Java基础: JVM(一) JVM概述与字节码
Java基础: JVM(二) 常量池
Java基础: JVM(三) JVM执行引擎01
Java基础: JVM(四) Java栈帧
Java基础: JVM(五) JVM执行引擎02
Java基础: JVM(六) 类变量和类方法解析
Java基础: JVM(七) 类生命周期与类加载器
Java基础: JVM(八) 热加载
Java基础: JVM(九) Java内存模型
Java基础: JVM(十) 编译相关
类的生命周期
之前讲过解析字节码文件,主要包含3个主要过程:常量池解析、类字段解析、类方法解析。通过类字段解析,JVM能分析出Java类所封装的数据结构;通过类方法解析,JVM能分析出Java类所封装的算法逻辑;而无论数据信息还是方法信息,很多与字符串或较大的数据相关的信息都封装在常量池中,所以JVM要解析字段和方法信息,需要先解析常量池。这么些过程合起来,也仅仅属于Java类”加载”过程中的一个环节。按照JVM规范,一个Java文件从加载到被卸载的整个生命过程,总共经历5个阶段:加载 -> 链接(验证+准备+解析) -> 初始化(使用前准备) -> 使用 -> 卸载,由于第二阶段”链接”包含3个阶段,因此也可以认为Java类的生命周期一共包含7个阶段
加载阶段,简单讲就是将Java类字节码文件加载到机器内存中,并在内存中构建出Java类的原型 — 类模板对象。所谓类模板对象,其实就是Java类在JVM内存中的一个快照,JVM将从字节码文件中解析出来的常量池、类字段、类方法等信息存储到类模板中,这样JVM在运行期就能通过类模板获取Java类中的任何信息,能对Java类成员变量进行遍历,也能调用Java类方法。反射的机制就是基于这一基础,另外字节码相关的工具类库,例如asm、cglib等都是利用这个机制,在运行期动态修改静态声明的Java类所对应的字节码内容,从而在运行期直接改掉Java类的定义,甚至直接在运行期创建一个全新的Java类。综上所述,Java类是给我们看的,而JVM内存中的类模板快照则是给机器看的,所以需要通过类加载这个过程将字节码格式的Java转换为机器能够识别的内存类模板快照。在JDK 6时代,JVM内部为Java创建的对等类模板存储在perm区,在JDK 8时代,则存储在metaSpace区。当存储区即将满了且该类不再使用时,JVM的GC会对其回收,释放内存
JVM完成类的加载后,就会开始进行链接。链接的主要作用是将字节码指令中对常量池中的索引引用转换为直接引用。链接包含3个步骤:验证、准备、解析。其实在类加载阶段,JVM就会对字节码文件进行检验,不过这个阶段的检验着重于字节码文件格式本身,与链接阶段的侧重点不同。在链接阶段,验证着重于由字节码信息出发进行反向验证,例如根据字节码文件中的类名是否能找到对应的类模板。当验证通过后,就可以放心加载当前类,并将字节码指令中对常量池索引号的引用重写为直接引用
最后的初始化,并非指对类进行实例化,而是执行类的<clinit>()方法。在JVM完成类的初始化后,就可以等待开发者使用了,比如通过new关键字实例化一个Java类
类加载
字节码文件解析完成后,JVM在内部创建一个与Java类对等的模板,也是个C++类的实例。每一个Java类模型,最终在JVM内部都有一个klassOop与之对等,Java类中的字段、方法、常量池都会保存到klassOop实例对象中,这个实例对象仅仅用于表示Java类型本身或定义,并非实例对象。与Java实例对象对等的JVM内部对象是instanceOop实例
在ClassFileParser::parseClassFile()函数中,完成对常量池、字段、方法等的解析后,会完成klassOop的创建
klassOop ik = oopFactory::new_instanceKlass(
vtable_size, itable_size,
static_field_size, nonstatic_oop_map_size,
rt, CHECK_(nullHandle));
instanceKlassHandle this_klass (THREAD, ik);
// Fill in information already parsed
// ...
instanceKlass内部定义了若干字段,这些字段足以存储Java类规范所支持的一切信息,例如字段、方法、内部类等,因为instanceKlass要作为Java在JVM内部对等的结构体,因此能兼容Java类中所有元素是其唯一的设计目标。JVM在创建instanceKlass对象时,会为其申请超过本身所需内存大小的空间,因为JVM需要在其内存空间末尾预留出足够的空间,存储虚方法表vtable、接口表itable、静态类型static fields、Java类中引用类型表oopMap。在JDK 6中,静态字段会分配到instanceKlass实例对象所申请的空间,而JDK 7以后,静态字段会被分配到与instanceKlass对等的镜像类java.lang.Class实例中
类加载的最终结果就是在JVM方法区创建一个与Java类对等的instanceKlass实例对象,而JVM在创建完instanceKlass后,又创建了一个与之对等的镜像类 — java.lang.Class。在JDK6中,创建镜像类的逻辑在instanceKlassKlass::allocate_instance_klass()函数中,在该函数末尾调用java_lang_Class::create_mirror()调用。所谓的镜像类,其实也是instanceKlass的一个实例对象,JVM故意再创建一个镜像类,是为了将java.lang.Class暴露给Java程序调用,而instanceKlass则是为了被JVM内部访问,像反射就是基于java.lang.Class这个内部镜像实现的
Java主类加载机制
虚拟机在得到一个Java class文件流后,接下来完成主要步骤为:
1、读取魔数与版本号
2、解析常量池,parse_constant_pool()
3、解析字段信息,parse_fields()
4、解析方法,parse_methods()
5、创建与Java类对等的内部对象instanceKlass,new_instanceKlass()
6、创建Java镜像类,create_mirror()
这样就完成了一个Java类加载的核心流程,那么Java类的加载何时被触发呢?Java类加载的触发条件比较多,其中比较特殊的就是Java程序中包含main()主函数的类,这种类一般被称为Java程序的主类,主类的加载由JVM自动触发,JVM执行完自身的若干初始化逻辑后,第一个加载的便是Java程序的主类
java程序main主类加载的调用链路核心逻辑为:
1、JVM启动后,操作系统会调用java.c::main()主函数,从而进入JVM的世界。然后调用java.c::JavaMain()方法,其主要执行JVM的初始化逻辑,初始化完毕后便会搜索Java程序的main()主函数所在的类,即主类,找到主类类名后,会调用mainClass = LoadClass(env, classname)对主类进行加载
2、java.c::LoadClass()方法将会执行cls = (*env)->FindClass(env,buf)来寻找主类
3、首先跳转到jni.cpp::JNI_ENTRY(jclass, jni_FindClass(JNIEnv *env,const char *name)),其中JNI_ENTRY是宏,在预编译阶段就已展开,(*env)->FindClass(env,buf)最终会调用jni.cpp::jni_FindClass(JNIEnv *env,const char *name)函数,会先调用loader = Handle(THREAD, SystemDictionary::java_system_loader())获取类加载器。Java程序主类的类加载器默认是系统加载器,即JDK类库中定义的sun.misc.AppClassLoader。系统加载器的顶级父类是java.lang.ClassLoader,是JDK类库提供的核心加载器。实际上无论Java程序内部有无自定义类加载器,最终都会调用java.lang.ClassLoader提供的几个native接口完成类的加载。因此获取到系统加载器后会调用find_class_from_class_loader()接口加载主类,其中会调用SystemDictionary::resolve_or_fail()接口
4、SystemDictionary::resolve_or_fail()接口经过一系列调用,最终调用SystemDictionary::resolve_instance_class_or_null()接口,经过层层判断,确认同一个加载器没有别的线程在加载同一个类,则最终会执行真正的加载,调用SystemDictionary::load_instance_class()接口
5、内部调用JavaCalls::call_virtual()接口,会根据输入参数调用指定的Java类中的指定方法,即最终调用AppClassLoader.loadClass(String)这个方法,JVM流程便转移到了Java类的逻辑流之中
5“、JavaCalls::call_virtual()接口最终会调用到JavaCalls::call()接口,其中调用JavaCalls::call_hepler(),接而内部调用StubRoutines::call_stub()例程。因此JavaCalls类就是实现JVM从C/C++程序调用到Java类方法的实现机制,该类中定义了许多call_*()接口,最终都会调用到StubRoutines::call_stub()例程,从而辅佐JVM执行Java方法,JavaCalls::call_virtual()接口在JVM内部是很常用的接口,大凡涉及Java类成员方法的调用,最终都会经过这个接口
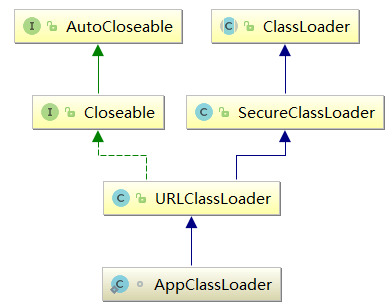
6、经过上面的步骤,最终就是调用AppClassLoader.loadClass(String)接口加载Java应用程序的主类,由于继承自java.lang.ClassLoader这个基类,最终调用的是AppClassLoader.loadClass(String, boolean)方法,首先会判断是否加载过指定的类,然后判断加载器parent是否为null,并通过父类加载器加载指定Java类。AppClassLoader父类加载器是ExtClassLoader扩展类加载器,用于加载JDK指定路径下的扩展类,不会加载Java应用程序的主类,所以最终通过自己来加载。AppClassLoader继承自URLClassLoader,因此最终会调用java.lang.ClassLoader.defineClass1()这个natvie接口,由本地库实现,对应的本地实现是ClassLoader.c::Java_java_lang_ClassLoader_defineClass1(),这样Java程序流又转移到JVM内部,最终经过一步步来到ClassFileParser.cpp::parseClassFile()这个函数来解析Java主类,并最终创建Java主类在JVM内部的对等体klassInstance,由此完成对Java主类的加载
MyClassLoader mcl = new MyClassLoader();
Class klass = mcl.loadClass("com.test.Test");
Test t = (Test)klass.newInstance();
体现Java语言强大生命力和魅力的关键因素之一,就是开发者可以自定义类加载器来实现类库的动态加载,加载源可以是本地JAR包,也可以是网络远程资源。例如著名的OSGI组件框架、Eclipse插件机制。类加载器为应用程序提供了动态增加新功能的机制,这种机制无需重新打包发布应用程序就能实现。除外,自定义加载器能实现应用隔离,例如tomcat、spring等中间件和组件框架都在内部实现了自定义加载器,并通过自定义加载器隔离不同的组件模块。而无论多么复杂的自定义类加载器,最终还是调用java.lang.ClassLoader.defineClass*()系列本地接口,而最终也仍然由JVM内部的本地实现来完成实际的加载工作,即还是最终调用ClassFileParser.cpp:parseClassFile()完成Java类解析,并创建内部对应的klassInstance实例,将Java类从字节码文件格式完全转换成内存格式
反射加载机制
除了通过类加载器完成类的加载,还可以通过java.lang.Class.forName(String)反射接口完成类加载,不过该接口不仅完成类加载,还包含了验证、准备、解析和初始化阶段
java.lang.Class.forName(String)最终会调用private static native Class<?> forName0()这个本地接口完成类加载,本地接口调用jvm.cpp:JVM_FindClassFromClassLoader(),然后类似的最后从JVM内部发起对java.lang.ClassLoader.loadClass(String)接口的调用,完成类的加载
import
在写代码的时候,如果想用某个类,会先import进来,但是Java字节码指令和编译后的class字节码文件中,并没有import关键字的解释,实际上import只是语法糖,没有任何关联的运行时行为,也不会导致类加载,仅仅是方便写代码,省略了一串长长的全限定名。而Java类的加载使用了“延迟加载”机制,仅在第一次被使用时才会发生真正的加载,而与是否使用了import关键字无关
虽然import语句没有对应指令,也不导致类加载,但是import引入进来的包名会被写入java class文件的常量池中,作为字符串存储起来,以用于类加载时的验证和解析。至于import进来的类什么时候加载,会有好几种情况,比如使用new关键字、读写类的静态变量、反射加载等
比如使用new指令加载类时,如果一个类尚未被加载过或从未被链接过,则会进入慢分配流程。会获取new指令对应的Java类模板后,最终调用constantPoolOopDesc::klass_at_impl()函数,其中如果是应用程序第一次使用这个类,且这个类尚未被加载进JVM内部,就获取类加载器,同样最终通过java.lang.ClassLoader.loadClass(String)这个接口去执行类加载
类加载器
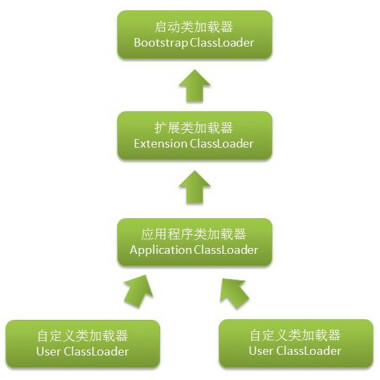
Java体系中定义了3种类加载器,分别为:
1、Bootstrap ClassLoader(引导类加载器),加载指定的JDK核心类库,无法由Java应用程序引用。负责加载下面3种情况下指定的核心类库:
1-1、%JAVA_HOME%/jre/lib目录
1-2、-Xbootclasspath参数指定目录
1=3、系统属性sun.boot.class.path指定目录中特定名称的jar包
2、Extension ClassLoader(扩展类加载器),加载扩展类,拓展JVM的类库,负责加载下面2种情况下指定的类库:
2-1、%JAVA_HOME%/jre/lib/ext目录
2-2、系统属性java.ext.dirs指定目录中所有的类库
3、SystemClassLoader(系统加载器),加载Java应用程序类库,加载类库的路径有下面3种情况:
3-1、环境变量ClassPath指定路径
3-2、-cp指定路径
3-3、系统属性java.class.path指定路径
除了3种加载器外,Java还支持自定义加载器。自定义加载器大大丰富了Java中间件,在许多Java框架和组件中得到极其广泛的应用
从使用者的角度看,虽然JVM提供了多种类加载器,并且可以自定义许多加载器,但是站在程序的角度看,其实Java体系一共只定义了2种类加载器:一种使用C++语言定义,另一种使用Java语言定义
C++定义的类加载器,其实就是Bootstrap ClassLoader,即引导类加载器。该加载器内部的所有字段和函数都是static修饰的,因此不需要被实例化,当需要加载Java类时,直接调用静态函数。该加载器提供了setup_bootstrap_search_path()接口用于设置加载器所需要搜索的类路径,同时提供了重要的方法load_classfile()来加载指定的Java类。这个接口里直接调用了我们熟悉的ClassFileParser::parseClassFile()接口来完成解析和加载Java类。虽然并不是所有的Java虚拟机都使用C++专门定义一个类加载器,有些JVM也使用Java来定义引导类加载器,但是其实现仍然需要依赖JVM内部所提供的的本地接口。无论如何,最终的目的依旧是在JVM内部创建一个与Java类完全对等的结构体
对于Java语言定义的类加载器,便是JDK核心类库中java.lang.ClassLoader类。无论是扩展类加载器、系统加载器还是自定义加载器,都是继承自java.lang.ClassLoader。它提供了绝大多数类加载功能,同时提供了最重要的define*系列的native接口,其实也就是绕个弯子,通过native接口,间接调用ClassFileParser::parseClassFile()接口完成加载
这里表达的仅仅是类的委托加载机制,尤其是”双亲委派”机制,而不是继承关系,因为引导类加载器是C++写的,而后面的都是继承自ClassLoader基类的
 这种委托加载的关系,本质上通过java.lang.ClassLoader.parent字段实现,表示父加载器。当然对于引导类加载器,并没有父加载器概念,它是随JVM的启动而初始化的且都是静态字段和方法的,它提供了
这种委托加载的关系,本质上通过java.lang.ClassLoader.parent字段实现,表示父加载器。当然对于引导类加载器,并没有父加载器概念,它是随JVM的启动而初始化的且都是静态字段和方法的,它提供了initialize()接口,因此会在JVM的init()初始化调用链路中被调用,该接口读取引导类路径,定位到相关jar文件,为加载核心类库做准备。除此之外的所有类加载器,都拥有parent字段,且被final private修饰,因此只能通过调用ClassLoader的构造函数才能初始化该字段。对于扩展类和系统类加载器,在JVM第一次加载Java类时会被创建,并完成其父加载器的设定,它们在sun.misc.Launcher类的构造函数中完成初始化
public Launcher() {
Launcher.ExtClassLoader var1;
try {
// 会先获取扩展类加载器加载路径,然后通过new来实例化
var1 = Launcher.ExtClassLoader.getExtClassLoader();
} catch (IOException var10) {
throw new InternalError("Could not create extension class loader", var10);
}
try {
// 扩展类加载器被设为系统类加载器的parent
this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
} catch (IOException var9) {
throw new InternalError("Could not create application class loader", var9);
}
Thread.currentThread().setContextClassLoader(this.loader);
String var2 = System.getProperty("java.security.manager");
if(var2 != null) {
SecurityManager var3 = null;
if(!"".equals(var2) && !"default".equals(var2)) {
try {
var3 = (SecurityManager)this.loader.loadClass(var2).newInstance();
} catch (IllegalAccessException var5) {
;
} catch (InstantiationException var6) {
;
} catch (ClassNotFoundException var7) {
;
} catch (ClassCastException var8) {
;
}
} else {
var3 = new SecurityManager();
}
if(var3 == null) {
throw new InternalError("Could not create SecurityManager: " + var2);
}
System.setSecurityManager(var3);
}
}
在JVM加载主类的链路中,前面说过,会调用loader = Handle(THREAD, SystemDictionary::java_system_loader())来获取类加载器,sun.misc.Launcher类的实例就在SystemDictionary::java_system_loader()链路里创建,最终会通过调用ClassLoader类的静态方法getSystemClassLoader()来获取类加载器,最终JVM将使用这个加载器去加载Java程序中的主类。而在getSystemClassLoader()函数中通过调用initSystemClassLoader()接口初始化系统类加载器
private static synchronized void initSystemClassLoader() {
if (!sclSet) {
if (scl != null)
throw new IllegalStateException("recursive invocation");
// ---->
sun.misc.Launcher l = sun.misc.Launcher.getLauncher();
if (l != null) {
Throwable oops = null;
scl = l.getClassLoader();
try {
scl = AccessController.doPrivileged(
new SystemClassLoaderAction(scl));
} catch (PrivilegedActionException pae) {
oops = pae.getCause();
if (oops instanceof InvocationTargetException) {
oops = oops.getCause();
}
}
if (oops != null) {
if (oops instanceof Error) {
throw (Error) oops;
} else {
// wrap the exception
throw new Error(oops);
}
}
}
sclSet = true;
}
}
// 直接返回静态变量,系统加载器和扩展类加载器都是在Launcher类构造函数中被创建的
public class Launcher {
private static Launcher launcher = new Launcher();
public static Launcher getLauncher() {
return launcher;
}
// ...
}
双亲委派
JVM中的双亲委派机制,在java.lang.ClassLoader.loadClass(String, boolean)接口中,主要逻辑为:
1、先在当前加载器的缓存中查找有无目标类,有则直接返回
2、判断当前加载器的父加载器是否为空,若不为空,则调用parent.loadClass(name, false)接口进行加载
3、如果父加载器为空,则调用findBootstrapClassOrNull(name)接口,让引导类加载器进行加载
4、如果上面3条路径都没有成功,则调用findClass(name)接口进行加载,该接口最终调用ClassLoader的define*系列的native接口加载目标Java类
双亲委派机制就在第2和第3步中,从本质上讲,其实就是规定了类加载的顺序是:引导类加载器先加载,加载不到由扩展类加载器加载,若也加载不到由系统类加载器或自定义的类加载器去加载。这种机制保证了核心类库一定由引导类加载器加载,且不会被多种加载器加载
那么如果在自定义的类加载器中重写loadClass方法,抹去双亲加载的委派机制,仅保留第1和第4步,是不是就能加载核心类库了呢?其实依旧不行,因为JDK为核心类库提供了一层保护措施,无论是自定义的类加载器,还是系统类加载器或扩展类加载器,最终都必须调用java.lang.ClassLoader.defineClass(String,byte[],int,int,ProtectionDomain)方法,而该方法会执行preDefineClass()接口,该接口提供了对JDK核心类库的保护:
private ProtectionDomain preDefineClass(String name,
ProtectionDomain pd) {
if (!checkName(name))
throw new NoClassDefFoundError("IllegalName: " + name);
// Note: Checking logic in java.lang.invoke.MemberName.checkForTypeAlias
// relies on the fact that spoofing is impossible if a class has a name
// of the form "java.*"
// 如果要加载的目标类全限名以java.开头,直接抛出异常
if ((name != null) && name.startsWith("java.")) {
throw new SecurityException
("Prohibited package name: " +
name.substring(0, name.lastIndexOf('.')));
}
if (pd == null) {
pd = defaultDomain;
}
if (name != null) checkCerts(name, pd.getCodeSource());
return pd;
}
系统类加载器的父加载器是扩展类加载器,而扩展类加载器和引导类加载器的父加载器都是null,这是JVM中固化下来的关系设定。默认情况下,Java应用的类加载器是系统类加载器。如果要自定义类加载器,那么只能继承ClassLoader或其子类,并且自定义的类加载器的父加载器都是系统类加载器,这是因为ClassLoader的默认构造函数会将getSystemClassLoader()返回结果作为自定义类加载器的父加载器,而这返回的正是系统类加载器
protected ClassLoader() {
// Launcher$AppClassLoader
this(checkCreateClassLoader(), getSystemClassLoader());
}
扩展:
破坏双亲委派机制的那些事
真正理解线程上下文类加载器(多案例分析)
预加载
JVM启动期间,会先加载一部分核心类库,平时最常用的基础类库,比如Object、String、Thread等都在这里,因为这些类使用频率很高,因此预先将它们加载到内存
JDK核心类库随JVM启动而进行预加载的链路为:
java.c::main()
java_md.c::LoadJavaVM()
jni.cpp::JNI_CreateJavaVM()
Threads::create_vm()
init.cpp::init_globals()
Universe.cpp::universe2_init()
Universe::genesis()
SystemDictionary::initialize()
SystemDictionary::initialize_preloaded_classes()
// 遍历WK_KLASSES_DO宏中定义的全部预加载类,逐个加载
SystemDictionary::initialize_wk_klasses_until()
在initialize_wk_klasses_until()内会调用initialize_wk_klass()函数进行逐个类加载,最终会调用到SystemDictionary::resolve_or_fail()接口去加载核心类库,和JVM加载Java主类时一样,链路经过这里后一路调用,最终到SystemDictionary::load_instance_class()函数,里面体现出双亲委托机制,而核心类库没有类加载器概念,因此在if逻辑块中JVM调用内部的引导类加载器来加载核心类库。而像加载Java主类时,就会在else逻辑块中通过JavaCalls::call_virtual()接口加载类,这个接口最终会通过java.lang.ClassLoader.loadClass(String)接口执行类的加载,这就是JVM内部的双亲委派机制:一边是直接使用引导类加载器(不经过ClassLoader.loadClass(String)接口),一边则是使用系统类加载器(对Launcher类初始化后,获取到ClassLoader类的实例,调用静态方法getSystemClassLoader()来初始化系统类加载器和扩展类加载器)
引导类加载
JVM使用双亲委派机制加载类,如果所加载的类属于JDK核心类库中定义的类,则在java.lang.ClassLoader.loadClass(String, boolean)中进入findBootstrapClassOrNull()方法,通过引导类加载核心类库,该方法最终会调用private native Class<?> findBootstrapClass(String name)这个本地接口执行核心类库的加载,这个本地接口最终会通过调用引导类加载器执行加载
在JNI实现中,调用JVM_FindClassFromBootLoader()来加载核心类库,最终也会调用到SystemDictionary::load_instance_class()函数中,这个函数无论是JVM启动期间预加载部分核心类库还是JVM加载Java应用程序主类,只要涉及类加载都会经过这里,内部通过双亲委派机制进行加载,即class_loader为空,直接调用引导类加载器的ClassLoader::load_classfile()接口进行类加载,否则通过制定的Java类加载器去加载。那么对于核心类库,类加载器为空,因此最终通过引导类加载器进行加载
加载、链接和延迟加载
JVM在启动时会预加载一部分核心类库,但是虽然完成类的加载,由于尚未在应用程序中使用到,因此并未经过链接,因此当在代码使用new字节码指令时,在其流程中进行慢分配流程
由于类加载只是在类生命周期中的第一步,后面还有链接和初始化。在链接阶段,字节码指令会被重写,将其所引用的常量池的索引号转换为直接引用。例如在实例化一个类时,编译后生成的字节码指令为new #2,后面跟着的是常量池中索引号为2的元素,该元素一定指向某个Java类的全限定名,如果是实例化Long,则常量池2号索引指向的字符串一定是class java/lang/Long。在Java类经过编译后得到的字节码文件中的原始常量池中,class java/lang/Long并不是存放于常量池的一个元素中,而是分开存放于好几个元素中,例如class本身是常量池中的一个固定类型,而java/lang/Long在常量池中则是一种字符串类型。比方说在JVM加载完测试类Test后,会对其字节码进行重写,重写后new字节码指令,后面跟随的便是直接指向java/lang/Long这个字符串的内存地址,这个重写便是整个Java类生命周期中”链接”阶段所做的最重要的事情。在重写的过程中,可以认为是做了一次缓存优化,通过重写,避免运行期再去将多个不同常量池元素一步步拼接出new指令实际要指向的类型
等到JVM真正运行到new这个字节码指令时,JVM为了加快指令执行速度,又做了一次缓存。先来看在new实例化一个Java类型时,JVM必须知道说实例化的类型,这在链接阶段已经完成了,通过字节码指令重写JVM知道了实例化的Java类的全限定名。之后JVM根据全限定名在perm区(JDK8的metaSpace区)定位到这个Java类在内存中的对等体 — instanceKlass,这样能根据这个类模板创建出Java类实例对象。在JVM执行new指令对应的实例对象创建过程之前,一定先完成了类的加载、链接和初始化,instanceKlass就是在类加载阶段完成创建的,因此JVM根据全限定名一定能找到这个instanceKlass。然而每次执行new指令都需要根据全限定名去定位instanceKlass这个内存对象是在做重复的事情,因此JVM会在第一次执行new指令时将定位到的instanceKlass缓存起来,这样下次再实例化同样的Java类对象时,就直接从缓存中读取instanceKlass,提升效率
那么在使用new指令加载尚未被加载或链接过的类时,慢分配流程从而进入InterpreterRuntime::_new()函数,其中会调用constantPool->klass_at()接口来获取new指令后面的Java类模板,该接口最终调用constantPoolOopDesc::klass_at_impl()函数,其主要思路是先从缓存中读取Java类模板,如果读取不到,则执行类加载,加载后将类模板写入缓存,最终仍然从缓存中读取类模板并返回。那么假如new一个Long类型变量,由于在JVM启动期间已经被预加载,因此最终通过java.lang.ClassLoader.findBootstrapClassOrNull()接口调用引导类加载器去加载核心类库时,JVM内部并未真的重新将java.lang.Long重新加载一遍,而是直接从缓存中获取。当第一次实例化后,java.lang.Long这个类模板已经完成解析,所以之后再次实例化时,JVM会尝试走“快速分配”流程进行无锁分配,如果该类不满足快速分配的条件(比如类太大),虽然仍然进入慢分配流程,但是由于解析过,因此不会再经历类加载过程。事实上,除了JDK核心类库中被预加载的类执行new实例化时,JVM没有重复加载类,对于所有的Java类的实例化都是如此。因此从更广义的角度看,这也体现了类的延迟加载机制:一个类,只有当真正被调用时才会被加载,即使程序中import了某个类,但是如果不使用,JVM在整个运行期都不会加载它。甚至即使在程序中使用了某个类,但是如果条件一直不符合,导致JVM一直没有进入使用它的分支流程中,则JVM也自始至终不会加载这个类。延迟加载机制避免了系统的无谓开销
加载器与类型转换
每个Java类都必须有一个类加载器,一般情况下,使用不同的类加载器去加载不同的功能模块,会提高应用程序的安全性。但是如果涉及Java类型转换,那么加载器反而容易发生异常。例如使用自定义加载器和默认的系统类加载器加载同样的Java类并进行强转,会抛出ClassCastException异常。这就是因为它们的类加载器并不是同一个,比如Spring等许多中间件都有自定义的类加载器,因此会遇到这种被自定义加载器加载的类型,无法直接转换为使用默认加载器加载的类型,而导致抛出ClassCastException异常的现象
JVM及Dalvik对类唯一的识别是ClassLoader id + PackageName + ClassName,所以一个运行程序中是有可能存在两个包名和类名完全一致的类的。并且如果这两个”类”不是由一个ClassLoader加载,是无法将一个类的示例强转为另外一个类的,这就是ClassLoader隔离
类链接
扩展:
Java 深度历险(二)——Java类的加载、链接和初始化
类加载和字节码执行引擎
类初始化
完成类的加载、链接后,便会进入类的初始化阶段。所谓初始化,其实就是调用Java类的<clinit>方法,这个方法只能在JVM运行期调用,过程便是Java类的初始化。JVM规范规定,当遇到new、getstatic、invokestatic等字节码指令或加载Java应用程序主类等一些情况下,会执行类的初始化逻辑
例如使用new关键字实例化一个Java类,前面说过,如果是第一次使用,必然会执行加载、链接、初始化逻辑,因此在通过慢分配流程时,会调用到instanceKlass::call_class_initializer()函数,其中会先获取<clinit>函数对应的method对象,接着通过JavaCalls::call()接口执行初始化方法来完成类的初始化。如果Java类中没有定义任何静态字段,也没有static静态块,那么不会有<clinit>方法,也就不会执行逻辑,跳过
注意:每一个类都有一个加载器,并且不同加载器加载的同一个类无法相互转换,也就是如果分别通过2个不同的类加载器去加载同一个类,那么该类必定先后被加载两次,同理,该类的初始化逻辑也会被执行两次
类实例分配
Java是面向对象的,数据和行为都封装在类中,因此想要读写数据或执行某些行为都需要先实例化Java类。实例化Java类的方式有很多,比如调用Class.newInstance()或直接使用new关键字。其中new的实现机制非常精彩,对内存、线程并发控制等都达到登峰造极的地步,利用了软件和硬件所能利用的一切优化手段。并且实例化涉及内存分配,而内存分配又与垃圾收集器紧密耦合在一块,因此这部分的技术实现是精华。相比较执行引擎中对硬件指令的封装、运行期多层动态编译和指令实时优化的精微和深奥,内存分配则显得相对简单,为了性能和内存开销用尽一切谋略,只要有用拿来即用
Hotspot提供了new字节码指令的机器码实现,也保留了字节码解释器的实现,相对来说两者实现逻辑大致一致,因此从字节码解释器的逻辑可以了解实例化的机制。这段逻辑从宏观上分为两部分,一部分是快速分配,另一部分则是慢分配。如果所要new的Java类型尚未被解析过(即已经被加载也不算),则直接进入慢分配,这边是之前说到的延迟加载的基础所在。快速分配的流程则比较复杂,相比慢分配则是直接调用InterpreterRuntime::_new()接口。为了尽可能快地加快内存分配速度,并减少并发操作带来的性能损失,JVM在分配内存时,总是优先使用快速分配策略,当快速分配失败时,才会启用慢分配策略。这段逻辑可以大致分为6点:
1、如果Java类尚未被解析,则直接进入慢分配,不会使用快速分配策略
2、快速分配时,如果没有开启栈上分配或不符合条件,则会进行TLAB分配
3、快速分配时,如果TLAB分配不成功,则尝试在eden区分配
4、如果eden区分配失败,那么则进入慢分配流程
5、如果对象满足了直接进入老年代的条件,那就直接分配在老年代
6、快速分配时,对于热点代码,如果开启逃逸分析,JVM则会执行栈上分配或标量替换等优化方案
栈上分配和逃逸分析
之前说JVM的JIT即时编译器时说过逃逸分析。其中即时编译是一种通过在运行时将字节码翻译为机器码,从而改善字节码编译语言性能的技术。在Hotspot中有多种实现:C1、C2和C1+C2,分别对应Client、Server和分层编译。而所谓逃逸分析,是指一个在方法内部被创建的对象不仅被方法内部引用,还在方法外部被其他变量引用,那么方法执行完毕后该方法创建的对象无法被GC回收,这就是逃逸,而JVM进行的逃逸分析是确定方法内部创建的对象会不会逃逸出方法体外部,如果确定不会逃逸出去,那么就能对该对象采用多种优化措施,这些优化措施主要围绕两大方向:内存分配和线程同步
逃逸分析的算法主要基于连通图,通过引入连通图来构建对象和对象引用之间的可达性关系,并在此基础上,提出一种组合数据流分析法。该算法是上下文相关和流敏感的,同时模拟了对象任意层次的嵌套关系,所以运行时间比较长,内存消耗比较大,但是分析精度比较高。然而其并不能确保百分百的准确性,因为Java语言的许多动态特性,比如动态生成字节码、调用本地函数、反射、方法拦截等都会导致逃逸分析的算法不能作为编译期间的静态优化措施,而只能基于运行时动态分析,这就是逃逸分析要感知运行时的上下文和程序流的原因。由于逃逸分析是运行期进行的,因此很耗费内存和CPU资源,这样JVM不可能对每一个方法里的变量进行逃逸分析,所以只能作为JIT的一项优化措施,即只有JVM触发JIT编译时才进行逃逸分析,所以前面在BytecodeInterpreter::run()函数中没有相关实现的原因。在逃逸分析完成后,JIT编译器会基于结果直接基于Java字节码指令,生成优化后的本地机器码指令,所生成的本地机器码指令会将Java对象分配在栈甚至硬件寄存器中。这些优化的本地机器码已经看不到Java的new字节码指令了,这也是不能在Java的new字节码指令的直接实现上看到栈上分配的原因
JIT基于逃逸分析结果,采取不同的策略,为对象实例分配内存。目前主要的优化技术包括标量替换和栈上分配,这两种优化技术都不会讲对象实例直接分配在堆上
栈上分配依赖逃逸分析和标量替换来实现
标量替换
所谓标量,就是指不可分割的量,Java中的基本数据类型和reference类型都属于标量,其中reference类型在JVM内部就是一个指针,因此也属于不可分割的量。如果一个数据类型可以继续分解,则称为聚合量。如果将一个对象拆散,将成员变量恢复到基本类型可以用于访问,这个过程就叫做标量替换。由此可知标量替换在替换后海要修改类型字段的读写指令,如果标量替换比较激进,还会直接将一个类的所有字段都打散分配到硬件的寄存器中,当然前提是这个类型中包含的字段不能太多,毕竟寄存器是数量有限的
栈上分配
如果一个类实例引用变量没有发生逃逸,则将该实例对象直接分配在方法栈上,在栈上分配的对象实例会随着方法结束后方法栈空间的回收而被回收,因此不需要GC回收。然而栈上分配要求Java类型不能太大,包含的字段不能太多,毕竟堆栈空间是有限的,容纳不下几个大型的Java类,正因为有这个限制,JVM才会建立所谓的堆空间
逃逸分析的算法比较复杂,而且与本地机器指令相关。不过逃逸分析和基于此所进行的内存分配优化可以通过jmap -histo命令观察开启和关闭逃逸分析选项后实例的总数进行验证
TLAB
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域,TLAB的出现能解决直接在堆上安全分配带来的线程同步性能消耗问题。堆内存是全局的,任何线程都能在堆上申请空间,因此每次申请堆内存空间时都必须进行同步处理,如果许多线程同时在堆上申请内存,竞争会十分激烈,必然出现线程阻塞。而TLAB是线程私有的一块内存空间,这块空间位于eden区,各个线程的TLAB区域彼此不重复,因此线程在各自的TLAB内存区域申请空间,无需加载,这样内存申请效率便会得到极大的提升,则就是一种典型的空间换时间的策略。使用参数-XX:+UseTLAB可以开启TLAB,默认就是开启的,TLAB的内存空间非常小,默认下仅占整个eden空间的1%,每个线程能拥有的TLAB非常小,因此JVM必然会限制Java类对象实例的大小,如果超过阈值,属于大对象,JVM就将大对象直接分配在堆上,不再分配到TLAB区
在BytecodeInterpreter::run()函数中通过直接调用THREAD->tlab().allocate(obj_size)来完成TLAB的内存分配,tlab实际上是JVM内部Thread类的一个成员变量,其类型是ThreadLocalAllocBuffer,该类内部主要通过3个字段维护TLAB区域的范围,分别为_stat首地址,_top最近一次TLAB分配内存后指向的地址,_end终止位置(内存对齐后的位置),通过这3个变量TLAB便能完成内存的申请与释放
只要TLAB剩余空间足够容纳一些小的Java类对象实例,那么就重置TLAB的top属性完成内存分配,否则JVM便会向eden区申请内存空间。如果TLAB区域都用完了,由于其本身位于eden区,因此当eden区也快用完时,会触发GC垃圾回收,这样TLAB的内存空间会随着eden区的回收一起被回收掉,实现TLAB的循环利用
指针碰撞与eden区分配
如果JVM向TLAB申请内存失败,则转而向eden区申请内存,这个过程中使用了bump-the-pointer技术,也就是指针碰撞,其实现逻辑为:
// Universe::heap()返回JVM内部使用的CollectedHeap堆对象,top_addr()指向eden区空闲块的起始地址
HeapWord* compare_to = *Universe::heap()->top_addr();
HeapWord* new_top = compare_to + obj_size;
// end_addr()指向eden区空闲块的结束地址
if (new_top <= *Universe::heap()->end_addr()) {
if (Atomic::cmpxchg_ptr(new_top, Universe::heap()->top_addr(), compare_to) != compare_to) {
goto retry;
}
result = (oop) compare_to;
}
指针碰撞技术的关键是CAS操作,这里通过基于CPU硬件的CAS原子指令进行空闲块的同步操作,比较_top的预期值与compare_to是否相等,而指针碰撞的关键就是CAS原语,JVM通过CAS避免了多线程之间的锁竞争,这是实现内存快速分配的技术保障
清零
之前的两个快速分配策略如果有一个能成功,那么Java类的实例对象会被分配在TLAB区或eden区(其实都在eden区),同时也会不停被GC,因此Java对象实例所分配到的内存空间很可能仍然残留着已经被回收的或被转移到其他堆内存区域的对象的信息片段,这时就需要对这段空间进行清零
// ...
// If the TLAB isn't pre-zeroed then we'll have to do it
bool need_zero = !ZeroTLAB;
if (result == NULL) {
need_zero = true;
// Try allocate in shared eden
// ...
}
if (result != NULL) {
// Initialize object (if nonzero size and need) and then the header
if (need_zero ) {
HeapWord* to_zero = (HeapWord*) result + sizeof(oopDesc) / oopSize;
obj_size -= sizeof(oopDesc) / oopSize;
if (obj_size > 0 ) {
memset(to_zero, 0, obj_size * HeapWordSize);
}
}
// ...
}
对于need_zero,如果在TLAB区中分配成功,并且TLAB区本身已清零,则表达式返回false。如果TLAB区申请失败后通过eden分配成功,那么最终都需要清零。而清零就是将制定的内除区域全部设为0即可,所有的二进制位都是0
偏向锁
如果快速分配策略成功并完成清零,接着就会设置偏向锁。设置偏向锁其实就是设置对象头,即oop的mark标记。
if (UseBiasedLocking) {
result->set_mark(ik->prototype_header());
} else {
result->set_mark(markOopDesc::prototype());
}
这里设置prototype的类型便是mark,每个Java类实例都有一个mark标记,mark看起来像一个C++对象,实际被JVM内部当做一个指针使用的,在32位平台指针是个32位的正整数,64位平台下是个64位的正整数。JVM会将Java类对象的GC分代年龄、哈希码、锁标志等信息存储在一个mark上,其实就是二进制打标。即如果JVM开启偏向锁,则将ik->prototype_header()设置为新创建的Java类实例对象的标记,其返回的标记中的偏向锁,其指向当前线程ID,而当前线程便是正在执行new指令、并在创建Java类实例的线程,因此通过result->set_mark(ik->prototype_header())便将该新创建的对象的偏向锁偏向于当前创建它的线程,如果在接下来的执行过程中,该锁没有被其他线程获取,则偏向锁的线程将永远不会再进行同步
而如果没有开启偏向锁,则将markOopDesc::prototype()设置为新创建的Java类实例对象的标记,其返回一个没有哈希码、没有偏向锁的标记
压栈与取值
在快速分配流程将偏向锁设置后,Java类实例对象的内存空间就已经分配完成,接着JVM将Java对象实例的内存首地址压入操作数栈栈顶,完成压栈后则开始取指,读取下一条字节码指令
// 压栈
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
// 取指
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
完成对象内存分配后,不是应该将对象的内存首地址存储到局部变量表中的对应位置吗?怎么在这里逻辑就结束了?其实new语句会被编译成好几条字节码指令,第一条是new指令,这些逻辑仅仅是new指令的内部实现,在完成new指令后,JVM接着会调用Java类的构造函数,通过构造函数才是真正返回一个完成原始构建的内部对象。而完成构造函数后,会生成一条字节码指令,将对象的内存首地址存储到局部变量表中
public void test() {
Test t = new Test();
}
Code:
stack=2, locals=2, args_size=1
0: new #2 // class Test
3: dup
4: invokespecial # 3 // Method "<init>":()v
7: astore_1
8: return
因此整个快速分配流程为(不包括逃逸分析):
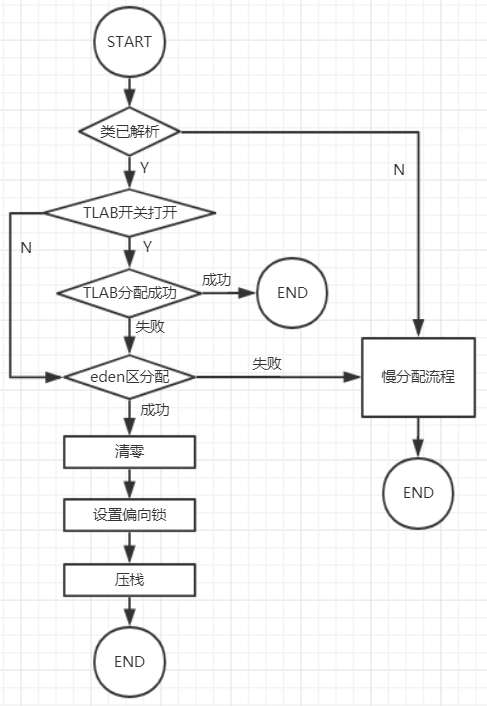 在快速分配失败后进入慢分配流程,慢分配流程也会首先尝试在TLAB中分配,失败后继续使用指针碰撞技术在新生代分配,这种分配是无锁的,效率很高。如果仍然分配失败,那么最终使用互斥锁,在堆区进行分配。期间如果遇到GC,会等待GC回收完成。总体而言,慢分配的优化手段与快速分配类似,其与GC又在理论上和代码上紧密耦合在一起
在快速分配失败后进入慢分配流程,慢分配流程也会首先尝试在TLAB中分配,失败后继续使用指针碰撞技术在新生代分配,这种分配是无锁的,效率很高。如果仍然分配失败,那么最终使用互斥锁,在堆区进行分配。期间如果遇到GC,会等待GC回收完成。总体而言,慢分配的优化手段与快速分配类似,其与GC又在理论上和代码上紧密耦合在一起
参考:
《解密JVM虚拟机》