Java基础: JVM(一) JVM概述与字节码
Java基础: JVM(二) 常量池
Java基础: JVM(三) JVM执行引擎01
Java基础: JVM(四) Java栈帧
Java基础: JVM(五) JVM执行引擎02
Java基础: JVM(六) 类变量和类方法解析
Java基础: JVM(七) 类生命周期与类加载器
Java基础: JVM(八) 热加载
Java基础: JVM(九) Java内存模型
Java基础: JVM(十) 编译相关
编译
编译器可以分为前端和后端:
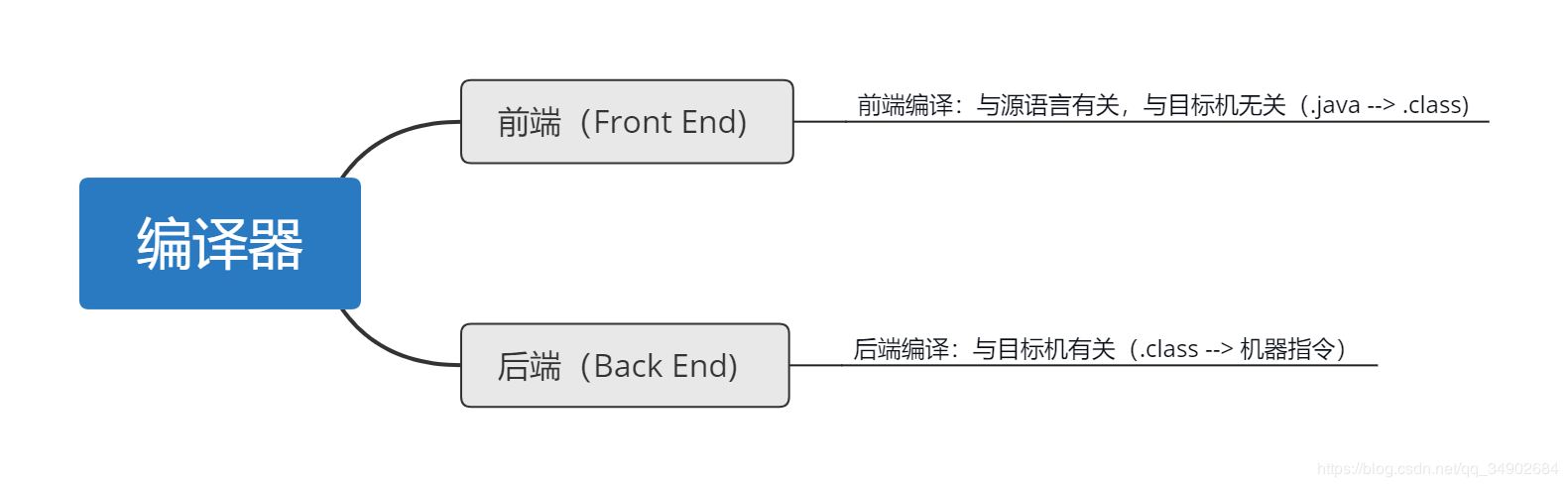 把源代码翻译成机器指令,一般要经过以下几个重要步骤:
把源代码翻译成机器指令,一般要经过以下几个重要步骤:
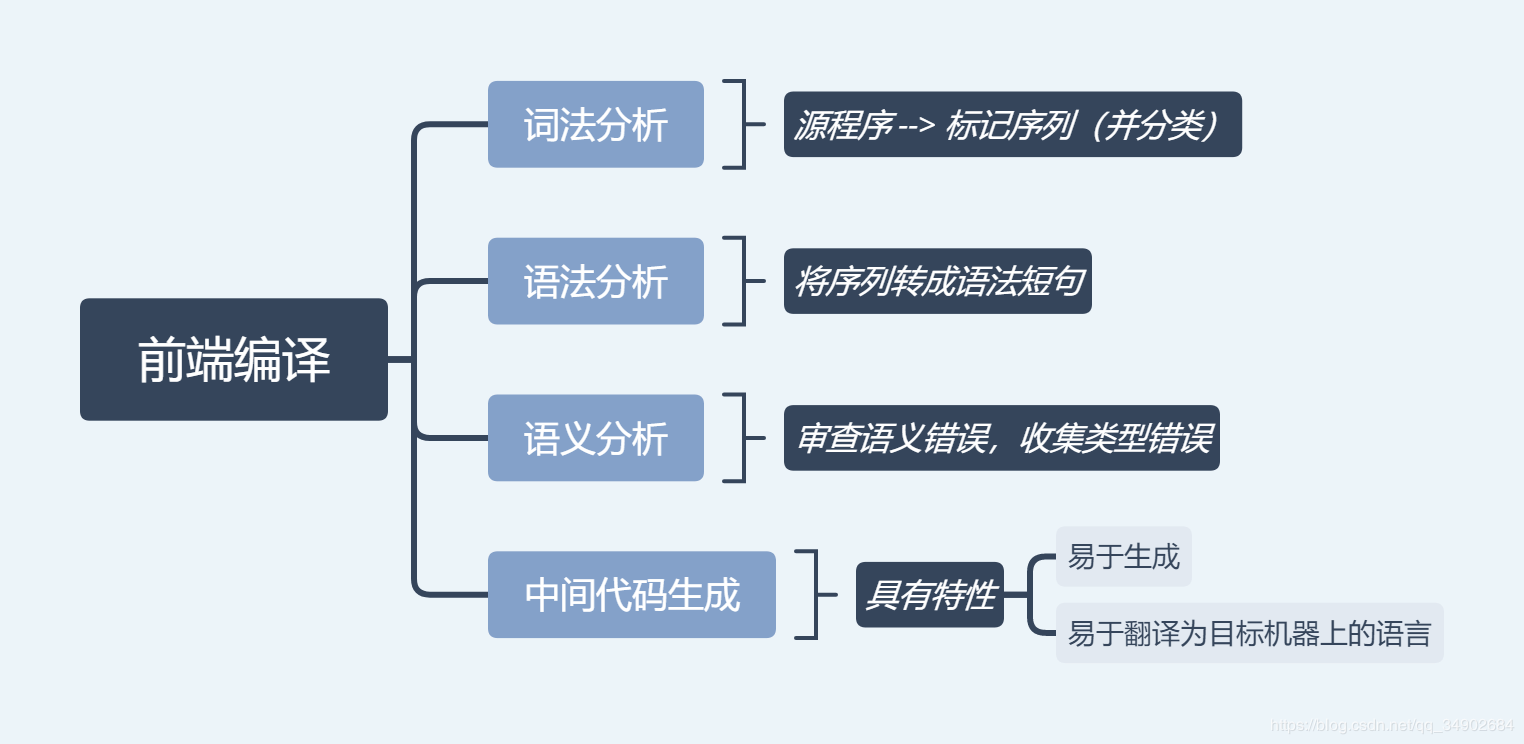
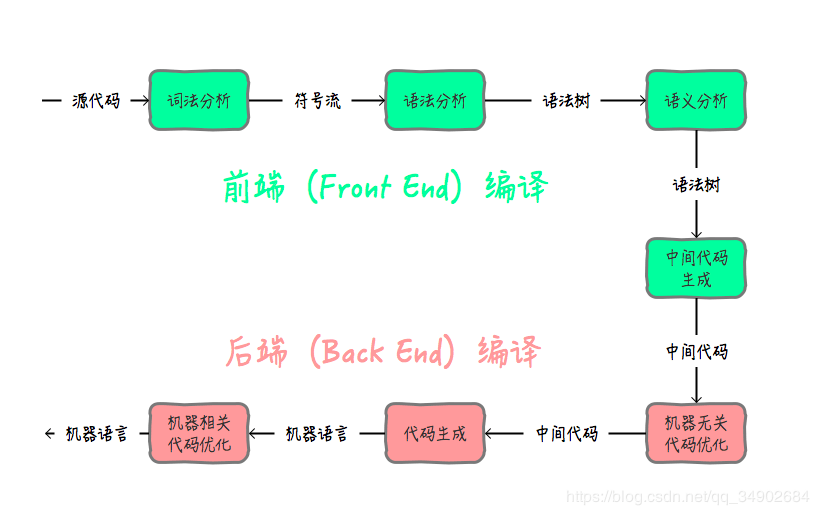 其中前端编译步骤:
其中前端编译步骤:
javac
javac是jdk bin目录下的一个脚本,用于编译java程序的源代码,其实现的本质是基于jdk标准类库中的javac类库实现,所以java的编译器实质上是一个 java程序,而javac脚本仅是一个便于启动以及传递参数的脚本文件,内部依旧运行了java程序
javac又被称作前端编译器,仅负责源代码与字节码之间的转换,而在jvm内部还存在一个后置编译器,根据热点探测技术可以将最有价值的字节码转换为机器码执行从而提升java程序的运行效率
javac的意义就在于将源码编译为字节码,同时做一些词法,语法,语义上的检查,最后生成可供jvm运行的字节码文件
其源码在lib目录下的tools.jar包中,Main类的main方法为入口,创建编译器并调用compile方法进行编译:
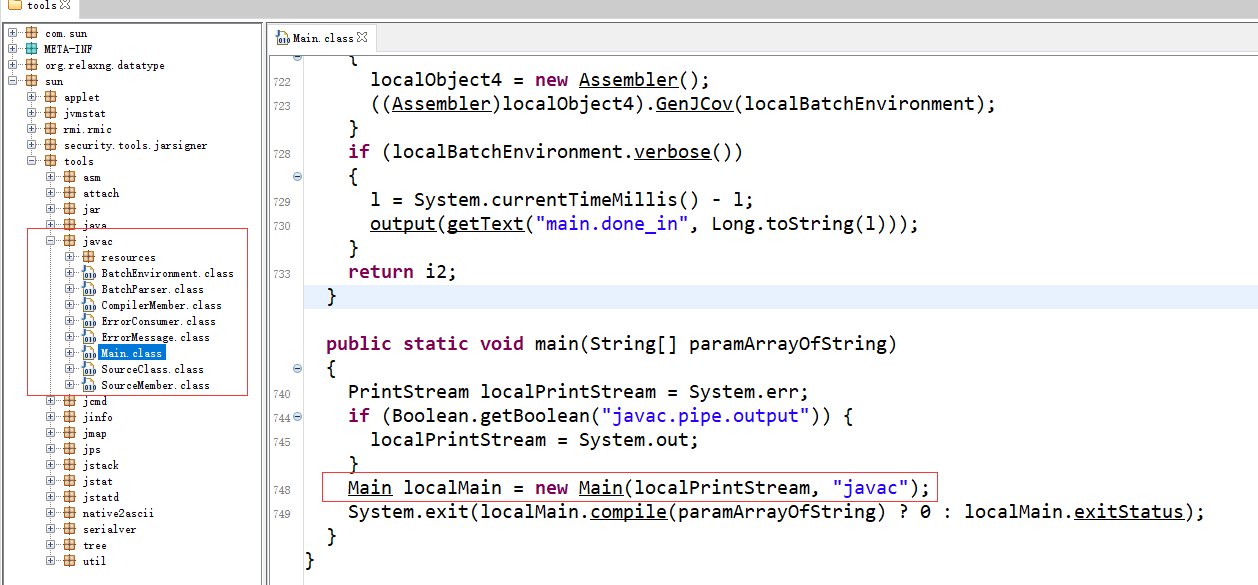
compile方法的步骤可以概括为:
- 解析与填充符号表
- 对java源代码的字节流进行读取解析,进行两个大致的步骤,词法解析以及语法解析
- 词法解析:识别java源码中存在的表达语义的逻辑单元,列如”关键字”、”变量名”、”参数名”,每一个逻辑单元称为”标量”,即从源代码中找出一些规范化的Token流
- 语法解析:将各个独立的”标量”按照java语法规范形成一个java语法规范的抽象语法树,语法树的每一个节点代表一个操作、运算或者方法调用
- 填充符号表:解析后的语法树最顶级的节点将被用来填充在符号表中,符号表存储着各个语法树的最顶级节点,填充后的符号表最终形成待处理表
- 符号表就是一个遵从java语法的结构规范,用于组织语法树的逻辑顺序
- 对java源代码的字节流进行读取解析,进行两个大致的步骤,词法解析以及语法解析
- 插入式注解处理器
- 注解是一种应用字节码,可以对属性中类的元数据进行操作的一种编程机制
- 处理表形成后会自动检测是否有注解器需要执行,若有则执行注解处理器。注解处理器实现了在可插入式的编译期改变编译过程的功能。其本质就是再次修改处理表中的语法树。一旦语法树被修改,则将再次进行词法、语法分析并填充符号表的过程
- 语义分析并生成字节码
- 语义分析:再次对语法树中的节点进行校验,对数据类型以及控制逻辑进行检测
- 标量检测:检验关键字是否使用正确,类型转换是否正确等
- 数据与控制流分析:对控制流程的逻辑进行校验
- 语法糖解析:编程语言为了增加代码的可读性,以及减少编程出错率,提供了一些并不影响程序运行期仅在编译期有效的编程机制。java语言中语法糖有泛型、拆箱与装箱、foreach循环、可变参数、switch、枚举等,在编译期将转换为字节码遵守的规范形式。其中泛型使用类型擦出,拆装箱调用了valueOf与xxValue方法,foreach是迭代器可变参数是数组,switch本质是if else 的嵌套
- 字节码替换:在生成类的字节码之时,编译器会做一些默认性质的操作,当没有显示声明的构造器,则会创建默认的无参构造器,构造器分为实例构造器与类构造器。在字节码层面”类构造器”是指多个static代码块中的语句收敛生成的
指令。而"构造代码块"与"显示的构造器"将收敛生成实例构造器。同时还会将String类型的+与+=操作,默认替换为对StringBuffer或StrignBudiuer的操作 - 最后生成字节码
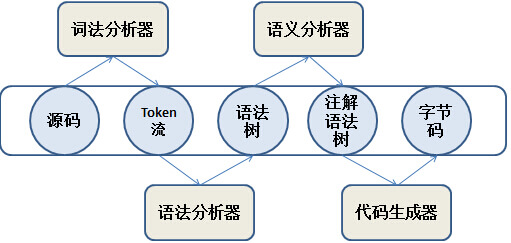
词法分析器
JavacParser规定哪些词是符合Java语言规范规定,而具体读取和归类不同的词法操作由Scanner完成,Token规定了完成Java语言的合法关健词,Names用来存储和表示解析后的词法
从源文件的第一个字符开始,按照Java语法规范依次出现packege、import、类定义,以及属性和方法定义等,最后构建一个抽象的语法树:
 词法分析器的分析结构就是将这个列中的所有关键词匹配到Token类中的所有项中的任何一项
词法分析器的分析结构就是将这个列中的所有关键词匹配到Token类中的所有项中的任何一项
语法分析器
语法分析器是将词法分析器分析的Token流建成更加结构化的语法树,Javac的语法树使得Java源码更加结构化,这种结构化可以为后面进一步处理提供方便。每个语法树上的节点都是com.sun.tools.javac.tree.JCTree的一个实例
关于语法规则是:
1、每一个语法节点都会实现一个接口xxxTree,这个接口继承自com.sun.source.tree.Tree接口
2、每个语法节点都是com.sun.tools.javac.tree.JCTree的子类,并且会实现第一节点中的xxxTree接口类,这个类的名称类似于JCxxx
3、所有的JCxxx类都作为一个静态内部类定义在JCTree类中
语义分析器
在语法树的基础上进一步处理,例如给类添加默认的构造器函数,检查变量在使用前是否已经初始化,将一些常量进行合并处理,检查操作变量类型是否匹配,检查所有的操作数据是否可达,检查checked exception异常是否已经捕获或者破除,解除Java语法糖等,将语法树转化为注解语法树
将在Java类中的符号输入到符号表中主要由com.sun.tools.javac.comp.Enter类来完成,这个类主要完成以下两个步骤:
1、将所有类中出现的符号输入到类自身的符号表中,所有类符号、类的参数类型符号、超类符号和继承的接口类型符号等都存储到一个未处理的列表中
2、将这个未处理列表中所有的类都解析到各自的类符号列表中,这个操作是在MemberEnter.complete()中完成
代码生成器
将注解语法树转化为字节码
参考:
第二章 Javac编译原理
javac命令的使用和运作原理
javap
前面使用过几次,先用javac -g Test.java生成所有的调试信息,包括局部变量名和行号信息,然后javap -verbose Test可以输出class文件结构(包含-c、-l)
- 常量池的存放内容
- 存放所有的方法名
- field名
- 方法签名(方法参数+返回值)
- 类型名
- class文件中的常量值
- 常量池的前四部分可以称作是符号引用(即只有一些名称,但没有实际的地址,在运行期进行类的加载过后,会为这些东西分配实际的内存,到时候符号引用就会转化为直接引用,就能被JVM用了)
- 常量池的组成:符号引用、常量(包含代码中定义的常量:字符串常量等,也包括class文件中的常量:SourceFile等)
- Stack:操作数栈的深度(类加载阶段为操作数栈分配的深度)
- Locals:局部变量的分配空间(单位是slot,不是个数),即对于double和long这两个64bit的需要两个slot,对于其他<=32bit的,只需要一个slot
- Args_size:方法参数的个数,包括方法参数、this(只针对实例方法,static方法不会自动添加this)
其源码可以在com.sun.tools.javap目录下找到
jad
下载后可以使用jad反编译class
使用jad.exe -sjava Test.class,反编译后生成对应的java文件:Parsing Test.class... Generating Test.java,其中-o允许直接覆盖掉以前存在的jad文件,-s允许改变输出文件的扩展类型,这里就将输出文件类型变成.java,-d可以指定另一个目录作为输出目录,例如jad -o -r -sjava -dsrc tree/**/*.class反编译了tree目录下所有.class文件,将输出文件以*.java的形式放到src目录下
我一般使用jd-gui反编译工具
即时编译器
Java是一门解释型语言(或者说是半编译,半解释型语言)。Java通过编译器javac先将源程序编译成与平台无关的Java字节码文件(.class),再由JVM解释执行字节码文件,从而做到平台无关。但是对字节码的解释执行过程实质为:JVM先将字节码翻译为对应的机器指令,然后执行机器指令。很显然这样经过解释执行,其执行速度必然不如直接执行二进制字节码文件
而为了提高执行速度,便引入了JIT技术。JIT是just in time的缩写,也就是即时编译。通过JIT技术,能够做到Java程序执行速度的加速。当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”编译成本地机器相关的机器码,并进行优化,然后再把编译后的机器码缓存起来,以备下次使用
HotSpot虚拟机中内置了两个JIT编译器:Client Complier(C1)和Server Complier(C2),分别用在客户端和服务端。可以使用“-client”或“-server”参数去强制指定虚拟机运行在Client模式或Server模式,用Client Complier获取更高的编译速度,它是一个简单快速的编译器,主要关注点在于局部优化,而放弃许多耗时较长的全局优化手段。用Server Complier来获取更好的编译质量,其是专门面向服务器端的,并为服务端的性能配置特别调整过的编译器,是一个充分优化过的高级编译器
大多数情况下,优化编译器其实只是选择合适的JVM以及为目标主机选择合适的编译器(-cient,-server 或是-xx:+TieredCompilation)。分层编译经常是长时运行应用程序的最佳选择,短暂应用程序则选择毫秒级性能的client编译器
热点检测
想要触发JIT编译,首先要识别出热点代码。目前主要的热点代码识别方式是热点探测(Hot Spot Detection),有以下两种:
1、基于采样方式探测(Sample Based Hot Spot Detection):周期性检测各个线程的栈顶,发现某个方法经常出现在栈顶,就认为是热点方法。好处就是简单,缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测
2、基于计数器的热点探测(Counter Based Hot Spot Detection):采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译
在HotSpot虚拟机中使用的是第二种 —— 基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器(记录一个方法被调用次数)和回边计数器(循环的运行次数)
编译优化
JIT除了具有缓存的功能外,还会对代码做各种优化,包括:逃逸分析、锁消除、锁膨胀、方法内联、空值检查消除、类型检测消除、公共子表达式消除等
Client Compiler模式
是一个简单快速的三段式编译器,主要关注点在于局部的优化,放弃了许多耗时较长的全局优化手段
1、第一阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representaion,HIR)。在此之前,编译器会在字节码上完成一部分基础优化,如方法内联,常量传播等优化
2、第二阶段,一个平台相关的后端从HIR中产生低级中间代码表示(Low-Level Intermediate Representation ,LIR),而在此之前会在HIR上完成另外一些优化,如空值检查消除,范围检查消除等,让HIR更为高效
3、第三阶段,在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在LIR上分配寄存器,做窥孔(Peephole)优化,然后产生机器码
Server Compiler模式
它是专门面向服务端的典型应用,并为服务端的性能配置特别调整过的编译器,也是一个充分优化过的高级编译器,几乎能达到GNU C++ 编译器使用-O2参数时的优化强度,它会执行所有的经典的优化动作,如无用代码消除(Dead Code Elimination)、循环展开(Loop Unrolling)、循环表达式外提(Loop Expression Hoisting)、消除公共子表达式(Common Subexpression Elimination)、常量传播(Constant Propagation)、基本块冲排序(Basic Block Reordering)等,还会实施一些与Java语言特性密切相关的优化技术,如范围检查消除(Range Check Elimination)、空值检查消除(Null Check Elimination ,不过并非所有的空值检查消除都是依赖编译器优化的,有一些是在代码运行过程中自动优化 了)等。另外,还可能根据解释器或Client Compiler提供的性能监控信息,进行一些不稳定的激进优化,如守护内联(Guarded Inlining)、分支频率预测(Branch Frequency Prediction)等
Server Compiler编译器可以充分利用某些处理器架构,如(RISC)上的大寄存器集合。从即时编译的角度来看,Server Compiler 无疑是比较缓慢的,但它的便以速度仍远远超过传统的静态优化编译器,而且它相对于Client Compiler编译输出的代码质量有所提高,可以减少本地代码的执行时间,从而抵消了额外的编译时间开销,所以也有很多非服务端的应用选择使用 Server 模式的虚拟机运行
扩展:
深入浅出 JIT 编译器
第六章 字节码执行方式–解释执行和JIT
JVM参数:-XX:ReservedCodeCacheSize