变量表其实已经是被调用方法自己栈帧空间的一部分了,那么为什么不在创建局部变量表的时候进行这两条指令呢?主要基于两点考虑:第一点是局部变量表的整体性,之前的创建局部变量表其实严格上只能算Java局部变量压栈,因为局部变量表不仅包括局部变量,还包括Java方法的入参,而Java函数入参入栈逻辑在entry_point例程的调用方CallStub例程中执行,而Java函数局部变量入栈逻辑在entry_point例程中完成,虽然Java函数入参的堆栈区域和Java函数局部变量所在的堆栈区域分别属于两个不同的栈帧,但是对于被调用者函数来说,无论方法入参还是局部变量都属于局部变量表,当Java查询执行Java字节码指令读写Java方法的局部变量表时,将Java函数的第一个入参所在堆栈位置作为偏移基址对局部变量进行变址寻址,而调用函数的栈底基址ebp明显不属于被调用函数的局部变量表的一员,自然不能被字节码读写,因此不能在对局部变量进行压栈前执行这两条指令,这与将return address先弹出防止破坏局部变量表完整性是一个道理;第二点是这时执行这两条指令,能让Java方法栈帧内的帧数据(fixedframe)进行相对寻址方便,因为这部分是固定不变的,而局部变量表与操作数栈的大小随Java方法的不同而不同,因此位于局部变量表顶部往下能很容易的读取堆栈中fixed frame部分的数据。不过虽然bp被放在了被调用的Java方法的局部变量区域后面,但是局部变量仍然属于被调用的Java方法的栈帧空间的一部分,毕竟Java方法字节码在访问方法自己的局部变量表时,是将局部变量表当做自己栈帧空间的一部分的
将最后一个入参位置压栈
generate_fixed_frame函数接着会执行__push(rsi)指令,对应机器指令push %rsi,当时在CallStub()函数时,rsi寄存器保存的是Java方法最后一个入参在堆栈中的位置,所以在执行完这条指令后,Java方法的最后一个入参的位置就被亚茹Java的方法栈中
entry_point例程被CallStub例程调用,也可能被其他例程调用,例如Java方法调用Java方法时,就会被invoke_virtual或invoke_special等例程调用。当entry_point例程由CallStub例程调用时,CallStub例程流程进入entry_point时,其栈顶元素正好就是被调用的Java方法的最后一个入参,所以这个位置就是CallStbu例程所对应的函数的栈顶。同样,当entry_point由其他例程进入时,被调用的Java方法的最后一个入参位置也是调用方例程的栈顶,所以这个最后一个入参是调用方函数的栈顶,再往前就进入了被调用方的堆栈空间,这个位置成为调用方与被调用方的栈帧空间的分水岭
由于执行本指令前通过上面那两个指令push和mov将调用方的栈底指针ebp压入堆栈,同时将调用方的栈顶指针esp的值赋值给ebp,作为被调用方的Java方法的栈底,因此被调用Java方法的栈底实际上便是调用方esp栈顶指针。esp实际上指向了Java方法栈帧fixed frame的底部,这个位置已经超出了Java方法局部变量区域,对于Java方法运行没什么影响,但是对于Java运行完成后回收堆栈空间有很大的问题。在C/C++等语言中ebp指针指向被调用函数栈帧的栈底,因此回收被调用函数的栈帧空间时,只需要将esp恢复至的被调用函数的ebp指针即可。而Java方法栈帧由局部变量表、帧数据、操作数栈三部分组成,其中局部变量表又一分为二,一部分为Java方法入参区域,一部分为Java方法局部变量区域,前者属于调用方的栈帧,后者属于被调用方的栈帧空间,因此Java方法完成后需要回收的有帧数据、操作数栈以及局部变量表中局部变量所在区域,而执行完这两条指令后调用方的栈顶指针esp赋值给了被调用Java方法的栈底指针ebp,而esp指向的是不是局部变量表中入参区域与局部变量区域的分界处,因此如果以ebp来确定要回收的堆栈区域会出现异常,因此为了能正确回收被调用的Java方法的栈帧空间,必须记录Java方法的调用方的回收的栈顶位置,就是将Java最后一个入参在堆栈中的位置进行压栈的意义所在,在HotSpot内部,这步骤也称为set sender sp,即调用方栈顶保存
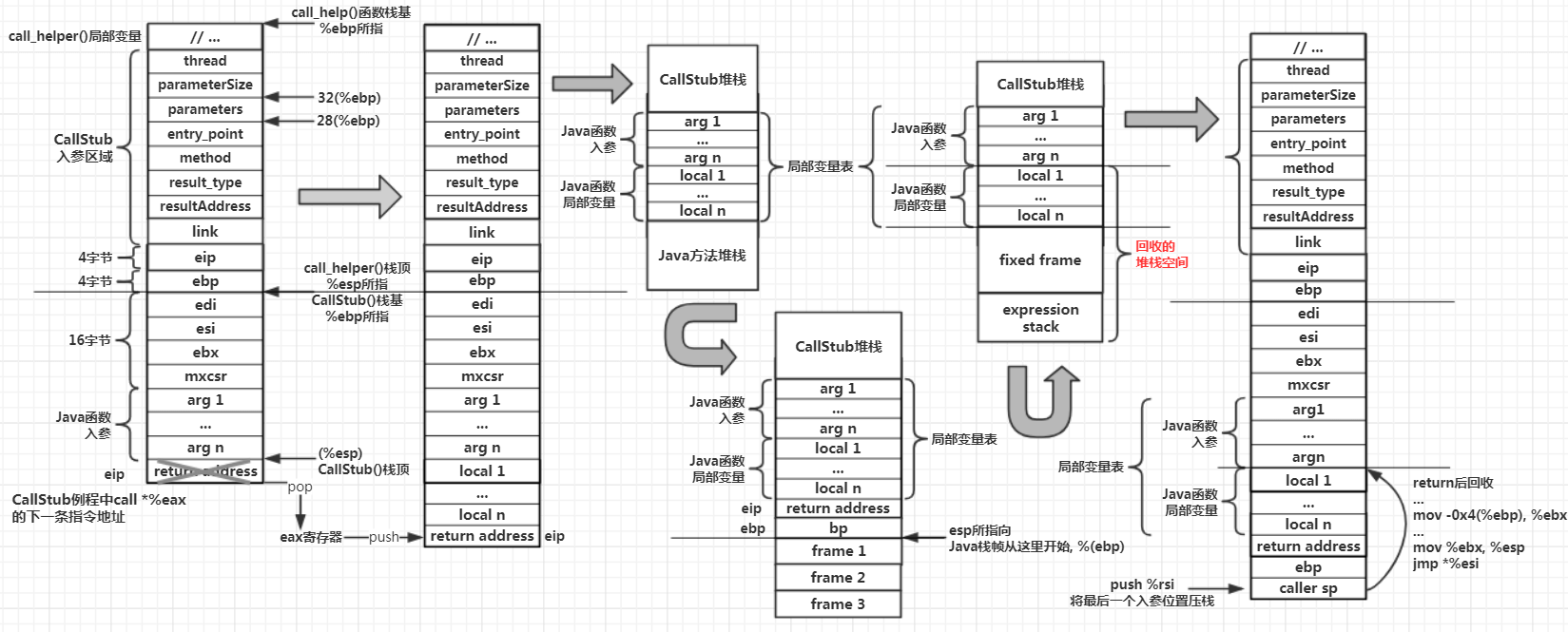
计算Java方法的第一个字节码位置
在进入entry_point例程前,ebx寄存器保存的是Java方法在JVM内部对应的methodOop对象首地址,generate_fixed_frame函数执行代码对应的机器指令为mov 0x8(%ebx), %esi,其中0x8(%ebx)正好就是constMethodOop,constMethodOop对象在常量池解析阶段生成,该对象主要保存Java方法中的只读信息,例如异常信息表、Java方法注解信息、方法名、Java方法的字节码指令等,因此这条指令后esi寄存器将存储constMethodOop对象的内存地址。之后执行的第二行代码对应的机器指令为lea 0x30(%esi), %esi,让esi寄存器指向末尾,也就是Java方法字节码的第一个指令的位置,即Java类方法的字节码指令保存在constMethodOop最后一个字段generic_signature_indx的末尾
将methodOop压栈
在generate_fixed_frame函数中使用__ push(rbx),对应机器指令为push %rbx,rbx寄存器指向Java方法在JVM内部所对应的methodOop对象首地址,这一步就是将其首地址压入栈中,在Hotspot调用Java方法的过程中,可以通过这个地址读取到Java方法的全部信息,例如进行多态运行期动态方法绑定时需要定位到callee从而决定到底调用继承体系中的哪一个对象的方法
将ConstantPoolCache压栈
通过相对于methodOop首地址偏移量0xc(32位X86平台),可以得到constantPoolOop指针,该指针指向Java类对一个的内存常量池首地址,Hotspot通过mov 0xc(%ebx), %edx指令将该首地址传给ebx寄存器,在constantPoolOop内相对于首地址0xc的字段是constantPoolCacheOop,因此通过mov 0xc(%edx), %edx将constantPoolCacheOop首地址传给edx寄存器,接着执行push %edx将constantPoolCacheOop首地址压入Java方法栈中
由此可知,对于同一个Java类文件中的所有Java方法,每一个Java方法的栈帧中都必须持有指向该Java类解析后所生成的常量池缓存对象的地址,常量池缓存中的内容皆是直接引用,不像常量池那样存的都是索引号
将局部变量表压栈
执行__ push(rdi)指令,对应机器指令push %rdi。在前面写到过,初始化Java方法局部变量区域时,通过不断循环执行push $0x0为方法内的局部变量开辟堆栈空间并初始化为0,在这个循环之前,Java方法的第一个入参在堆栈中的位置被传送给了edi寄存器,并且中间没有被修改,因此这相当于将Java方法的第一个入参在堆栈中的位置(即局部变量表第一个槽位)压入栈,在Java方法执行的时候,Java字节码可以通过edi寄存器(locals pointer)读取局部变量表
将第一条字节码指令压栈
接下来generate_fixed_frame函数会执行:
if (native_call) {
__ push(0); // no bcp
} elsse {
__ push(rsi); // set bcp(byte code pointer)
}
由于JVM既可以加载Java类,也可以加载C/C++/Delphi等程序库,因此Hotspot通过native_call判断即将被调用的方法是否是Java方法,如果是则将Java方法的第一个字节码指令位置压入栈,并保存在rsi寄存器中;而如果不是那就是本地方法了,C/C++/Delphi这些程序库都会被JVM当做本地方法(即直接本地编译的方法)调用,rsi寄存器在Hotspot有一个专门的称呼,即bcp(byte code pointer),指向Java方法字节码指令的指针
将操作数栈栈底地址压栈
generate_fixed_frame函数最后两行代码对应的机器指令为push $0x0向栈顶压入一个零值,和mov %esp, (%esp)将当前esp寄存器的值覆盖为刚刚压入的零值。在前面的步骤中进行了许多push,CPU会自动将esp寄存器的值更新为当前最新的栈顶位置,因此到这一步的时候,esp寄存器指向了当前堆栈的栈顶,而这时通过覆盖esp为刚刚压入的零值,让栈顶保存的值为当前自己的内存位置。这是因为到本步骤截止,Java方法栈帧的fixed frame部分就创建完成了,Java方法栈帧接下来的部分是操作数栈了,虽然操作数栈也属于Java方法栈的一部分,但是在Java方法的运行过程中,Java字节码进行压栈与出栈会基于操作数栈的栈底位置进行变址寻址,所以Hotspot就将fixed frame的栈顶位置记录下来,这正好是操作数栈的栈底位置,在Hotspot内部这个位置称为”expression stack bootom”,即表达式栈栈底
Java栈帧详细结构
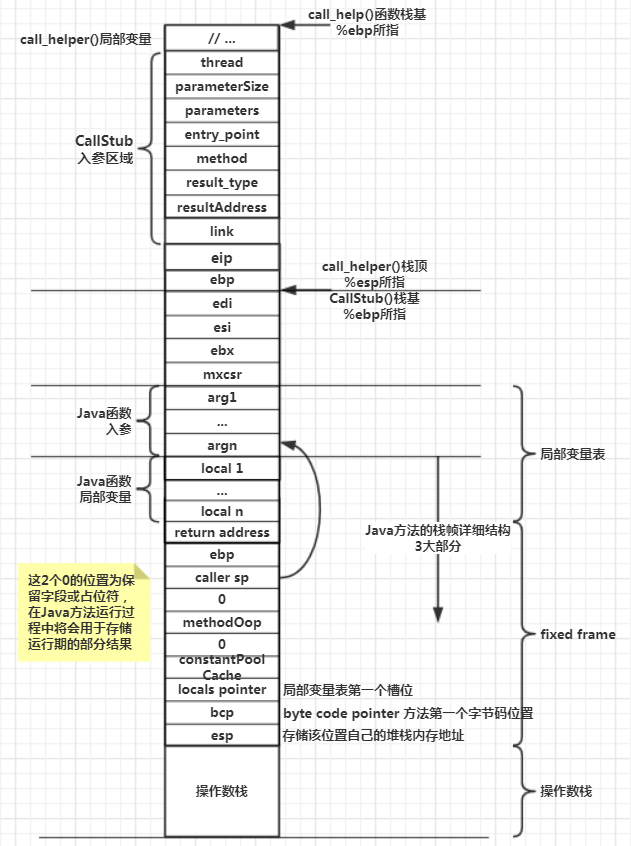
Java栈帧与C/C++的栈帧大不相同,不像C/C++那么简单明了,比较复杂,主要体现在以下几点:
1、栈底与局部变量表底不是同一位置:Java方法的局部变量表包含两部分,分别是Java方法入参区域与Java内的局部变量区域,但是Java方法入参区域并不属于Java方法的栈帧,而是属于其调用方的栈帧的一部分,因此Java方法栈由局部变量表、帧数据、操作数栈组成不是太严谨,因为Java方法栈仅包含了局部变量表的一部分区域。而又因为局部变量表的两部分区域属于不同的方法,因此调用函数完成后对其堆栈空间进行回收时,必须标记其真实的栈底位置,所以Hotspot只能在fixed frame中保存了Java方法的最后一个入参的堆栈内存位置,这个位置就是调用方的栈顶,也是被调用方的Java方法的栈底,通过这个标记确定回收范围。而且因为Java方法的入参区域和局部变量区域属于两个不同的方法,但是对于被调用方而言,这两个区域需要在物理上连成一片,这样才能形成一个整体,作为一个完整的局部变量表,方便被调用的Java方法的字节码指令对局部变量表进行读写,所以最后只能将调用方栈底指针bp保存到fixed frame中
2、Java栈帧需要额外保存若干数据:栈帧中的fixed frame其实与Java的源程序指令没有丝毫关系,这块区域保存了运行时数据,这点与其他编程语言差别很大。比如C/C++在编译后站着那几乎全部用于保存函数的入参与局部变量,还有寥寥几个寄存器上下文的保存现场。而JVM由于是使用软件模拟的虚拟系统,硬件资源有限,因此只能用软件的方式保存上下文,例如fixed frame区域保存bcp,而C/C++有硬件ip段寄存器自动存储;又比如caller sp,在C/C++中有硬件bp存储区去存储。而且Java方法栈帧的复杂性结构,也与JVM自身执行引擎与内存模型决定
在generate_fixed_frame函数(该函数会在JVM启动之初被调用执行,只会生成对应的机器指令,并不会直接执行)执行完后,即它所生成的机器指令完成后,物理寄存器最终的变化为:
| 寄存器名 | 指向 |
|---|---|
| edx | constantPoolCache |
| ecx | Java函数入参数量(没变) |
| ebx | 指向Java函数,即Java函数所对应的method对象 |
| esp | Java方法栈的fixed frame顶部 |
| ebp | Java方法调用方的栈底 |
| esi | bcp,即byte code pointer方法第一个字节码位置 |
| edi | locals pointer |
| eax | return address |
局部变量表
那么步骤介绍完后,回过来完整的看下局部变量表。局部变量表即JVM为Java方法内的变量在堆栈上所分配的一块连续内存空间,用于保存Java方法的入参与局部变量。我们Java程序员无法直接编写代码对局部变量表进行读写,这种结构只能通过字节码指令进行访问和写入,并由JVM在运行期进行动态读写,它作为堆栈的一部分也决定了只能由机器指令或JVM这种能创建与销毁堆栈的虚拟机器访问。局部变量表的深度由编译器在编译期间计算出来,因此Java方法的入参与局部变量的slot索引号在编译器就确定下来。slot索引号由iload字节码指令读取,istore字节码指令写入
总体而言,局部变量表的生命周期包括以下环节:
1、在编译期间,编译器通过文法、语义解析,计算出一个Java方法所需的局部变量表大小,并写入Java class字节码文件的方法属性的Code属性表中
2、在JVM加载Java类的时候,会解析Java class字节码文件中的方法信息,并解析出局部变量表的大小,将这个数据加载到内存中
3、当JVM准备调用Java方法时,会为该方法创建栈帧,而栈帧中包含了局部变量表的空间,入参与局部变量按顺序分配,各有一个solt索引号
4、当JVM具体执行Java方法时,便调用Java的iload和istore系列指令对栈帧中的局部变量表的空间进行不断读取和写入
5、当JVM执行完Java方法后,Java方法的栈帧空间被销毁,局部变量表会一并被销毁
由于局部变量表是建立在堆栈空间上,线程私有的数据,所以JVM对其进行的一切操作都不需要考虑并发问题
在JVM内部,局部变量表按照槽位(slot)为基本单位进行划分,JVM规定一个槽位应该能存放一个boolean、byte、char、short、int、float、reference(对象引用)或returnAddress(指针类型的数据)类型的数据,但是这些不同类型的数据所需的内存空间是不同的,而slot的基本单位是确定不变的。而JVM规范规定一个slot槽位能存放一个reference,但又说long类型需要2个slot来存放,而在64位平台上不开启指针压缩功能,引用类型与long类型占的内存空间是一样的,那为什么JVM这么规定?而一个slot长度又是多大?
JVM在创建Java方法栈的时候,将局部变量表的起始位置存在了edi寄存器中,并且局部变量表的所谓起始位置就是Java方法的第一个入参的内存位置。在JVM准备调用一个Java方法前,会将这个方法的N个入参压栈,复制到局部变量表中,但是此时JVM并不关注这些入参的实际类型,而是统一当成指针类型进行处理,因此在32位平台上第一个入参在堆栈的内存位置是按其数据宽度4字节进行计算的,那么如果第一个入参是long类型,按照JVM规范岂不是位置不对了么?最终存储到edi寄存器的所谓第一个入参的位置并不能代表真实的第一个入参的内存位置。这个特殊性在Java字节码指令中读取局部变量表的load指令对应的机器层面处理,load对应的机器码实际上是将edi寄存器所指的位置当做基准偏移位置,由于第一个入参long类型实际位置与edi基准不同,因此反应到机器码层面会对edi进行偏移,读取第一个long入参的指令在32位平台上需要执行mov -0x(%edi), %edx和mov (%edi), %edx,从edi寄存器下一个4字节位置开始读取,一次mov读取4字节,使用两次mov指令连续读取2个4字节数据并保存到两个寄存器中,这实际是用了栈顶缓存技术。而如果第一个入参是int类型则只使用了一次mov (%edi), %eax。那么如果入参1和入参2都是int类型,通过iload_0和iload_1之间分别对edi寄存器最了多大的偏移即可知道32位平台上一个slot的大小,最后结果是iload_1使用了mov -0x4(%edi), %edx,即第二个int入参在局部变量表相对于edi起始位置偏移-0x4字节,等于一个slot的大小,即4字节。那么对于64位平台的iload_1指令mov -0x8(%edi), %eax得知相对于edi偏移了-0x8字节,即1个slot占8字节。前面说过JVM创建局部变量表时,仍然将每个入参当做一个指针类型变量数据处理,一个指针在64位平台占8字节,因此edi寄存器所指的位置后面可以放下一个long类型的数据,也就是1个slot就够了,但是实际上iload_0指令的机器码中用了-0x8(%edi), %rax来获取第一个入参数据,即还是偏移了edi向低地址8字节的位置,那么一个long类型在64位平台占据2个slot也就是16字节的大小。所以JVM的规定是真实的,只不过在JVM内部的局部变量表中long类型才会这样占据16字节,在堆内存中是该占据多大空间就占据多大空间,即8个字节。总结一下:
1、32位平台上一个slot大小为4字节
2、64位平台上一个slot大小为8字节
3、long类型在局部变量表中占据2个slot大小
4、对于数据宽度小于int与reference类型的数据,也是使用iload与istore系列指令,而且会被处理成int类型数据,使用基于int类型数据的读写指令进行读写
栈帧深度与slot复用
前面说过,栈帧的大小会受到限制,所以一个线程中调用的方法太深时,会导致JVM分配栈帧太多耗尽stack space,从而抛出stackOverflow异常。而Java方法栈由局部变量表、固定帧、操作数栈构成,固定帧由于无论什么Java方法都是固定不变的,因此主要由局部变量表和操作数栈决定大小,又由于调用者方法的操作数栈会作为被调用者方法栈帧的一部分,因此一个Java方法的栈帧大小主要取决于局部变量表的大小,即最终取决于入参和局部变量,如果局部变量表所占的空间很大,那么Java线程能调用的最大方法深度就会变小
由于局部变量表的大小影响到一个线程的调用方法深度,因此在声明方法局部变量时,应该尽量使slot能够复用。所谓slot复用,便是让方法内部的不同变量能够占据局部变量表中的同一个槽位,这样就能减少局部变量表的大小,使用花括号可以让Java编译器认为其中变量的作用域不超出花括号范围,因此出了花括号后JVM便会清理里面变量占据的slot槽位,空出来的给内部后续的变量复用
最大操作数栈与操作数栈复用
与Java方法堆栈息息相关的一个重要参数是max stack,即最大操作数栈。Java虚拟机的指令集基于栈,所有计算逻辑都通过栈来完成,这个栈便是操作数栈,JVM内部也叫表达式栈。操作数栈的大小由Java编译器在编译期间计算,但是只会计算出最大的栈深度,这是因为操作数栈大小与slot槽一样可以复用。最大操作数栈被作为Java class字节码文件内部Code属性区的一部分,可以使用javap -v命令查看class文件的每个方法最大操作数栈大小
例如:
public static void main(String[] args) {
int a = 1;
}
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: iconst_1
1: istore_1
2: return
stack表示main()主函数的最大操作数栈只需要1个即可(另locals为局部变量表最大容量,args_size为入参数量),stack的数据宽度与slot槽位宽度一致,也就是main()主函数最大操作数栈空间为1个槽位。然后修改代码:
public static void main(String[] args) {
int a = 1;
int b = 2;
}
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: return
最大操作数栈仍然是1,因为在JVM执行int a = 1这条指令时将1推至栈顶,执行完后1会从栈顶被传至局部变量表中,当执行int b = 1时,JVM就可以复用栈顶的一个空间,那么继续修改代码,调用方法:
public static void main(String[] args) {
int a = 1;
int b = 2;
add(a, b);
}
public static void add(int a, int b) {
int c = a + b;
}
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: invokestatic #2 // Method add:(II)V
9: return
可以看到stack为2,因为main()函数调用了add()方法,由于add()方法包含2个参数,因此main()函数调用add()方法时需要将其需要的两个实参推送至main()方法的操作数栈顶。JVM在执行Java方法调用时,实现了“堆栈重叠”技术,因此这两个栈顶实参将被当做add()方法局部变量表的一部分。如果没有操作数栈复用技术,那么main()函数这时的最大操作数栈一定是4,但是由于int b = 2复用了int a = 1指令的操作数栈空间,而add(a,b)又复用了int b = 1指令的操作数栈空间,因此最终只需要2个槽位大小的操作数栈空间就能满足全部指令的逻辑计算。因此这个最大操作数栈是在内存复用的基础上从一个Java方法所有指令中选出一个需要占用最多操作数栈空间的指令,以该指令所需的空间作为Java方法的最大操作数栈空间。比如继续修改代码:
public static void main(String[] args) {
int a = 1;
int b = 2;
add(a, b);
add(a, a, a);
}
public static void add(int a, int b) {
int d = a + b;
}
public static void add(int a, int b, int c) {
int d = a + b + c;
}
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=3, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: invokestatic #2 // Method add:(II)V
9: iload_1
10: iload_1
11: iload_1
12: invokestatic #3 // Method add:(III)V
15: return
这就很明显了,最后一个add方法需要3个入参,因此最大操作数栈为3
参考:
《解密Java虚拟机》