Java基础: JVM(一) JVM概述与字节码
Java基础: JVM(二) 常量池
Java基础: JVM(三) JVM执行引擎01
Java基础: JVM(四) Java栈帧
Java基础: JVM(五) JVM执行引擎02
Java基础: JVM(六) 类变量和类方法解析
Java基础: JVM(七) 类生命周期与类加载器
Java基础: JVM(八) 热加载
Java基础: JVM(九) Java内存模型
Java基础: JVM(十) 编译相关
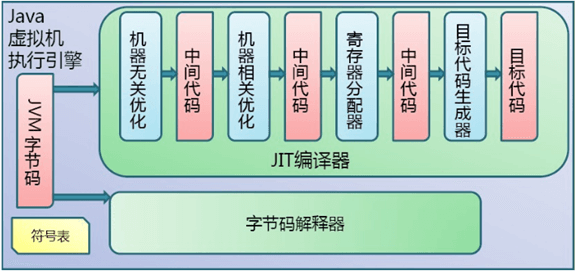
执行引擎
在JVM内部,执行引擎与GC是最精华的部分,几乎每一款JVM都在执行引擎上下足了功夫,从原始低效的字节码解释器,到模板解释器,再到JIT即时编译器,各种优化策略和理论提升了Java程序的执行速度,安卓体系中使用了AOT技术来提升运行时效率。前面的博客讨论了执行引擎是怎么进行方法调用的,那么下面讲一下JVM的取值与译码机制,还包括一些上篇提到的技术,比如栈顶缓存原理、操作数栈与栈帧重叠技术
执行引擎其实就是个运算器,能识别输入的指令,并根据输入指令执行一套特定的逻辑,最终输出特定的结构。相比于JVM,物理机器使用CPU这个执行引擎完成特定的运算。其中CPU执行命令的流程为:
1、取值:CPU从内存读取一条指令并放入指令寄存器
2、译码:指令寄存器中的指令经过译码,确定该指令应该进行什么操作(操作码决定)与操作内容(操作数决定)
3、执行:分为两个阶段,取操作数与进行运算
4、取下一条指令:修改指令计数器(或称程序计数器/PC计数器),计算下一条指令的地址,然后重新进行上述步骤
只要操作系统启动,CPU就会一直循环上述流程(取值->译码->执行->取值),如果没事可干的时候就进入”空转”状态而不会停止
JVM作为虚拟机同样也有一套类似CPU的执行机制,按这个流程循环往复地执行下去,只不过JVM运行的程序执行完后,Java程序生命周期终止,JVM虚拟机本身也会退出。而如果要保持持续”空转”,那么就需要在Java程序的某个线程中一直保持空循环,像Tomcat这款WEB应用服务器程序就是采用了这种方法,没有外部http请求过来时还能持续运行,另外比如Hadoop、Spark之类分布式系统也是类似。正因为JVM没有空转机制,因此JVM一旦启动,处理完自身的初始化逻辑后,便会进入Java程序执行字节码指令,前面的文章说过,JVM进入Java程序前,会先确定Java程序的main()主函数以及其所在的类,加载Java主类并执行其main()主函数。在JVM调用Java的main()主函数的链路上,会经过CallStub例程和zerolocals例程(entry_point),在zerolocals例程中,JVM会为Java main()主函数创建栈帧,创建完成栈帧后,最终JVM会使用__ dispatch_next(vtos)跳转到目标Java方法的第一条字节码指令,并执行其对应的机器指令,并由此进入到Java程序的世界了
取值
对于物理机器级别的取值,直接运行在物理机器上的软件程序经过编译后,直接形成二进制的物理机器指令编码,然后加载到内存。在一个基于段式内存管理的架构中,操作系统将程序加载进内存后,会将程序编译后的二进制代码指令存储到一个专门的区域 – 代码段。操作系统执行程序的过程,就是将代码段中的指令取出来逐个执行的过程。另外操作系统会将程序中的静态字段存储到数据段中,并为程序初始化堆栈空间
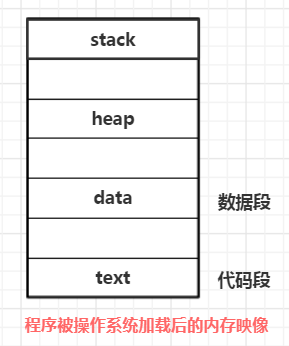
操作系统将软件程序的二进制机器指令全部读进代码段中,当操作系统开始执行该软件的时候,CPU会读取代码段中第一条机器指令,然后开始译码-执行-取值的循环流程中。CPU在取值时,先从代码段中读出操作码,在译码阶段,译码逻辑会判断该操作码,并从代码段中读取其对应的操作数。通过这个物理机器取值和译码的过程可知,物理机器要完成软件程序的运行,需要具备2个条件:
1、内存中要存储软件程序编译后的指令
2、CPU要能识别出代码段中的指令和操作数
物理机器内部的指令集表不仅仅是内存中的数据那么简单,其内置的指令集其实是硬件结构,具体说是数字电路,这些数字电路被集成进CPU内部,只要CPU传递一个指令(0与1的组合),CPU就会依据预先设定好的电路进行解码(高低电平),然后操作对应寄存器或某些电路去读取该指令操作码后面的操作数,同时另一些电路则会触发读取当前机器指令的下一条指令,如此一来就能完成取值-译码-执行-继续取值的循环了,这便是CPU识别并执行机器指令的原理
JVM基本上也继承了这个思想,作为一款虚拟机,有自己的一套指令集,这套指令集能够被JVM的虚拟机运算器所识别,因为没有真正的硬件译码电路来识别这套LVM指令,所以是使用软件模拟的,JVM使用软件的方式在内存中维护一套指令集,这套指令集是Java虚拟机执行引擎赖以运行的基础,在JVM运行期,Java字节码的译码系统完全依赖这套”软指令集”,该套指令集的定义可以在bytecodes.hpp文件中查看
指令长度
前面说过,CPU识别出操作码,并以此为依据判断操作码后面是否有操作数。CPU只有知道一个操作码后面是否跟随操作数,以及跟随操作数的大小,才能计算出下一条指令的位置,从而完成取值的功能,例如:
mov ax, 1
mov ax, 2
0xB8 01
0xB8 02
当CPU执行第一条指令时,先读取0xB8这个操作码,CPU译码电路翻译出这个操作码,并知道后面跟着一个操作数,该操作数宽度是32位,这样CPU就知道下一条指令的操作码位置了,在第一条指令操作码的位置再往前移动32位就是了,因为程序的机器码在内存中是连续存储的。于是CPU驱动其内部相关电路去内存中读出mov ax后面的操作数,同时完成这条指令后,便能接着读取下一条指令中的操作码,完成继续取值。需要注意的是,对于计算机而言,操作码和操作数在内存中都是0和1(高低电平)组成的,所以直接将一个数字给CPU是无法知道它到底是什么的,因此CPU在执行一段程序时,一定要先读取程序中的第一条指令的操作码并进行译码,计算该操作码后面是否跟随操作数以及操作数的宽度,才能计算出下一条指令的起始位置并继续读取下一条指令中的操作码
JVM也是如此,在bytecodes.cpp的initialize初始化函数中,JVM定义了每个bytecode的名字、format、字节码的返回结构result类型等。其中format这一列,记录了每一个字节码指令的总长度。比如_iconst_0这个字节码的format是b,表示只有1个操作码;bipush对应format为bc,表示跟着一个宽度为1的操作数;sipush的format为bcc,则表示后面跟随一个宽度为2的操作数。除此之外,JVM为了节省空间,将0~5的自然数专门定义了iconst_0 ~ iconst_5的6个字节码特殊指令,没有使用”操作码+操作数”的方式推送;而对于大于5的整数,就会使用bipush字节码指令了,后面跟随1个字节码宽度的操作数;当整数宽度大于1时,就会使用sipush了,即跟随2个字节宽度;对于大于2个字节的整数,则使用了ldc #N这种从常量池加载的方式,由此可见,当int整型数的宽度大于2个字节后,Java编译器会将其直接编译进字节码文件的常量池中,而常量池在被JVM加载后会保存进JVM常量区内。如果一个整数被保存进JVM常量区,当其他Java class字节码文件中也使用了同样的整数变量时,JVM不会重复写入,可以避免大数据的内存重复占用。由于存在负数,因此操作数第一位会用于标识符号,即自然数大于127使用sipush,大于32767使用ldc。回过来看ldc的format定义为bk,意为跟随宽度为1字节的操作数,如果常量池的索引号大于255,使用ldc_w指令(bkk)。这样可以看出,JVM的字节码指令集在设计上非常紧凑和简洁,JVM启动时调用Bytecodes::initialize()函数,各个字节码指令所占用的内存宽度就会被JVM所记录,JVM在运行期间执行Java程序时会不断地读取该函数所维护的表,计算每个字节码指令的长度
JVM二级取值机制
无论是CPU还是JVM软件模拟的执行引擎,其内在核心都是类似的。在Hotspot内部也存在与CPU内部类似的译码器,被称作解释器。Hotspot提供了好几种解释器,在上一篇提到过,有字节码解释器bytecodeInterpreter、默认的模板解释器templateInterpreter。所有的字节码指令都会通过TemplateInterpreterGenerator::generate_and_dispatch()这个函数来生成对应的机器指令。该函数会在JVM启动期间被调用,用于生成固定的取值逻辑。JVM会为每一个字节码指令都生成一个特定的取值逻辑,这是因为不同的字节码其指令宽度不同,因此取值逻辑也不统一。该函数主要做了两件事:
1、为Java字节码指令生成对应的汇编指令(本地机器码)
2、实现字节码指令跳转,即取值(取下一条指令)
也就是Hotspot在为每一个字节码指令生成其机器逻辑指令时,会同时为该字节码指令生成其取值逻辑。该generate_and_dispatch函数入参是Template*类型的指针,它是解释器为每个Java字节码指令所定义的汇编模板,在代码中通过调用t->generate(_masm)来生成当前字节码指令所对应的本地机器码;generate_and_dispatch函数中通过调用__dispatch_epilog(tos_out,step)这行代码生成跳转(取值)逻辑,其第二个入参step为Java字节码指令的步长(数据宽度),就是从上面说的Bytecodes里为每个字节码定义的format字段来计算。该函数在32位X86平台上的函数实现逻辑为:
void InterpreterMacroAssembler::dispatch_epilog(TosState state, int step) {
dispatch_next(state, step);
}
void InterpreterMacroAssembler::dispatch_next(TosState state, int step) {
// 加载(取)下一个字节码指令并存储到ebx寄存器中 -> movzbl 0x1(%esi),%ebx
load_unsigned_byte(rbx, Address(rsi, step));
// advance rsi,取字节码指令,是JVM模板解释器用于取值的核心 -> inc %esi / add $operand, %esi(不同字节码指令不同,所生成机器码也不同)
// 计算下一个即将执行的字节码指令的内存位置 = 当前字节码位置 + 当前字节码指令所占内存大小(单位:字节)
// rsi寄存器总是指向当前字节码指令所在的内存位置,step是步长,即可得到rsi=rsi+step计算出下一条字节码指令的内存位置
// 上一篇博文讲到的JVM调用Java的main()主函数前,先通过generate_fixed_frame(false)来创建栈帧,esi寄存器指向main()函数第一条字节码指令
// 所以要接着调用dispatch_next函数才能根据rsi进行偏移完成取值。即generate_normal_entry函数除了会调用generate_fixed_frame创建栈帧,还会调用dispatch_next执行函数的第一条字节码指令
increment(rsi, step);
// 跳转到下一条字节码所对应的本地机器码执行 -> jmp *_dispatch_table(,%ebx,state)
// 其中_dispatch_table便是JVM内部维护的跳转表,记录了每个JVM字节码所对应的本地机器码实现,JVM通过跳转表完成第二级取值逻辑
dispatch_base(state, Interpreter::dispatch_table(state));
}
在dispatch_next函数中通过三步完成二级指令取值逻辑。所谓二级指令取值逻辑,第一级是获取字节码指令,当前字节码指令执行完成后,JVM必须能自动获取到下一条字节码指令,这样才能继续循环往复执行下去;第二级取值则是取字节码指令所对应的本地机器指令,当前字节码指令对应的机器指令执行完之后,JVM必须要能跳转到下一条字节码指令所对应的机器码
t->generate(_masm)和__dispatch_epilog(tos_out,step)这两个函数会分别向JVM内部的代码缓冲区中写入对应的本地机器指令,也就是说,字节码的取值逻辑其实是被写入到每一个字节码指令所对应的本地机器码所在内存的后面区域。这是因为不同字节码指令的步长不同,因此所生成的对rsi寄存器进行累加的逻辑也不同,不同字节码指令的取值逻辑就肯定不同,所以要在后面保存下来,另外这还和栈顶缓存有关
程序计数器
JVM在执行字节码指令时,会有一个程序计数器(PC计数器/program counter)指向当前所执行的指令,当前指令执行完后,PC计数器会自动指向下一条字节码指令,程序计数器是保证软件程序能连续执行下去的关键技术之一
物理CPU中有专门的一个寄存器用于存放PC计数器,当计算机中某个软件开始运行前,操作系统将该软件程序加载到内存中(包含数据段、代码段),加载之后便会将该软件程序的第一条机器指令在内存中的地址送入程序计数器,操作系统会从该地址读取指令,并开始执行,由此开始操作系统将CPU的控制权交给软件程序。当执行指令时,处理器将自动修改PC计数器的值,每执行一条指令,PC计数器就会增加一个量,这个量等于指令所含的字节数,这样PC计数器所指向的内存位置总是将要执行的下一条指令的地址。由于大多数指令按顺序执行,因此PC计数器通常都是加1
JVM内部的程序计数器原理也是类似,是不是感觉前面讲到的某个东西和PC寄存器类似?JVM内部所谓的PC计数器其实就是esi寄存器,当JVM开始执行Java程序的main()主函数时,PC计数器(esi寄存器,X86平台)就会指向main()主函数的第一条字节码指令的内存位置,接着JVM每执行完一条字节码指令便会对PC计数器执行一定的增量,从而让PC计数器(esi寄存器)总是指向即将要执行的字节码指令,让Java程序连续执行下去
JVM使用宝贵的寄存器资源当做程序计数器,有两个原因,其一是CPU读写寄存器速度非常快,因此取值是JVM内部最频繁的事情,非常多的数据读写如果性能低下,必定会影响到JVM的整体执行效率;其二是JVM的指令集是面向栈的,而面向栈的指令集不直接依赖于寄存器,因此JVM的寄存器资源不是那么宝贵
译码
取值只是第一步,最终需要执行,不过JVM内部定义了两百多个字节码指令,不同字节码指令的实现机制都是不同的,因此JVM取出字节码指令后,需要将其翻译为不同的逻辑,然后才能执行,这就是译码的作用
模板表
对于CPU而言,译码逻辑直接固化在硬件数字电路中,当CPU读取到特定的物理机器指令时,会触发所固化的特定数字电路,这种触发机制就是译码逻辑。JVM因为没有专门的译码电路,因此只能靠软件模拟,当使用模板解释器来解释字节码时,会在TemplateTable中定义:
void TemplateTable::initialize() {
// ...
// Java spec bytecodes ubcp|disp|clvm|iswd in out generator argument
def(Bytecodes::_nop , ____|____|____|____, vtos, vtos, nop , _ );
def(Bytecodes::aconst_null, ____|____|____|____, vtos, atos, aconst_null, _ );
def(Bytecodes::iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
def(Bytecodes::iconst_0 , ____|____|____|____, vtos, itos, iconst , 0 );
def(Bytecodes::iconst_1 , ____|____|____|____, vtos, itos, iconst , 1 );
// ...
}
其中def()函数第1个入参是字节码指令编码,而第8个入参是该指令所对应的汇编指令生成器,这种生成器在JVM内部称为generate。对于模板解释器,JVM为每一个字节码都专门配备了一个生成器,也就是一个函数。例如将int型局部变量从局部变量表推送至操作数栈栈顶,JVM设计了多种iload字节码指令系列,比如iload_0,iload_1等,这些字节码指令所对应的generate都是iload()函数,这个函数是与CPU平台架构相关的,并且在templateTable.hpp中定义了2个重载函数:
// iload 6、iload 10之类的使用这个,会使用iload slot_idx字节码指令
static void iload();
// iload 0、iload_1之类的使用这个,在slot索引号0~3的有专门iload_0、iload_3这样只占1字节内存空间的字节码指令
static void iload(int n);
那么在TemplateTable的初始化中,def()函数定义了每一个字节码指令的机器码指令生成器函数,函数中会取出当前定义的字节码指令模板,然后使用t->initialize(flags,in,out,gen,arg)对字节码指令模板进行初始化,再将初始化好的字节码指令模板保存到模板表中,即TemplateTable类定义的_template_table数组,其中记录了每个字节码指令的汇编生成器(即对应函数)、参数、其他相关信息。这个数组的元素类型是Template,初始化大小为Bytecodes::number_of_code,即Java字节码指令数量。TemplateTable类定义了模板表的访问接口,这样就可以通过字节码指令的编号查询对应函数,def()函数会通过这个接口读取字节码指令在模板表中对应的模板。无论是模板表还是访问接口都是static的,因此操作系统加载TemplateTable类时就完成初始化,只不过那时候模板表中的元素都是空值,模板尚未构建,只有当def()函数从模板表取出当前模板后,进行初始化,这样在TemplateTable::initialize完成后,字节码指令的模板便完成构建
既然模板表是在运行期Java字节码指令时时刻刻都会用到的基础数据,因此在JVM启动期间完成构建:
// 由操作系统调用
java.c: main()
// 调用LoadJavaVM(),里面调用JNI_CreateJavaVM()创建JVM虚拟机,不过会有两个地方调用JNI_CreateJavaVM()
// 会在这里面判断是否通过gamma启动器启动
// 为了调试跟踪方便,Hotspot提供了gamma启动器,能直接在本地调试Hotspot源代码,通过GAMMA宏判断
// 而正常启动是调用%JAVA_HOME%\bin\java脚本启动,加载动态链接库进行调用,这由C编写,逻辑与gamma启动器基本一样,都使用同一套launcher源码
java_md.c: LoadJavaVM()
// 调用ifn->CreateJavaVM = (CreateJavaVM_t)dlsym(libjvm, "JNI_CreateJavaVM")
jni.cpp: _JNI_IMPORT_OR_EXPORT_ jint JNICALL JNI_CreateJavaVM()
// 调用result = Threads::create_vm((JavaVMInitArgs)args, &can_try_again),执行一系列的虚拟机初始化逻辑
thread.cpp:Thread::create_vm()
init.cpp: init_globals()
// JVM是基于解释的虚拟机,因此需要对解释器进行初始化
interpreter.cpp: interpreter_init()
// 通过宏判断哪个解释器,默认为模板解释器
// 主要初始化了抽象解释器AbstractInterpreter、模板表TemplateTable、CodeCache的Stub队列StubQueue、解释器生成器InterpreterGenerator
templateInterpreter.cpp: TemplateInterpreter::initialize()
templateTable.cpp: TemplateTable::initialize()
汇编器
对于模板解释器,每一个字节码指令都会关联一个生成器函数,用于生成字节码指令的本地机器码。例如iload_1字节码指令对应的函数是TemplateTable::iload(int n),在该函数中主要调用__ movl(rax, iaddress(n))函数生成对应的机器指令,所生成的机器指令是mov reg, operand,表示将操作数传送至指定的寄存器中,在X86平台上的函数调用接口为:
void Assembler::movl(Register dst, Address src) {
InstructionMark im(this);
prefix(src, dst);
// emit系列接口生成本地机器码,将机器码写入特定的内存位置,JVM在运行期解释字节码指令时,跳转到特定内存位置执行机器码
emit_byte(0x8B);
imit_operand(dst, src);
}
该函数属于Assembler类,该类是JVM内部为模板解释器所定义的汇编器,当JVM使用模板解释器来解释执行字节码指令时,便会通过汇编器来为每一个字节码指令生成对应的本地机器码。因此每一个字节码指令都关联一个生成器函数,而生成器函数会调用汇编器生成机器代码。而使用__ movl(rax, iaddress(n))函数就能调用到这个方法,是因为__是一个宏,在模板表中可以通过添加__前缀直接调用汇编器中的函数,而不用添加类名:
#ifndef CC_INTERP
#define __ _masm->
// ...
#endif
__ movl(rax, iaddress(n))
// 在Hotspot源码编译的预处理阶段,被宏替换为
_masm->movl(rax, iaddress(n))
class TemplateTable: AllStatic {
public:
// ...
// 类型是静态的,在JVM启动期间,JVM调用字节码指令所对应的生成器函数时会对其进行赋值
// 前面讲过JVM为所有字节码指令生成取值逻辑,TemplateInterpreterGenerator::generate_and_dispatch来生成取值逻辑
// 会先调用t->generate(_masm)函数为当前字节码指令生成本地机器码,然后调用__dispatch_epilog取值,在调用t->generate(_masm)时就传入了一个_masm指针
// 这个指针也是汇编器,模板表的静态变量_masm便是在JVM调用t->generate(_masm)时进行了赋值
static InterpreterMacroAssembler* _masm; // 汇编器
}
void Template::generate(InterpreterMacroAssembler* masm) {
// parameter passing
TemplateTable::_desc = this;
// 初始化,传递进模板表内部
TemplateTable::_masm = masm;
// code generation,是各个字节码指令所对应的本地机器码生成函数,这些生成函数都是TemplateTable类的静态函数
// 因此JVM调用这些函数时,这些生成器函数会调用汇编器的接口生成本地机器码,而汇编器便是这个入参masm
_gen(_arg);
masm->flush();
}
以iload_1字节码指令为例,从头看一下流程:
1、JVM启动期间,调动TemplateTable类的initialize()将每一个字节码指令与其生成器函数进行关联
1-1、例如iload_1通过TemplateTable::def()方法,关联的_gen生成器映射为TemplateTable::iload(int n),这个阶段该函数并不会被调用
2、JVM启动期间,通过模板解释器TemplateInterpreterGenerator::generate_and_dispatch()生成本地机器码和取值
2-1、函数内通过调用t->generate(_masm)为每个字节码指令生成对应的本地机器码,模板表TemplateTable::_masm静态变量在这里完成了初始化
2-1-1、函数内通过调用_gen(_arg)为字节码指令生成本地机器码,iload_1指令对应的_gen是TemplateTable::iload(int n)函数,内部调用__ movl(rax, iaddress(n))生成本地机器码,这个宏在预处理阶段被替换成_masm->,即实际调用为TemplateTable::_masm->movl(rax, iaddress(n))
2-2、为该字节码生成对应的取值的本地机器码,即取下一条字节码指令
TemplateInterpreterGenerator::generate_and_dispatch()函数的调用链路为:
// ...
init.cpp: init_globals()
interpreter.cpp: interpreter_init()
templateInterpreter.cpp: TemplateInterpreter::initialize()
// 初始化模板表
templateTable.cpp: TemplateTable::initialize()
// 解释器生成构造函数
InterpreterGenerator(_code)
TemplateInterpreterGenerator::generate_all()
// 遍历所有字节码指令,然后调用set_entry_points()为每个字节码指令设置入口点
TemplateInterpreterGenerator::set_entry_points_for_all_bytes()
// 实例化了一个CodeletMark类对象,实例化时传递了指针变量_masm,是TemplateInterpreterGenerator从抽象解释器生成器AbstractInterpreterGenerator中继承来的私有成员变量,指针指向汇编器的内存首地址
// CodeletMark会在构造函数中实例化一个汇编器,并将外部传入的汇编器指针指向这个创建的汇编器实例对象
TemplateInterpreterGenerator::set_entry_points()
TemplateInterpreterGenerator::set_short_entry_points()
// 这里会将_masm通过t->generate(_masm)传递给TemplateTable
TemplateInterpreterGenerator::generate_and_dispatch()
汇编器在Hotspot内部包含4个继承层次:
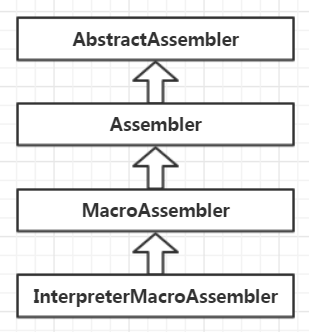 在顶层汇编器AbstractAssembler中定义了最核心的功能和数据结构:
在顶层汇编器AbstractAssembler中定义了最核心的功能和数据结构:
class AbstractAssembler : public ResourceObj {
protected:
address _code_begin; // 指令缓存区首地址
address _code_pos; // 写入的当前位置
// ...
void emit_byte(int x); // 往指令区写入一个字节数据/指令
void emit_word(int x); // 往指令区写入一个16位数据
void emit_long(jint x); // 往指令区写入一个32位数据
void emit_address(address x); // 往指令区写入一个地址数据
// ...
}
每一个汇编器都会往内存写入一段指令,因此JVM会为每个汇编器分配一个内存首地址,汇编器就从该首地址开始写入指令或数据。因此在抽象汇编器中定义了_code_begin和_code_pos等字段,用于记录首地址及当前写入的位置。同时还提供了写入本地机器指令的接口,即emit()系列函数。抽象汇编器的子类都依赖于这些核心功能生成机器执行,其继承层次越深,处理的业务越抽象复杂,也与Java的字节码指令越接近,同时除了抽象汇编器外,其他子类都与硬件平台相关
在AbstractAssembler层的顶层汇编器提供了往缓冲区写入本地机器码指令和数据的接口,并记录写入的起始位置和当前地址。位于集成体系第二层的Assembler汇编器是对物理机器指令的抽象,或软件封装,比如dec、inc、lea、mov、push、pop等接口,这些接口都是对物理机器指令的”纯净”模拟,最终生成出来的机器码与原生的机器指令是完全一致的。位于汇编器继承体系的第三层就是MacroAssembler汇编器,虽然仍然基于机器硬件指令抽象,当已不是”纯净”的抽象和模拟了,很多指令能直接为Java数据所用,它有mov、add等物理机器级别的接口,也延伸出movbool、addptr等物理机器不支持的指令,在其内部生成了多条机器指令去处理,因此MacroAssembler可以看做是物理机器指令的组合封装,同时能够支持Java内部数据对象级别的机器指令原语操作。在汇编器继承体系最下一层的就是InterpreterMacroAssembler汇编器,这个是解释器级别的汇编器,直接为解释器提供相关汇编接口,主要分为获取运行时参数相关的指令、操作数栈相关的指令、取值相关的指令、性能监控的指令等。由于Hotspot是基于栈式指令集的虚拟机,因此有不同类型的数据压栈指令包括push_ptr()、push_i()、push_l()等,同时还有以dispatch为前缀的取值指令。JVM内部在调用方法之前会创建栈帧,在的动态绑定时会进行运行期链接,这些操作都需要解释器能在运行期读取各种参数,例如Java方法在JVM内部对应的method对象实例、Java class字节码文件常量池在JVM内存中的映像、字节码对应的入口缓存等,因此提供了get_method()、get_constant_pool()等接口,这些核心接口支撑起了JVM内部解释器的运行期的各种调用,使解释器能站在JVM虚拟机这个层面看待问题,而不仅仅局限于物理机器指令的各种原子化琐碎指令逻辑上。这本质上也是一种面向对象的抽象思维模式,一层层地抽象,抽象通过软件函数的封装得以体现,函数所封装的不仅仅是函数,是能力。从机器到汇编、从汇编到B语言、C语言、到C++、Java,一路抽象一路封装,汇编是机器指令的简单符号代替,C语言的一个接口封装了无数汇编能力,一个Java接口也封装了若干C和机器指令的特性。不仅编程语言,网络架构、分布式集群、中间件等无一不是肿种特性的抽象和封装,这个角度看过去也是系统要分成的原因了
栈顶缓存
Hotspot提供了HSDIS工具,可以打印模板解释器为各个字节码指令所生成的本地机器码,可以验证实际生成的机器码与源码中是否一致。比如iload_1指令,模板解释器为该字节码指令生成的机器码与HSDIS生成的指令并不一样,实际上多了许多,这个与优化有关,便是栈顶缓存。JVM的栈顶缓存,是通过寄存器来暂存的,由于CPU无法同时兼顾时间和空间,而JVM追求性能,因此模板解释器在执行操作数栈操作时,并没有将数据直接压入栈顶,而是优先将数据传送到寄存器,在后续流程CPU执行运算时,就无须将数据再从栈顶传送到寄存器,节省了一次内存读写,从而提升了JVM的运算指令执行效率,这就是栈顶缓存
由于寄存器是稀缺资源,因此JVM并不是每次都能将数据存到寄存器,所以在将数据存进寄存器前,需要判断寄存器是否有数据,如果有数据则需要先将数据移走,才能将当前操作数移存进去。而Java内建的数据类型非常丰富,因此栈顶缓存的数据也有各种类型,JVM在将这些数据移走时必须考虑真实的数据类型,在对待不同类型数据时的处理逻辑也是不同的,所以JVM在解释一个字节码指令时,需要包含处理栈顶不同类型数据的逻辑,就会比iload_1字节码指令本身的本地机器码多很多的原因
栈式指令集
Java的字节码指令都是面向栈的,面向栈的指令集有一个特点:不需要指定操作数,即“零地址”指令。例如一般做x = y + z的加法,有些CPU使用add x, y, z的机器指令,即op dest, src1, src2的“三地址”指令;有的CPU认为可以优化为y += z的方式,因此采用op dest, src的方式,即“二地址”指令。无论是二元还是三元地址指令集大多直接面向寄存器,CPU读取寄存器的性能要远远高于内存,因此能直接基于寄存器运算的指令,不需要设计成面向栈式操作,但是寄存器式指令集一般与硬件平台相关,因为不同硬件平台集成的寄存器数量、内部标识、指令格式都不相同,而栈式指令则可以跨平台的。所以JVM设计为跨平台,其指令集也采用了零地址的格式,而零地址又只能基于栈的架构,所以JVM的执行引擎也只能围绕栈来实现,前面说到的栈顶缓存就是针对堆栈进行的一项优化措施,其优化思路还是优先使用寄存器
栈式指令既然是零地址格式,因此操作的源数据和目的数据都会位于栈顶,既然操作数位于栈顶,那么操作前必然会有指令将数据先传送到栈顶,所以只要一条指令就能实现的逻辑,现在就需要多条指令才能实现,比如在iadd求和之前,需要有iload/iconst/bipush等将数据推送至栈顶的前置指令。由于JVM在启动阶段会将所有字节码指令生成本地机器码指令,而本地机器码指令都是基于寄存器的,因此这么看JVM的栈式指令集只能算是”伪指令”
由于JVM性能较低,因此有了各种优化手段来提升性能。比如从最初的字节码解释器(C语言函数逻辑解释执行字节码)升级到了模板解释器(直接生成本地机器码),接着又加入JIT编译器,能在运行期针对热点代码进行及时编译,采用了多种优化策略使编译出来的代码更高效,Hotspot还针对客户端和服务端开发了C1和C2两层编译优化功能,它们都属于动态自适应编译器,C1仅做简单优化,C2会做深层次优化,编译出来的代码质量高,但是编译时间较长。除此之外Hotspot还使用了一些内存分配、并发控制方面的优化技术,比较突出的是“逃逸分析”,即一个Java对象被定义后,可能被外部方法引用,如果作为入参传递到其他方法,则称为方法逃逸,如果被其他线程访问,则称为线程逃逸,如果确认一个Java类不会逃逸到其他方法且结构简单(可直接拆分成标量,即原始基本类型)时,则可直接进行栈上分配,即直接将Java对象实例分配在当前线程的堆栈中,非堆内存,这样就不需要通过GC来回收实例,会跟随方法栈被一起回收,这种优化策略的专门术语叫“标量替换”;又如果能证明一个Java对象不会逃逸到其他线程,则不会出现多线程竞争,方法上的同步措施便会消除,消除同步锁后代码执行效率会更高
安卓在4以前的版本,使用Dalvik虚拟机来解释执行安卓字节码文件,虽然和Hotspot都是虚拟机,但是安卓只针对ARM系列处理器,并没有考虑跨平台,ARM处理器由16个32位通用寄存器,因此Dalvik设计了16个虚拟寄存器,在运行期将虚拟寄存器映射到物理寄存器,达到高效执行的目的。但是之后又出现了AOT技术,即提前编译,或叫静态编译,这种技术是相对JIT而言的。AOT是在Java程序运行之前就提前编译好,直接编译成本地相关的机器指令。而对于JVM如果纯粹使用解释器解释执行,每次执行一个方法都需要将字节码指令翻译为对应的机器指令,如果一个方法调用好几次,则这种工作就被重复做几次,如果开启了JIT,每次Java程序重启后运行,也都要进行一次编译工作**。AOT的思想则是在编译阶段就将工作做完,直接将Java程序翻译为对应本地机器指令,这样就不用在运行期重复做这些事情了,因此AOT的出现使安卓在5以后抛弃了Dalvik虚拟机,使用了ART虚拟机,ART其实就是AOP的运行时环境,专门负责运行AOT后的指令
操作数栈
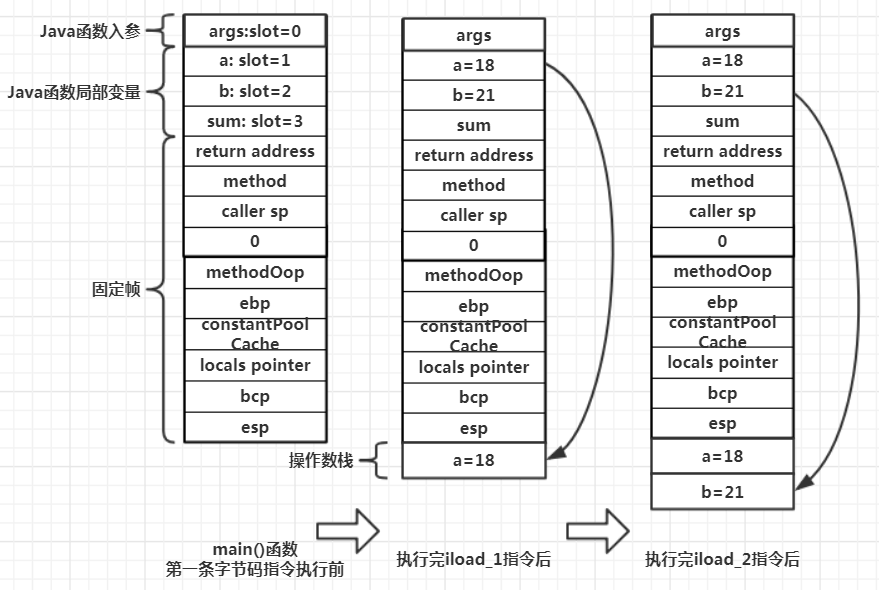
面向栈的零地址指令,其源数据和目的数据存在栈中,但是这个栈在哪里呢?JVM内部有一个求值栈,也叫作操作数栈或表达式栈,上一篇栈帧中说到,一个栈帧的三大部分:局部变量表、固定帧和操作数栈,它们依次按内存从高位向地位顺序增长,JVM开始执行Java方法的第一条字节码指令之前,操作数栈其实并没有被创建,仅仅执行到创建Java方法栈帧的最后一步 – 将当前线程栈栈顶位置压入当前栈顶位置,即将esp指针的位置(栈顶)存入,操作数栈就是从这个位置开始,因此JVM内部称为”expression stack bottom”表达式栈底,至此JVM就准备好了一切,等待执行指令,当有iload_1指令时,就会被翻译为本地机器指令push %eax,将Java方法栈的局部变量表中slot索引号为1的局部变量压入栈顶 – 从操作数栈底开始压入
public static void main(String[] args) {
int a = 18;
int b = 21;
int sum = a + b;
}
stack=2, locals=4, args_size=1
0: bipush 18 // 将18压栈
2: istore_1 // 弹出后传到局部变量表slot 1
3: bipush 21 // 将21压倒栈顶
5: istore_2 // 弹出到slot 2
6: iload_1 // 压栈slot 1
7: iload_2 // 压栈slot 2
8: iadd // 求和后,会将两个数出栈,栈顶只保存求和结果
9: istore_3 // 弹出到slot 3(局部变量表)
10: return // 返回
忽略栈顶缓存技术,因为实际上会将局部变量传送到寄存器中
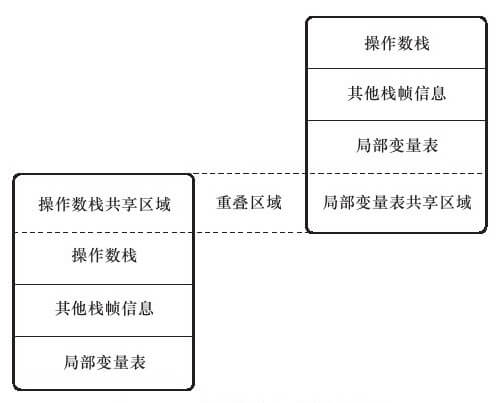
栈帧重叠
无论JVM指令集是基于栈还是基于寄存器,方法调用所基于的数据结构都是堆栈。JVM在准备调用一个Java方法之前,会先为其创建栈帧,随后执行引擎对字节码的执行,JVM会动态读写Java方法的操作数栈。在概念模型中,两个直接调用关系的Java方法的栈帧在堆栈空间上是线性顺序串联的,并且彼此有完成的栈帧结构,而大多数虚拟机会进行一些优化,其中一项成熟的技术就是栈帧重叠,它使两个相邻的栈帧出现一部分重叠,让前一个栈帧的操作数栈与后一个栈帧的局部变量表区域部分重叠在一起,这样在进行方法调用时能共用这部分堆栈空间,无需进行额外的参数复制
工具相关
HSDIS:
How to build hsdis-amd64.dll and hsdis-i386.dll on Windows
我本地用的是jdk8U77-b03,只在Makefile里多加了$(TARGET_DIR)/zlib/libz.a。然后用binutils-2.30最后会出错,我用binutils-2.27是没问题的,命令为make OS=Linux MINGW=x86_64-w64-mingw32 'AR=$(MINGW)-ar' BINUTILS=~/binutils-2.27
,生成的hsdis-amd64.dll文件放到JAVA_HOME/jre/bin下就可以了,例如使用命令java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly Test查看输出,或者java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=dontinline,*Test.add -XX:CompileComm
and=compileonly,*Test.add Test输出add相关
OpenJDK在线查看源码:
(OpenJDK-projects)[http://hg.openjdk.java.net/]
OpenJDK 8下载:
OpenJDK™ Source Releases
参考:
《解密JVM虚拟机》
扩展:
Java之深入JVM(6) - 字节码执行引擎(转)
JIT编译器